ZooKeeper
Mar 14, 2022 22:30 · 4941 words · 10 minute read

来自 ZooKeeper: Wait-free coordination for Internet-scale systems
ZooKeeper 在一个多副本的集中式服务中整合了群组消息、共享寄存器和分布式锁服务。
It incorporates elements from group messaging, shared registers, and distributed lock services in a replicated, centralized service.
1 介绍
大规模分布式应用程序需要的协调形式:
- 配置 configuration
- 组成员 group membership
- 选举 leader election
- 锁 locks
在设计 ZooKeeper 时:
- 放弃在服务器端实现特定的原语,选择暴露 API 来让开发者实现他们自己的原语。
- 放弃阻塞原语(锁),因为可能拖慢客户端。ZooKeeper 实现了一个 API,可以像文件系统那样操作分层的 wait-free 对象。
- 为操作提供顺序保证
- 为任意数量的进程实现共识
ZooKeeper 基于多副本实现高可用和高性能。
采用流水线架构实现,以 FIFO 顺序从单个客户端执行操作,保证客户端异步提交操作。
为了保证线性更新,ZooKeeper 实现了 ZAB 协议。
在客户端缓存数据可以提升读性能,例如进程缓存当前 leader 的 ID 而不是每次都去询问 ZooKeeper。ZooKeeper 使用 watch 机制在客户端缓存数据而非直接管理客户端缓存。通过 watch 机制,客户端能够监听到一个已知对象的更新。Chubby 直接管理客户端缓存,它会在数据变更后使所有客户端的缓存失效。这种设计下,如果客户端中任一运行缓慢或出错,更新就会延迟。Chubby 使用租约来防止系统永久被阻塞。然而租约只是限制了缓慢或故障的客户端的影响,而 ZooKeeper watch 完全避免了这个问题。
2 ZooKeeper 服务
2.1 概述
ZooKeeper 为客户端提供一组数据节点(znode)的抽象,根据分层的名称空间组织。分层的名称空间常被文件系统使用。这是一种组织数据对象的理想方式,因为用户已经习惯于这种抽象并且可以更好地组织应用程序元数据。例如,使用 /A/B/C 来表示 znode C 的路径,B 是 C 的父目录,A 是 B 的父目录。所有 znode 都存储数据;除了临时的 znode,都有 children。
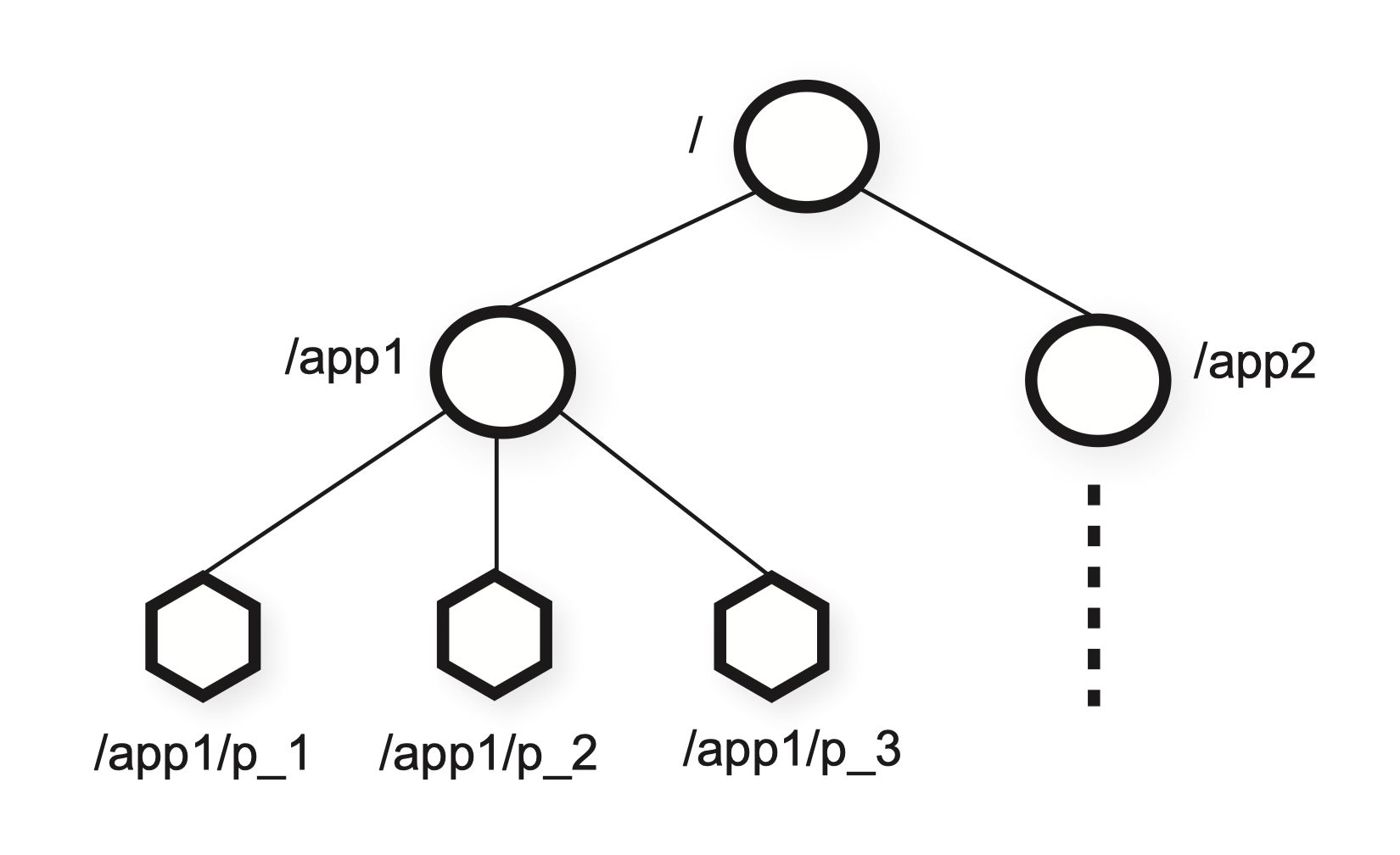
客户端可以创建两种类型的 znode:
-
Regular 常规型
客户端显式地创建和删除常规型 znode
