kubelet 镜像拉取问题
Jan 18, 2025 12:30 · 2281 words · 5 minute read

可能有同学知道这个问题:在拉取镜像时删除 Pod,它会阻塞在 Terminating 状态,直到镜像拉取完成才会被真正删除。在工作负载主要为 AI 任务的 Kubernetes 集群该问题尤为常见,因为镜像的体积非常庞大,动辄几十 GB。启动这类 Pod 通常需要漫长地等待镜像拉取完成。
大家都知道 Pod 创建时,在调度完成后,对应节点上的 kubelet 负责创建 Pod“实体”,镜像实际上是容器运行时(本文以 containerd 为例)在拉取的。而 kubelet 和 containerd 之间通过 CRI(容器运行时接口)协议通信。
CRI
CRI 是为了让 kubelet 能够无感地对接(解耦)多种容器运行时而存在,它定义了 kubelet 和容器运行时通信的 gRPC 协议。
CRI 主要有两个协议组成:
-
RuntimeService 用于管理 Pod(容器)生命周期
// Runtime service defines the public APIs for remote container runtimes service RuntimeService { rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {} rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {} rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {} rpc PodSandboxStatus(PodSandboxStatusRequest) returns (PodSandboxStatusResponse) {} rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {} rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}rpc rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {} rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}rpc rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {} // and so on } -
ImageService 用于管理镜像
// ImageService defines the public APIs for managing images. service ImageService { rpc ListImages(ListImagesRequest) returns (ListImagesResponse) {} rpc ImageStatus(ImageStatusRequest) returns (ImageStatusResponse) {} rpc PullImage(PullImageRequest) returns (PullImageResponse) {} rpc RemoveImage(RemoveImageRequest) returns (RemoveImageResponse) {} rpc ImageFsInfo(ImageFsInfoRequest) returns (ImageFsInfoResponse) {} }
kubelet 是调用 CRI API 的客户端,而 containerd 则是 CRI 服务的提供方。containerd 是插件结构,它的所有功能均由各种插件实现:
$ ctr plugins ls | grep cri
io.containerd.grpc.v1 cri linux/amd64 ok
上述 CRI 服务由 containerd 中的 cri 插件实现 https://github.com/containerd/containerd/tree/v1.7.7/pkg/cri
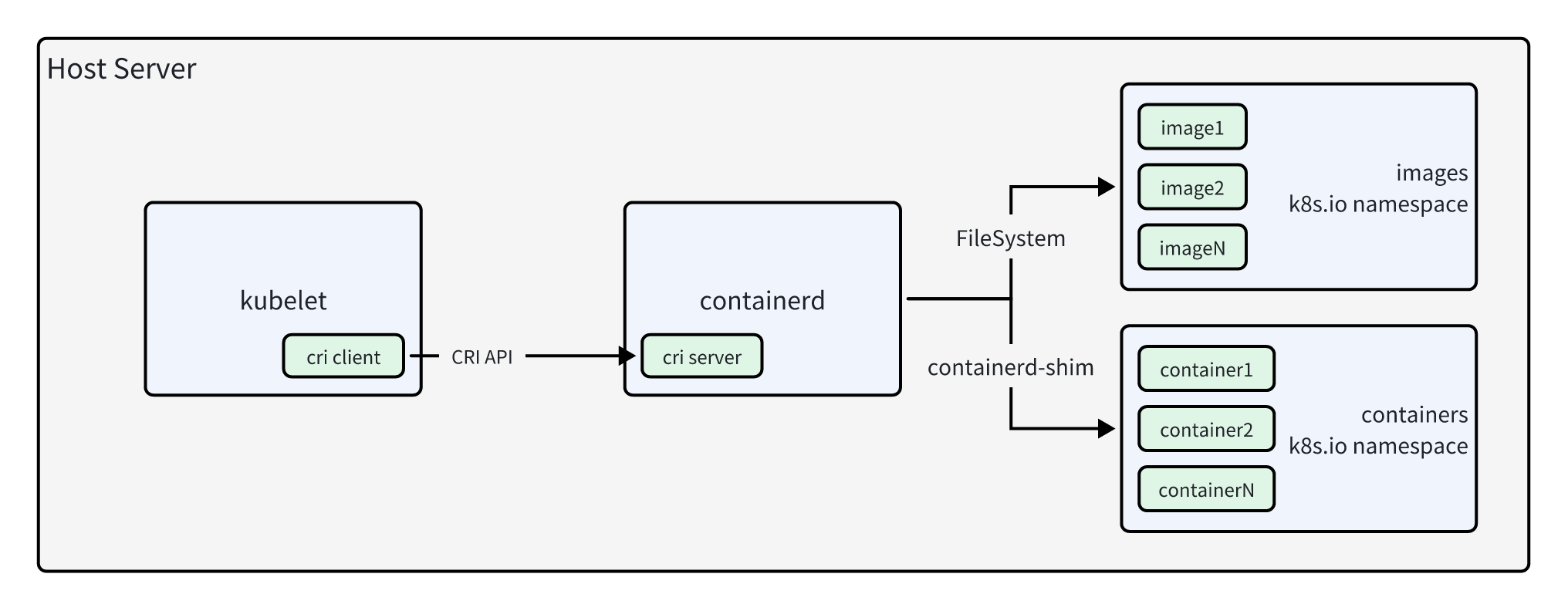
kubelet 启动 Pod 实体分为两步:
- 首先 kubelet 中的 cri client 与 containerd 中的 cri server 通信,根据 Pod 定义中的
imagePullPolicy策略查看其所在节点上是否已存在镜像,根据结果以及imagePullPolicy综合判断是否要调用PullImageAPI 拉取镜像。 - 待镜像处理完成后,再与 cri server 通信调用 RuntimeService 系列 API 启动 sandbox(也就是 pause)容器和业务容器。
