用于大规模 AI 训练的 RoCE 网络
Jan 8, 2025 21:30 · 3517 words · 8 minute read

AI 的发展引领了一个通信的新纪元:分布式训练给数据中心网络基础设施带来了巨大的压力。例如一个典型的生成式 AI 任务可能要在数周内紧密协调成千上万块 GPU。构建能满足这些需求且可靠的高性能网络基础设施是要重新设计数据中心网络的。
当 Meta 引入分布式基于的 GPU 训练时,我们决定为这些 GPU 集群量身定制数据中心网络,选择 RDMA Over Converged Ethernet version 2(RoCE v2)作为大部分 AI 算力的节点间通信传输方式。
我们成功地扩展了 RoCE 网络,从原型到在多个集群中部署,每个集群有数千块 GPU。这些 RoCE 集群支持广泛的分布式 GPU 训练任务,包括排序、内容推荐、内容理解、自然语言处理以及生成式 AI 模型训练等工作负载。
拓扑
我们专门为分布式训练构建了一个专用的后端网络,这使得我们能够独立于数据中心网络的其他部分来推进、操作和伸缩。为了支持大型语言模型(LLM),我们将后端网络扩展到数据中心的规模,例如,将拓扑感知集成到训练任务调度器中。
前后分离
训练集群依赖于两个独立的网络:前端(FE)网络用于数据输入、检查点和日志等任务;后端网络(BE)用于训练。
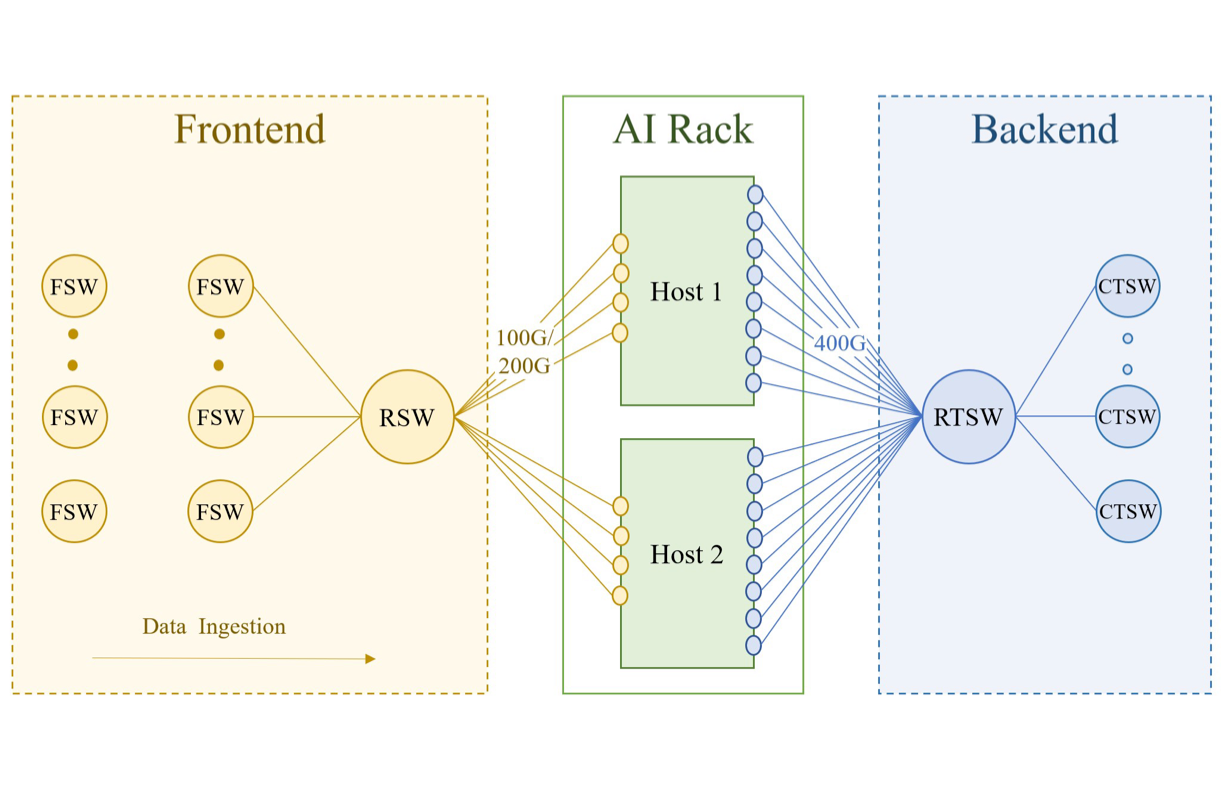
训练机柜连接数据中心网络的 FE 和 BE。FE 有分层的网络结构,包括机柜交换机(RSW)、fabric 交换机(FSW)以及为 GPU 提供训练负载必要的输入数据的存储。我们确保机架交换机上有足够的入向带宽,以免影响训练工作负载。