-
Ephemeral 临时型
客户端同样可以显式地创建和删除,或者在会话结束后由系统自动移除
另外创建 znode 时客户端可以设置一个序列(sequential)标记。
ZooKeeper 实现了 watch 机制使得客户端无需轮询就能实时地接收变通知。当客户端用 watch 标记发布一个读操作,操作如常完成而且服务器承诺在返回的信息发生变更时会通知客户端。
-
数据模型(Data model)
-
ZooKeeper 的数据模型本质性就是个简化 API 的文件系统。分层的命名空间对于为不同应用程序的命名空间分配子树以及设置访问权限很有用。
-
相比文件,znode 并不是为通用数据存储设计的。相反,znode 映射至客户端的抽象,通常对应用于协调目的的元数据。
-
ZooKeeper 也允许客户端在 znode 中存储数据用于元数据或分布式计算的配置。
例如,当前 leader 在一个众所周知的 znode 空间中记录一些信息,其他服务器就知道谁是 leader 了。
-
-
会话(Session)
- 客户端连接 ZooKeeper 形成会话,有超时时间。
- 会话使客户端能够从 ZooKeeper 集群中的一台服务器透明地移动到另一台服务器。
2.2 客户端 API
create(path, data, flags)delete(path, version)exists(path, watch)getData(path, watch)setData(path, data, version)getChildren(path, watch)sync(path)
所有的方法都有同步异步两个版本:
- 执行单个 ZooKeeper 操作而且没有并发任务,调用同步 API 并阻塞
- 应用程序并行执行大量 ZooKeeper 操作和任务,调用异步 API
ZooKeeper 客户端确保每个操作的回调会按序触发。
注意所有的请求都包含了被操作的 znode 完整路径,这种选择不仅简化了 API,也消除了服务器需要维护的额外状态。
每个更新方法带上一个预期的版本号,这实现了条件更新:如果 znode 实际的版本号匹配不上期望的版本号,就会更新失败,抛出一个 unexpected version 错误。
2.3 保障
ZooKeeper 有两种基本顺序的保障:
-
线性写(Linearizable writes)
所有更新 ZooKeeper 状态的请求都是串行的并且遵循优先级
-
FIFO 客户端顺序(FIFO client order)
既定客户端的所有请求都按客户端发送的顺序执行