containerd 中 cri server 对上述两个 API 协议的实现在 https://github.com/containerd/containerd/blob/2c38cad77cdb2644ebf8f56a2e3f094344ef0f41/pkg/cri/server/ 路径下:
- pkg/cri/server/image_pull.go
- pkg/cri/server/sandbox_run.go
- pkg/cri/server/container_create.go
- pkg/cri/server/container_start.go
请自行阅读,不赘述。
kubelet
CRI API 的调用方是 kubelet,问题正是出在 kubelet 这里。
已有 issue 在追踪该问题 #125050
拉取镜像
kubelet 在启动容器(Pod)前,先要确保镜像存在 https://github.com/kubernetes/kubernetes/blob/1649f592f1909b97aa3c2a0a8f968a3fd05a7b8b/pkg/kubelet/kuberuntime/kuberuntime_container.go#L167-L295:
// startContainer starts a container and returns a message indicates why it is failed on error.
// It starts the container through the following steps:
// * pull the image
// * create the container
// * start the container
// * run the post start lifecycle hooks (if applicable)
func (m *kubeGenericRuntimeManager) startContainer(ctx context.Context, podSandboxID string, podSandboxConfig *runtimeapi.PodSandboxConfig, spec *startSpec, pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, podIP string, podIPs []string) (string, error) {
container := spec.container
// Step 1: pull the image.
imageRef, msg, err := m.imagePuller.EnsureImageExists(ctx, pod, container, pullSecrets, podSandboxConfig)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, "", v1.EventTypeWarning, events.FailedToCreateContainer, "Error: %v", s.Message())
return msg, err
}
// Step 2: create the container.
// For a new container, the RestartCount should be 0
// a lot of code here
}
注释已经非常明确了。这里必须向上追踪入参上下文 ctx 的来源:kubeGenericRuntimeManager.startContainer <- kubeGenericRuntimeManager.SyncPod <- Kubelet.syncPod
func (kl *Kubelet) syncPod(_ context.Context, updateType kubetypes.SyncPodType, pod, mirrorPod *v1.Pod, podStatus *kubecontainer.PodStatus) (isTerminal bool, err error) {
// TODO(#113606): connect this with the incoming context parameter, which comes from the pod worker.
// Currently, using that context causes test failures.