BE 是一种专用的 fabric1,将所有 RDMA 网卡连接成一种非阻塞的架构,在集群中任意两块 GPU 之间提供高带宽、低延迟和无损传输的网络,无论它们处于什么物理位置。该后端 fabric 网络使用 RoCEv2 协议,将 RDMA 服务封装到 UDP 包中在网络上传输。
AI Zone
我们的 BE 网络经历了多次转变。最初 GPU 集群采用简单的星形拓扑结构,几个 AI 机架连接到一个运行 RoCEv1 协议的中央以太网交换机。这种架构在 GPU 扩展和交换机冗余方面存在明显局限,因此为了扩展性和高可用我们迅速转向基于 fabric 的架构。
我们为 AI 机架设计了一个两级 Clos2 拓扑结构,称为 AI Zone。机架训练交换机(RTSW)作为叶子交换机,使用铜缆为机架内的 GPU 提供扩展连接。主干(spine)层由模块化集群训练交换机(CTSW)组成,为集群中所有机架之间提供横向扩展连接。CTSE 有深度缓冲区,静态分配在底盘的端口上。RTSW 通过单模光纤和 400G 可插拔收发器与 CTSW 相连。
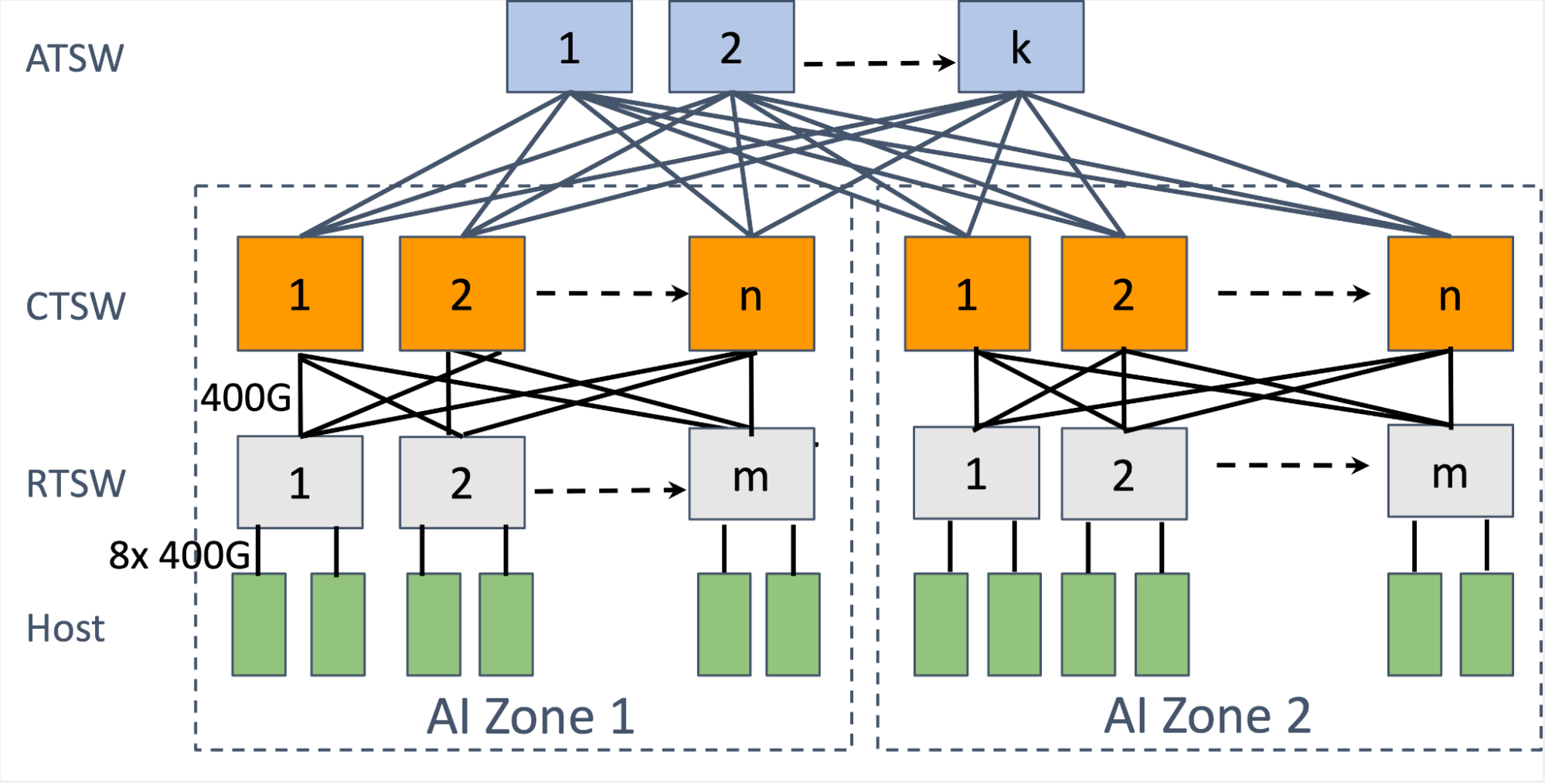
AI Zone 被设计用于以无阻塞的方式支持大量互连的 GPU,但是新兴的 AI 技术进步(如 Llama 等 LLM)需要比单个 AI Zone 所能提供的更大的 GPU 规模。为此我们设计了一个聚合训练交换机(ATSW)层,用于连接数据中心建筑中的 CTSW,将 RoCE 域扩展到多个 AI Zone。
注意,跨 AI Zone 的连接在设计上是超配的,网络流量使用 ECMP(Equal-cost multi-path routing)等价多路径路由3来均衡。为了缓解跨 AI Zone 流量的性能瓶颈,我们增强了训练任务调度器,在将训练节点划分到不同的 AI Zone 时找到一个“最小切口”,减少跨 AI Zone 的流量和完成时间。调度器通过学习 GPU 服务器在逻辑拓扑中的位置来推荐等级分配。
