Uber 是如何优化 LLM 训练的
Nov 23, 2024 17:00 · 3121 words · 7 minute read

介绍
由大语言模型驱动的生成式 AI 在 Uber 被广泛应用,例如外卖推荐和搜索、客户支持聊天机器人、代码开放以及 SQL 语句生成。
Uber 利用像 Meta Llama 2 和 Mistral AI Mixtral 这类开源模型,和来自 OpenAI 和 Google 的闭源模型,还有其他第三方供应商。作为一家在出行和配送领域领先的公司,Uber 拥有大量的领域相关的知识可提升这些应用程序的 LLM 性能,一种方式是通过 RAG(检索增强生成)。
Uber 还在探索通过持续的预训练和指令微调,将 LLM 适配到 Uber 知识库的方法。例如,对于 Uber Eats,我们发现了一个基于 Uber 关于商品、菜品和餐馆的知识进行微调的模型,相比开源模型能够更准确地改进标记商品、搜索查询和用户偏好理解。甚至,这些微调后的模型在性能上接近 GPT-4,还能承载 Uber 规模下大得多的流量。
AI 社区支持和开源库(如 transformers、Microsoft DeepSpeed 和 PyTorch FSDP)使 Uber 能够快速构建基础设施来高效地训练和评估 LLM。新兴的开源项目(如 Meta Llama 3 的 llama-recipes、Microsoft LoRA、QLoRA 和 Hugging Face PEFT)简化了 LLM 的微调生命周期并减少了工程量。像 Ray 和 vLLM 这些工具最大化地提升了用于开源 LLM 的大规模预训练、微调、离线批量预测以及在线服务能力的吞吐量。
本文中描述的 LLM 训练方法确保了 Uber 在原型设计和开发生成式 AI 驱动的服务的灵活性和速度。我们使用最先进的开源模型,以实现更快、更便宜、更安全和可扩展的实验。
基础设施栈
在 Uber LLM 训练的一个关键组件是经过全面测试的基础设施栈,使得能够快速实验。
第 0 层:硬件
Uber 内部 LLM 工作流调度在两种计算实例上运行:
-
Uber 集群中的 NVIDIA A100 GPU 实例
每台主机配备了 4 个 A100 GPU,600 GB 内存和 3TB SSD
-
Google Cloud 上的 NVIDIA A100 GPU 实例
3-highgpu-8g 类型实例配备 8 个 H100 GPU,1872GB 内存和 6TB SSD
第 1 层:编排
计算资源由 Kubernetes 和 Ray 管理:
- Kubernetes 用于调度训练负载和管理硬件资源