ctx := context.TODO()
// a lot of code here
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(ctx, pod, podStatus, pullSecrets, kl.backOff)
}
该 ctx 是一个未做任何处理的空白上下文,这时我们已经能猜到问题的原因了。
回到 kubeGenericRuntimeManager.startContainer 向下追踪镜像的处理,来到 imagePuller.EnsureImageExists 这行代码。
kubelet 中负责管理镜像的组件是 imageManager,它实现了 ImageManager 接口,包括 EnsureImageExists 方法:
func (m *imageManager) EnsureImageExists(ctx context.Context, pod *v1.Pod, container *v1.Container, pullSecrets []v1.Secret, podSandboxConfig *runtimeapi.PodSandboxConfig) (string, string, error) {
// a lot of code here
pullChan := make(chan pullResult)
m.puller.pullImage(ctx, spec, pullSecrets, pullChan, podSandboxConfig)
imagePullResult := <-pullChan
if imagePullResult.err != nil {
m.logIt(ref, v1.EventTypeWarning, events.FailedToPullImage, logPrefix, fmt.Sprintf("Failed to pull image %q: %v", container.Image, imagePullResult.err), klog.Warning)
m.backOff.Next(backOffKey, m.backOff.Clock.Now())
if imagePullResult.err == ErrRegistryUnavailable {
msg := fmt.Sprintf("image pull failed for %s because the registry is unavailable.", container.Image)
return "", msg, imagePullResult.err
}
return "", imagePullResult.err.Error(), ErrImagePull
}
}
在确定了要拉取镜像后,通过 pullChan 通道同步地传递镜像拉取结果,在此之前都在 puller.pullImage 方法调用中阻塞。imagePuller 接口也有两种实现,kubelet 默认为并行拉取,即 parallelImagePuller:
func (pip *parallelImagePuller) pullImage(ctx context.Context, spec kubecontainer.ImageSpec, pullSecrets []v1.Secret, pullChan chan<- pullResult, podSandboxConfig *runtimeapi.PodSandboxConfig) {
go func() {
startTime := time.Now()
imageRef, err := pip.imageService.PullImage(ctx, spec, pullSecrets, podSandboxConfig)
pullChan <- pullResult{
imageRef: imageRef,
err: err,
pullDuration: time.Since(startTime),
}
}()
}
这里调用 CRI PullImage API,由 containerd cri server 拉取镜像,该过程是同步的,除非 cri server 端出错或者镜像拉取完成,否则持续阻塞。
删除 Pod
kubelet 中的 manager 组件会将本地容器的状态同步至 apiserver,Pod 状态中的 containerStatuses 字段由它来维护:
manager.syncPod -> manager.needsUpdate -> manager.canBeDeleted -> Kubelet.PodResourcesAreReclaimed
func (m *manager) canBeDeleted(pod *v1.Pod, status v1.PodStatus) bool {
if pod.DeletionTimestamp == nil || kubetypes.IsMirrorPod(pod) {
return false
}
return m.podDeletionSafety.PodResourcesAreReclaimed(pod, status)
}
Kubernetes 中删除资源对象时,实际上是先更新对象元数据中的删除时间戳 deletionTimestamp,Pod 也不例外。当 Pod 被“删除”,kube-apiserver 会给 Pod 赋予删除时间戳,为当前时间。
// PodResourcesAreReclaimed returns true if all required node-level resources that a pod was consuming have
// been reclaimed by the kubelet. Reclaiming resources is a prerequisite to deleting a pod from the API server.
func (kl *Kubelet) PodResourcesAreReclaimed(pod *v1.Pod, status v1.PodStatus) bool {
if kl.podWorkers.CouldHaveRunningContainers(pod.UID) {
// We shouldn't delete pods that still have running containers
klog.V(3).InfoS("Pod is terminated, but some containers are still running", "pod", klog.KObj(pod))
return false
}
// a lot of code here
}
在 Pod 拉取镜像时删除 Pod,如果调大日志粒度,就能够看到 Pod is terminated, but some containers are still running 输出。在终止 Pod 时,kubelet 首先检查容器状态。podWorkers 组件持续追踪并确保 Pod 和容器运行时还有其他的子系统状态是一致的,它维护内部的 Pod 同步状态表:
type podWorkers struct {
// Tracks by UID the termination status of a pod - syncing, terminating,
// terminated, and evicted.
podSyncStatuses map[types.UID]*podSyncStatus
}
func (p *podWorkers) CouldHaveRunningContainers(uid types.UID) bool {
p.podLock.Lock()
defer p.podLock.Unlock()
if status, ok := p.podSyncStatuses[uid]; ok {
return !status.IsTerminated()
}
// once all pods are synced, any pod without sync status is known to not be running.
return !p.podsSynced
}
func (s *podSyncStatus) IsTerminated() bool { return !s.terminatedAt.IsZero() }
因为此时容器都没启动(正在拉取镜像),status.IsTerminated() 返回 false,因为 terminatedAt 还没有数据,这里有两个 !,不太好看。
而在删除 Pod 时,并未通过上下文向拉取镜像的操作传递终止信号,podWorkers 中的 Pod 同步状态没有及时更新到结束状态,导致 kubelet 错误地认为仍有容器在运行。
这里要强调通过 kubectl delete Pod --force 强制删除 Pod 是治标不治本的行为,只是显式地删除了 Pod 数据记录,但节点上的 kubelet 仍会继续拉取镜像至完成后再处理 Pod GC。在一些特定的使用场景中,可能会造成磁盘使用率过高导致其他 Pod 被驱逐。
解决方案
- 修改 kubelet 源码,在感知到 Pod 处于删除状态时正确地传递上下文终止拉取镜像的操作,然后更新 Pod 同步状态。
- 将业务镜像的拉取操作从 kubelet 转移到 init container 中,通过容器中的进程调用 CRI PullImage API 拉取镜像(需要自行编写该工具,封装 cri client),在删除 Pod 时 kubelet 终止 init container,也就终止了镜像拉取操作。