路由
上述算力和网络拓扑的规模引出了如何高效均衡和路由大量训练流量的问题。具体来说,AI 训练工作负载有这些特点:
- 低熵:与传统数据中心工作负载相比,AI 负载的流量总量和花样少得多,而且流量模式通常是重复、可预测的。
- 迸发:在时间维度上,流量通常以毫秒级的时间粒度表现出“时断时续”的特征。
- 巨流:每次迸发,每个流都可能达到网卡的线速。
ECMP 和路径绑定
我们最初考虑广泛采用 ECMP,根据源 IP、目的 IP、源 UDP 端口、目的端口以及协议这个五元组的哈希值随机分配流量。然而不出所料,由于较低的流量熵值,ECMP 在训练工作负载中表现不佳。
另外我们在最初几年设计并部署了一个路径绑定方案,根据目标“片”(RTSW 下行链路的索引)将数据包路由到特定的路径。如果每个机架都被分配相同的任务而且网络中没有故障,那么就很有效。但是这种情况不多。我们发现一个机架可能只有一部分被分配给一项任务,机架上的两台主机只有一台使用上行带宽。这种碎片化的任务分配会造成特定 RTSW 上行链路流量分布不均匀和拥塞,训练性能最多会降低 30% 以上。此外上行链路或 CTSW 网络故障会导致受影响的流量被 ECMP 不均衡地重新分配到其他 CTSW,这些重新分配的流量与其他现有流量冲突,导致整个训练任务放缓。
我们通过倍增 RTSW 的上行带宽来减轻这些流量冲突的影响。虽然减小了对性能的直接影响,但这个方案开销太大了,因此我们认为这不可持续,并继续推进至下一阶段。
队列对扩展(queue pair scaling)
接着我们重新研究了 ECMP,通过队列对(QP)扩展软件功能,提升分层集合的流数量。