ZooKeeper 定义的线性不同于 Herlihy 提出的原型,称为异步线性(A-linearizability)。Herlihy 定义的线性中,客户端一次只能进行一项操作(客户端也是一条线程);而 ZooKeeper 允许客户端有多个操作,因此要么没有特定顺序要么保证 FIFI 顺序。ZooKeeper 选择后者。重要的是要观察到所有适用于线性化对象的结果同样也适用于异步线性化对象,因为满足异步线性的系统也满足线性。只有更新请求是异步线性的,ZooKeeper 在每个副本都会处理读请求。
举个例子,一个多进程的系统选举出一个 leader 来管理工作进程,当新的 leader 接管系统,必然会修改大量的配置参数并在完成变更后通知其他进程。这就有了两个需求:
- 新的 leader 开始变更时,我们不想要其他进程已经开始使用这些配置。
- 如果在配置完全更新好之前新的 leader 挂了,我们也不想要其他进程用这部分配置。
像 Chubby 提供的锁,满足第一个需求但对第二个无能为力。通过 ZooKeeper,新的 leader 可以指定一个路径为 ready znode;其他进程只有在 znode 存在时才能使用配置。新的 leader 删掉 ready 来变更配置,更新配置 znode 然后创建 ready znode。以上所有操作都可以流水化并异步发布。假设变更操作要 2ms,新的 leader 同步更新 5000 个不同的 znode 要花 10s;而异步发布请求 1s 都不到。
以上的模式有些问题:
-
万一某个进程在新的 leader 开始变更前就已经看到 ready。
这个问题通过保证通知的顺序来解决:要是客户端在 watch 变更,在看到集群的新状态前首先会收到通知。
-
客户端除 ZooKeeper 外还有其他的通信渠道会导致另一个问题:
A B 两个客户端在 ZooKeeper 中有共享的配置,如果 A 修改了共享配置然后通过共享的通信渠道将变更告知 B,B 就会重载配置文件。如果 B 的 ZooKeeper 副本稍微落后于 A,那可能就看不到新的配置了。利用 ZooKeeper 的保障 B 可以通过在重载配置前先发布一条写操作来保证看到最新的信息。ZooKeeper 另外提供了
sync请求来应对这种情况。
ZooKeeper 还有两道保障:
- 大多数 ZooKeeper 服务器存活那么就可以提供服务
- 如果 ZooKeeper 服务器成功应答一条修改请求,只要法定票数(quorum)数量的服务器最终能恢复那么变更就有效。
2.4 原语用例
如何使用 ZooKeeper API 实现更强大的原语。
-
配置管理(Configuration Management)
配置被存在 znode 中,进程启动时通过完整的路径读取 zc,并将 watch 标记设置为 true。zc 中的配置一旦被更新,进程就会被通知去重读新的配置。
-
Rendezvous