- Ray 还有 KubeRay operator 用于将工作负载分发至 worker
第 2 层:联邦
我们的多 Kubernetes 集群由一个联邦层管理,根据资源可用性调度工作负载。训练作业被设计为有多个任务的作业。JobSpec 定义了作业的目标状态,包括实例 SKU、集群、计算/存储资源等信息。
训练栈
在构建 LLM 训练栈时完全采用了开源技术:具体来说集成了 PyTorch、Ray、Hugging Face、DeepSpeed 和 NCLL 来通过 Michelangelo 平台实现 LLM 训练。
- PyTorch 是我们选择的深度学习框架,因为大多数最先进的开源 LLM 和技术都是用 PyTorch 实现的。
- Ray Train 提供了一个简化的 API,用于在 Ray 集群上使用 PyTorch 搞分布式训练。
- Hugging Face Transformers 提供 API 和工具用于下载和训练最先进的基于 transformer 技术的模型。
- DeepSpeed 是一个深度学习优化套件,可以为深度学习训练和推理提供前所未有的规模和速度。
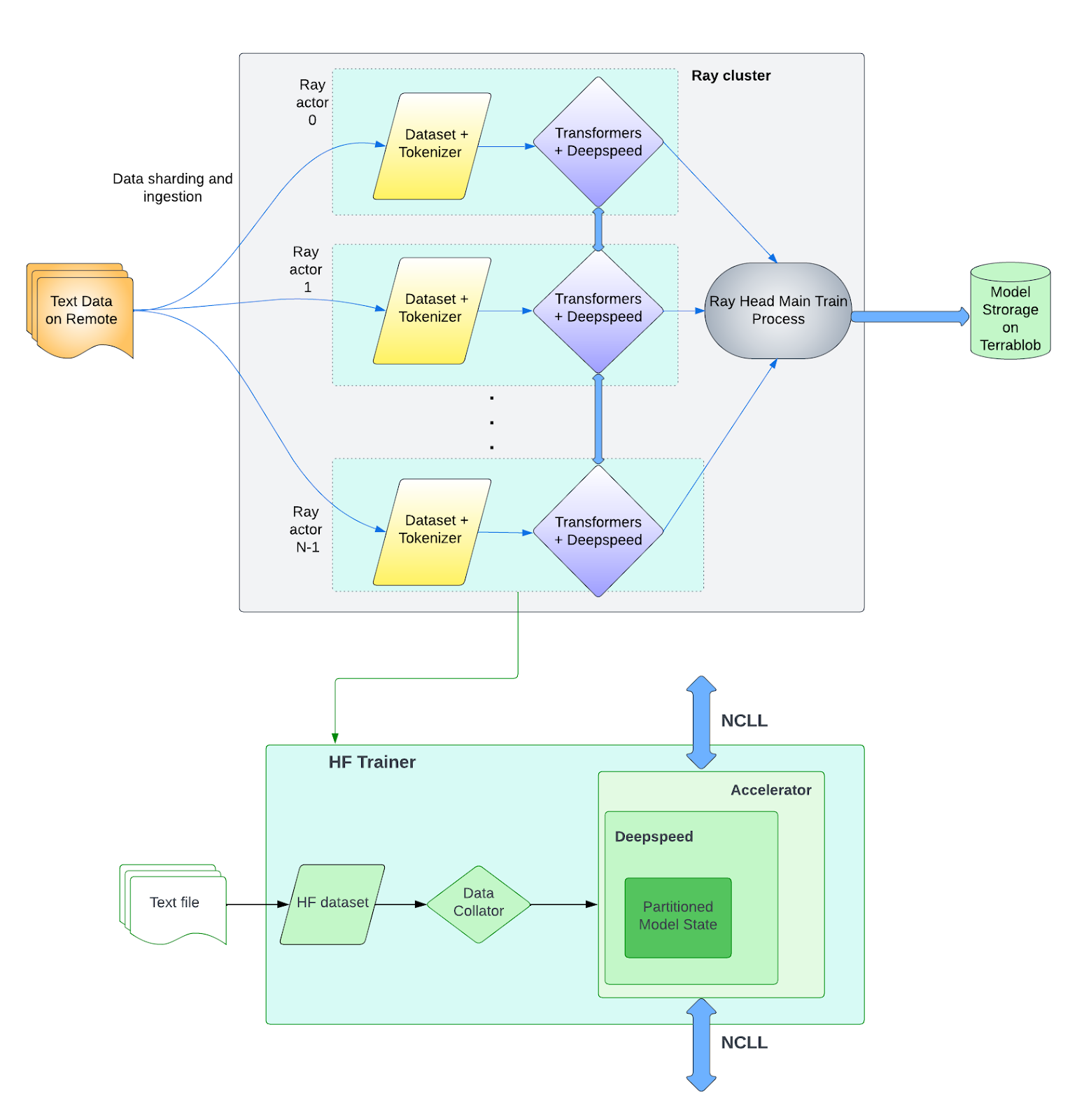
如图 2,Ray 在 LLM 训练栈的顶部,用于协调任务;NCCL 在底部用于 GPU 通信。
分布式训练流水线
我们构建了一个 LLM 分布式训练流水线包括主机通信、数据准备、分布式模型训练和模型检查点管理:
- 主机间多 GPU 通信。 首先 Ray Train 中的 TorchTrainer 会以 Ray Actor 的形式创建多个 worker,处理入向通信(由 Ray Object Store 使用),并在所有主机的 GPU 上初始化一个 PyTorch 分布式进程组(被 DeepSpeed 使用)。
- 数据准备。 LLM 训练框架支持 Uber HDFS、Hugging Face 公共数据集这类远程数据源。
- 模型训练。 分词器将输入文本转换为整数,喂给模型。对于分布式训练,每个 GPU worker 使用 DeepSpeed ZeRO 阶段 1/2/3 选项初始化一个 Hugging Face Transformers Trainer 对象。
- 保存结果。 与训练实验相关的指标保存在 Uber Comet 服务器上。Ray 主节点上主训练进程将训练模型权重和相关配置文件推送到 Terrablob 存储中。
训练结果
我们内部的 Mechelangelo 平台有能力训练任何开源的 LLM。