为了实现这个,我们配置交换机来增强 ECMP(E-ECMP),使用交换机 ASIC 的 UDF 能力对 RoCE 数据包的目的 QP 字段进行额外哈希。这增加了熵,相比未使用 QP 扩展的基础 ECMP,我们观察到 E-ECMP 在 AllReduce 集合中性能提升达到 40%。
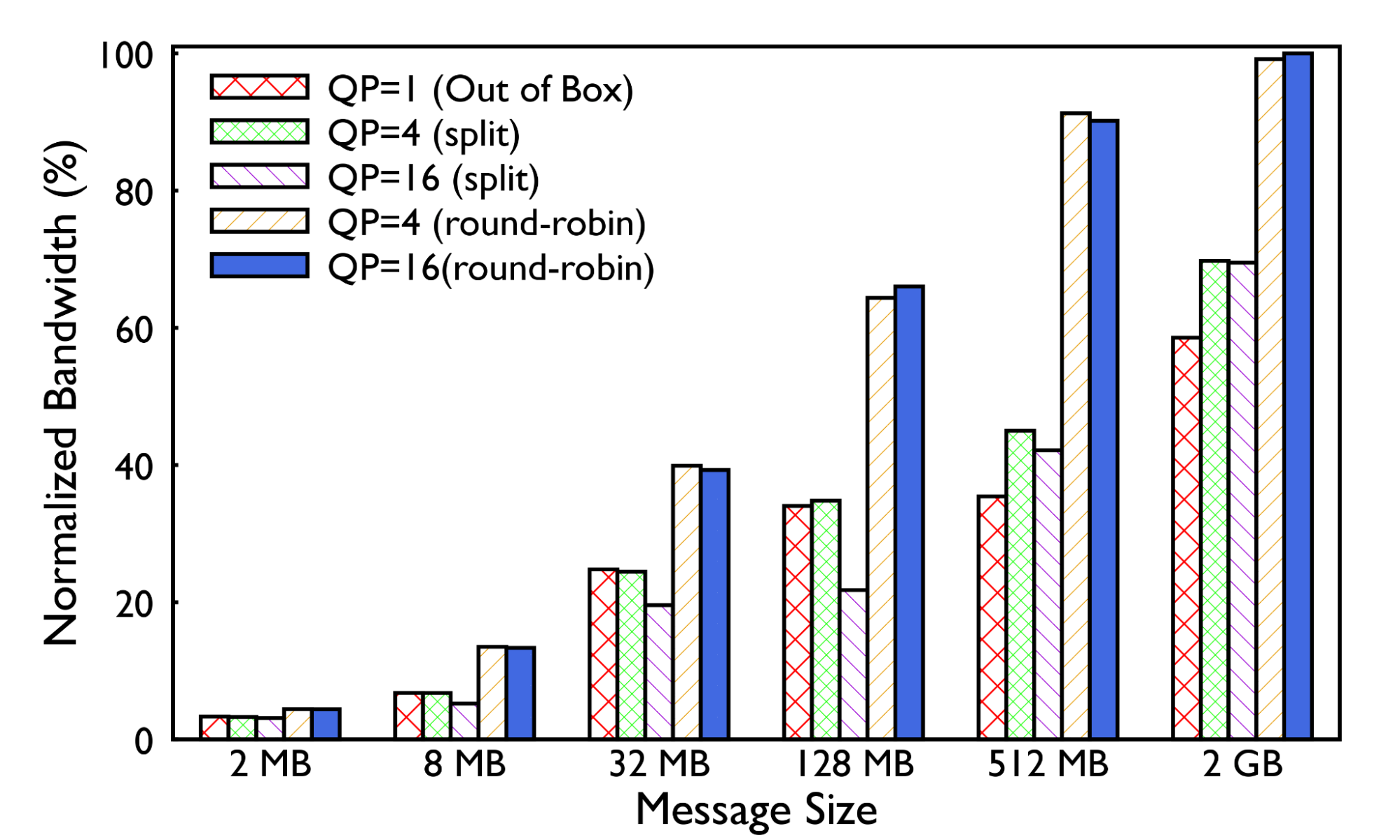
我们评估了两种 QP 策略。第一种将原本通过单个 QP 发布的每条消息拆分到多个 QP 上,从而产生多个流。但这也会导致 fabric 网络上的报文变小,并产生多个 ACK。第二种是以轮询的方式将每条消息发送到不同队列。对于在生产中使用 NCCL4 展示的网卡消息大小,我们观察到后者表现更好。该功能对于 ECMP 扩展性至关重要。
虽然通过 QP 扩展提升了 ECMP 性能,但哈希潜在的概率特性始终是该路由方案的一个缺陷。而且根据工作负载类型定制 QP 扩展因子虽然在短期内可行,但从长期看带来了操作复杂度。
拥塞控制
当我们向 400G 部署过渡时,尝试调整 DCQCN5 来适应新的网速和拓扑。但相比 200G 网络,默认的 DCQCN 设置和翻倍的 ECN 阈值导致性能下降。进一步排查发现,固件中的 DCQCN 实现变了,有 bug。
我们于是不使用 DCQCN,到目前为止,仅靠 PFC(Priority-based Flow Control)6做流量控制,没有使用其他传输层拥塞控制,已有一年多的经验。我们观察到训练集群性能稳定且没有持续性的拥塞。
接收方驱动的流量准入
为解决 400G 及以上的拥塞和更好的性能,我们共同设计了集合库和 RoCE 传输,来执行接收方驱动的流量准入。在生产训练集群中,GPU 到 GPU 的通信架构主要通过 NCCL 集合库使用两级复制和接收方发起的通信。每个 CPU 的高带宽内存(HBM)维护着多个通道,用于并行传输分块的集合信息。