有时候在分布式系统中,最终的系统配置形态可能不是很明确。例如客户端启动一个主进程(master)和一些工作进程(worker),但是进程是由一个调度器来启动的,因此客户端不会提前知道地址和端口等信息来给到工作进程去连接主进程。我们通过一个 rendezvous znode zr 来处理这种场景,由客户端创建。客户端将 zr 的完整路径作为主进程和工作进程的启动参数。当主进程启动后就会将地址和端口等信息填入 zr,工作进程启动后读取 zr 并将 watch 标记设置为 true。
-
组成员(Group Membership)
利用临时节点来实现组成员。首先指定一个 znode zg 来代表组。当该组的一个进程成员启动,会在 zg 下面创建一个临时 znode,还可以存一些进程信息。如果进程结束,代表它的 znode 会被自动移除。
-
简单锁(Simple Locks)
最简单的锁实现使用“锁文件”。锁用一个 znode 表示。客户端要持锁的话,就尝试去创建一个临时的 znode。如果创建成功,客户端就拿到了锁;否则客户端 watch znode,如果当前 leader 挂了就会收到通知。客户端挂掉会释放锁,或者主动删除 znode。其他客户端观察到 znode 被删除就会去获取锁。
但这种简单的锁协议有点问题:
- 惊群效应:如果有很多客户端等待获取锁,当锁被释放,它们就会竞争,因为只有一个客户端可以获取锁。
- 只实现了独占锁
-
没有惊群效应的简单锁(Simple Locks without Herd Effect)
把所有的请求锁的客户端排成一对,每个客户端按照请求到达的顺序获取锁。
-
Lock
- n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
- C = getChildren(l, false)
- if n is lowest znode in C, exit
- p = znode in C ordered just before n
- if exists(p, true) wait for watch event
- goto 2
-
Unlock
1 delete(n)
这种锁模式的优点:
- znode 的移除只会唤醒一个客户端
- 没有轮询和超时
-
-
读写锁(Read/Write Locks)
分成读锁和写锁过程。
-
Write Lock
- n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
- C = getChildren(l, false)
- if n is lowest znode in C, exit
- p = znode in C ordered just before n
- if exists(p, true) wait for event
- goto 2
-
Read Lock
- n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
- C = getChildren(l, false)