发送方 CPU 代理线程首先将数据从计算缓冲区复制到可用的通道缓冲区,它只有在接收到接收方发送的 CTS 数据包(包括大小和内存信息)后才发布一条 RDMA 写请求。然后接收方 CPU 线程将通道缓冲区的内容复制到目的计算缓冲区。最后,双方 CPU 代理线程回收通道缓冲区,一旦准备就绪,接收方 CPU 代理会发送另一个 CTS 包。
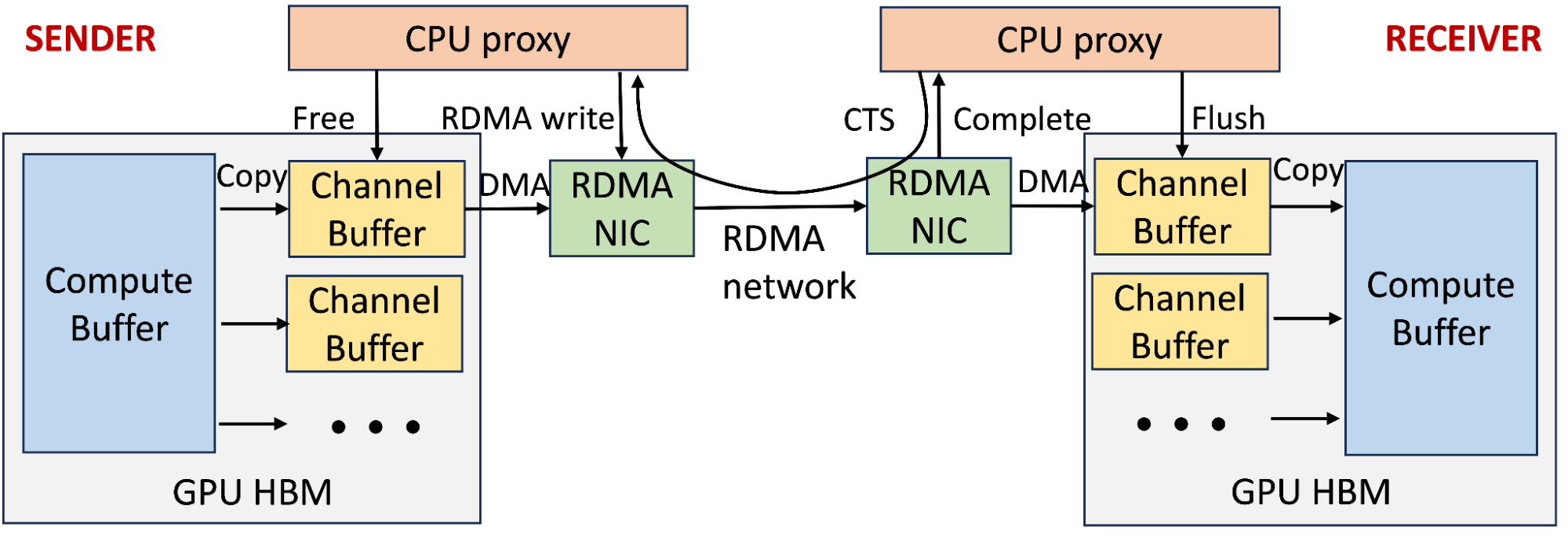
我们有效地利用这一机制作为接收方驱动的流量准入,来限制网络上的在途流量,尤其是在开始出现拥塞时。但想要正确地配置也难,因为:
- 并发计算的 GPU 线程造成资源竞争,因此通道数量有限。
- 设置通道缓冲区大小需要比 Infiniband 更小心地平衡拥塞扩散和带宽未充分利用的问题,因为 RoCE 的流量控制粒度更粗以及可能终端主机速度较慢。
因此我们两步走来提高性能:首先通过实验确定了在不同训练任务规模和集类型下通道数量和缓冲区大小的最佳参数设置;其次在交换机上为 CTS 数据包实现了高优先级队列,加速通知并减轻潜在的带宽匮乏问题。
拥塞控制一直是 RDMA 网络研究的重点。DCQCN 已经成为了已存储为中心的网络的黄金标准。然而我们在分布式 AI 训练工作负载中的经验提供了一个定制拥塞控制算法的不同视角。尽管关闭了 DCQCN,多个 RTSW 实例向一个有深缓冲区的 CTSW 发送 PFC,但四年来,我们从未遇到 AI 训练流量导致 CTSW 持续向 RTSW 发送 PFC 的情况。
当前的解决方案依赖于集合通讯库和网络之间的精确协调,这可能取决于 GPU 和网络之间的相对吞吐量,可能不适用于所有场景。我们鼓励研究界更关注这个主题。
前进