- if no write znodes lower than n in C, exit
- p = write znode in C ordered just before n
- if exists(p, true) wait for event
- goto 3
-
3 ZooKeeper 应用程序
-
爬虫服务(The Fetching Service)
爬虫服务有主进程管理页面抓取进程,为它们提供配置,并且抓取进程回写来通报它们的状态。为 FS 使用 ZooKeeper 的主要优势在于主进程从故障中恢复,即使发生故障也能保证可用,并将客户端与服务端解耦,从 ZooKeeper 读取服务器状态并把请求打向健康的服务器
-
Katta
Katta 是主从架构的分布式索引,使用 ZooKeeper 追踪主从服务器的状态(成员组),还有处理主节点故障切换(选主)
-
Yahoo! Message Broker
YMB 是一个分布式发布-订阅系统,管理成千上万个主题(topic),客户端通过它们发布或接收消息。YMB 使用 ZooKeeper 管理主题的分布(配置元数据),处理系统中的机器故障(故障探测和组成员)。
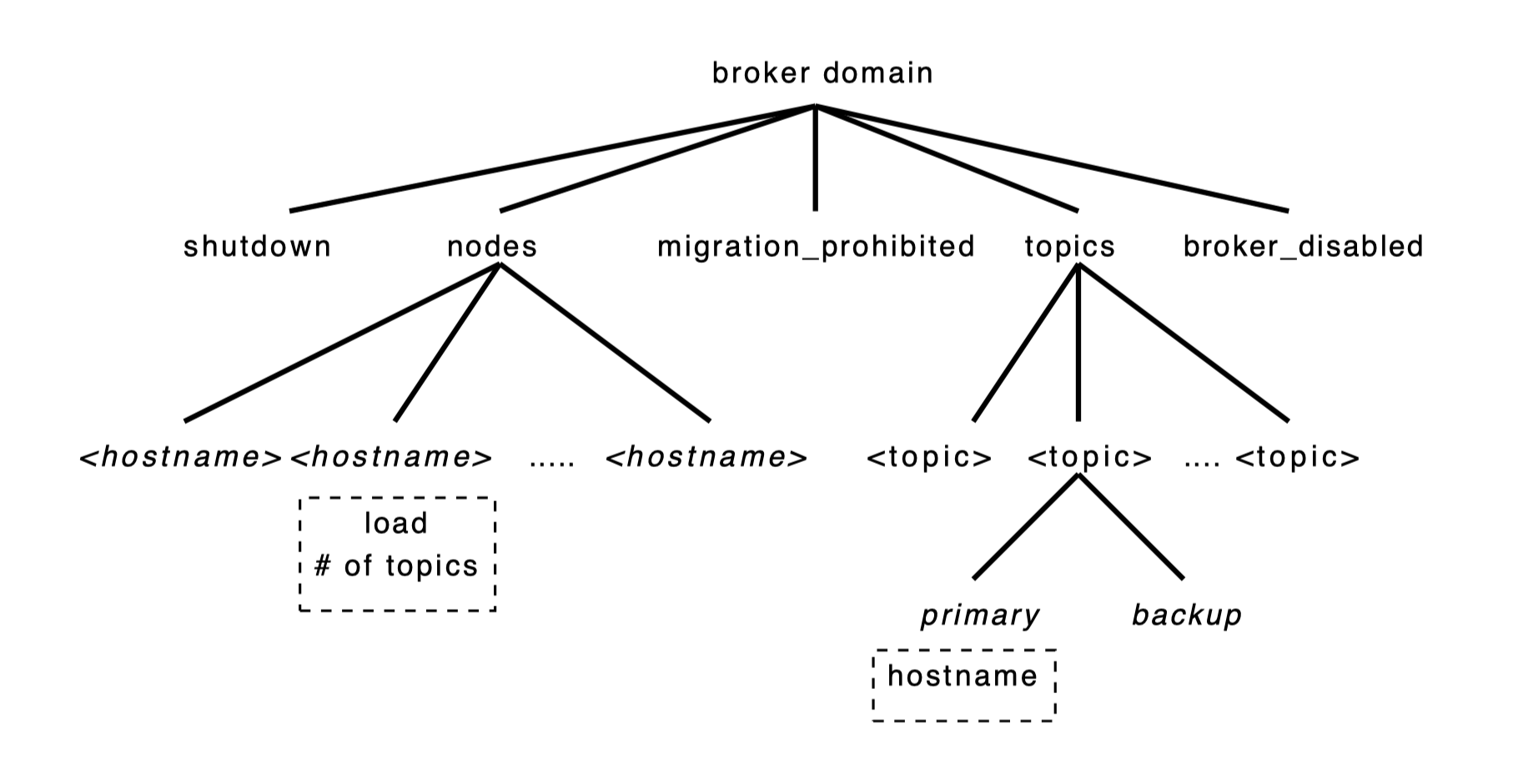
- 每个 broker domain 都有一个叫做 nodes 的 znode,YMB 服务每台活着的服务器都会在它下面创建一个临时 znode,存储负载和状态信息。
- shutdown 和 migration prohibited 这类 znode 被所有服务器监控
- 每个话题在 topics znode 下都有一个对应的 child znode,为订阅者指示每个话题的主备服务器,同时也管理选主。
4 实现
ZooKeeper 通过多副本提供服务的高可用。
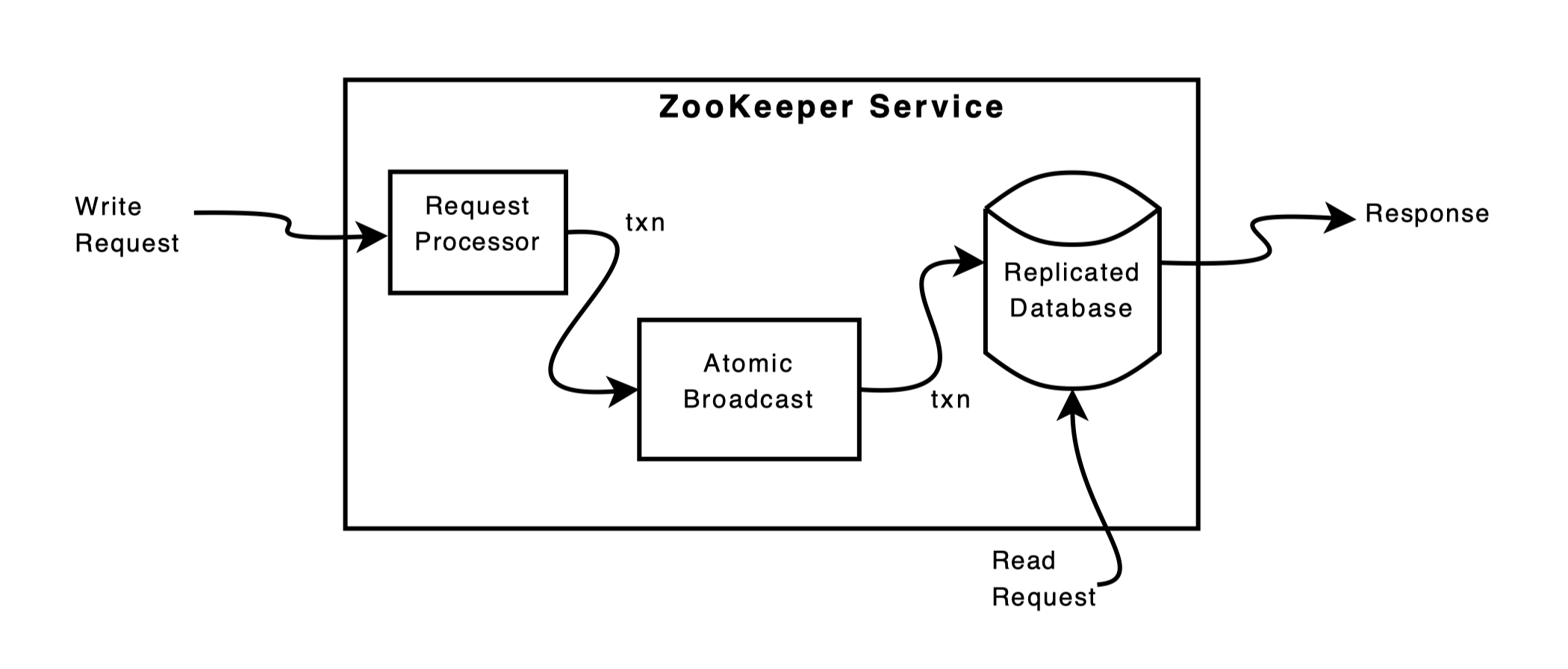
我们假设服务器挂了,而且要过一会才能恢复。
- 接收到一条请求后,一台服务器准备执行。服务器收到读请求只要读取本地的数据库并应答就行了。
- 如果这条请求(写请求)需要多台服务器协同工作,它们会使用一套共识协议(原子广播的一种实现)
- 在变更完全落地到所有服务器上后,最后将变更提交至 ZooKeeper 数据库。
多副本的数据库是一个内存数据库,包含了整个数据树结构。因为考虑到恢复,更新日志在被应用至内存数据库前要被高效记录到磁盘上。实际上,类似 Chubby,ZooKeeper 保存了一份已提交操作的回放日志(replay log)并周期性地在内存数据库中创建快照。
ZooKeeper 集群的每个节点都可以处理读请求,而写请求会被发送到 leader 节点,followers 节点将收到 leader 的提议消息并同意状态修改。
4.1 请求处理器