大规模 RoCE 网络的设计和运维来满足分布式 AI 训练工作负载对计算密度和规模日益增长的需求。通过将前端(FE)和后端(BE)网络分离、采用多种路由方案以及优化集合通信模式,我们成功构建了高性能且可靠的网络基础设施。这些设计与见解强调了深入理解训练工作负载的重要性,并将这些转化为网络组件设计,最终推动了分布式 AI 训练基础设施的发展。
请阅读论文:RDMA over Ethernet for Distributed AI Training at Meta Scale
-
文中的 fabric 是 Meta 下一代数据中心网络的名称
https://arthurchiao.art/blog/facebook-f4-data-center-fabric-zh/ ↩︎
-
spine-leaf(Clos 网络)架构
https://www.techtarget.com/searchdatacenter/definition/Leaf-spine ↩︎
-
ECMP 等价多路径路由,允许流量在多个成本相同的路径上进行负载均衡,提供网络的吞吐量和可用性
https://en.wikipedia.org/wiki/Equal-cost_multi-path_routing ↩︎
-
NCCL(NVIDIA Collective Communications Library )提供了一套高性能的集合通信操作,被广泛用于分布式计算
-
DCQCN 是为数据中心网络设计的拥塞控制协议,适用于基于 RDMA 的高性能通信
https://www.wwt.com/article/understanding-data-center-quantized-congestion-notification-dcqcn ↩︎
-
PFC 流量控制技术
https://info.support.huawei.com/info-finder/encyclopedia/en/PFC.html ↩︎