当 leader 收到写请求,它会计算变更后的系统状态,将其转换为事务。为什么必须计算出未来的状态,是因为 MVCC。
4.2 原子广播(ZAB)
ZAB 基于 quorum 机制,所以只有大多数服务器没问题时 ZooKeeper 才能工作(2f + 1 个服务器能够容忍 f 个服务器故障)。
为了实现高吞吐量,ZooKeeper 试图保持请求处理流水线满载。因为状态变更依赖于对之前的状态变化的应用,Zab 提供了相比常规原子广播更强的顺序保证。具体来说,Zab 保证 leader 广播变更按序传递。
简化实现并极大地提升性能的一些细节:
- 使用 TCP 来维护消息顺序
- 使用 Zab 选主
- 为内存数据库使用 WAL 日志来追踪提议,避免写盘两次(日志和数据库)
因为不持久化已传递的消息 id,在恢复期间 Zab 可能会重传消息。实际上 ZooKeeper 会重新发送所有上个快照点后的消息。
4.3 复制式数据库
每个副本在内存中都有一份完整的 ZooKeeper 状态数据。当服务器从崩溃中恢复,重放所有已传递的消息来恢复状态会花费相当长的时间,ZooKeeper 会定期保存快照,这样就只要重传快照点后的消息。
ZooKeeper 拍快照时并不会锁住自身的状态;而是对 znode 树做一次深度优先扫描,把数据写到磁盘。由于在拍快照时 ZooKeeper 的状态还在变化,所以快照可能并不符合 ZooKeeper 在任何时间点的状态。但是状态变化是等价的,只要我们按序去应用变更,就能恢复出某一个时间点的状态。
Redis RDB 快照 + AOF 日志也差不多
4.4 CS 交互
- 服务器按序处理写请求时不会并发处理其他读写请求。通知由服务器在本地处理,只有客户端连接的服务器才会才会追踪并触发该客户端的通知。
- 读请求只由每台服务器本地处理。每个读请求会被标记上一个 zxid,这是服务器看到的最后一把事务。这个 zxid 决定了读请求相对于写请求的部分顺序。处理读请求没有磁盘和协议层的活动,有着卓越的性能。
- 快速读取的一个缺点是无法保证读取操作的顺序,可能会返回一个过期的值,即便更新已经提交了。不是所有应用程序都需要最新的顺序,但是 ZooKeeper 为需要的应用实现了 sync,客户端在读取前调用同步 API。
- ZooKeeper 以 FIFO 顺序处理来自客户端的请求。心跳信息也包含了客户端连接的服务器所看到的最后一个 zxid。如果客户端连接至一个新的服务器节点,该节点会检查客户端的 zxid 和它最新的 zxid,确保它与客户端看到的数据一样新。如果客户端的视角比服务器更新,服务器在追上进度之前不会与它建立会话。客户端保证能够找到一个有最新数据的服务器,因为它只能看到已经复制到大多数 ZooKeeper 副本的变化。
- 如果客户端请求的频率足够高,就没必要发送心跳包了。要是客户端与服务器通信失败,它会连接到不同的 ZooKeeper 节点重建会话。