训练最先进的 LLM
Mechelangelo 平台可以支持最大的开源 LLM,并在不同设置下进行训练,包括全参数微调和使用 LoRA 和 QLoRA 的参数高效微调。
上图显式了 Llama 2 13B 和 Llama 2 70B 在有无 LoRA 时的训练损耗曲线。我们发现,即使 LoRA 和 QLoRA 使用更少的 GPU,训练速度更快,其损耗下降幅度远小于全参数训练。因此提高 LLM 全参数微调的模型浮点运算利用率(MFU)非常重要。
吞吐量/MFU 优化
扩展 Transformer 架构严重受到模型自注意力机制的限制,具有二次的时间和内存复杂度。为了实现更高的训练吞吐量,我们探索了多种行业推荐的方法来优化 GPU 内训使用:CPU offload 和 flash attention。
第一个训练吞吐量优化方法是使用 DeepSpeed ZeRO-stage-3 CPU Optimizer Offload,在训练Llama 2 70B 时降低了至少 34% 显存。这使我们能够批量大小增加 3-4 倍,但仍保持相同的前向和后向速度,从而使训练吞吐量提高 2-3 倍。
第二个训练吞吐量优化探索是遵循 Hugging Face 的建议使用 flash attention,这是一种用于减少二次复杂性并更高效扩展基于 Transformer 模型的注意力算法,使得训练更快。通过 flash attention,我们可以在相同批量大小下节省 50% 显存。如果最大化显存的使用,那么可以在保持兼容前向和后向速度的情况下将批量大小翻倍。
研究训练效率使用模型浮点运算利用率(MFU):MFU 是观察到的与理论上最大吞吐量的比值,假设基准测试以峰值 FLOPS 进行。
在基准测试中,我们使用 Deepspeed Flops Profiler 获取预期的 FLOPS 数值。每个 GPU 的 FLOPS 计算公式为:GPU 的前向和后向 FLOPS / 每次迭代延迟时间,然后将其除以设备的理论峰值性能,得到最终的 MFU 指标。在所有实验中,在不同优化设置下最大化批量大小以充分利用显存。我们通过训练参数实现,将 gradient_accumulation_steps 设置为 1,于是 macro_batch_size = micro_batch_size x num_gpus x 1
我们发现:
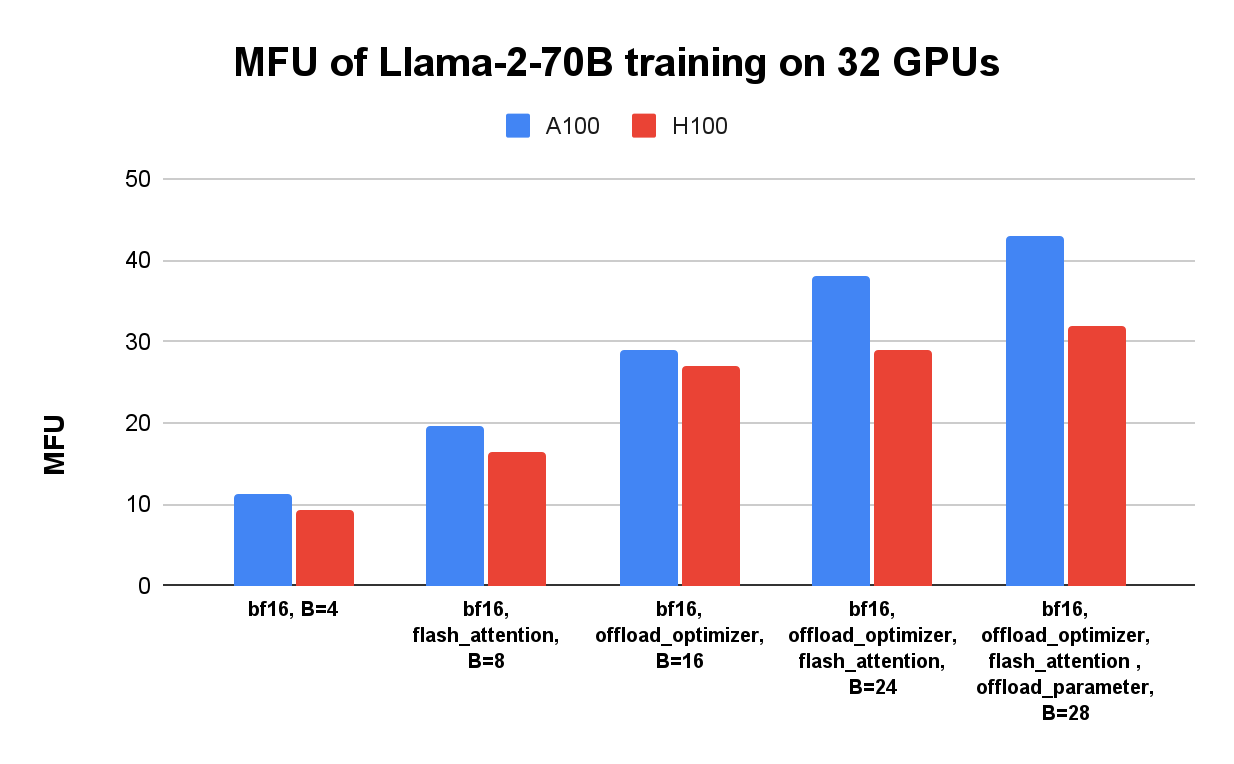
- 吞吐量:flash attention 和 CPU offload 都节省显存,使在 Llama 2 70B 训练中能够将批量的大小增加 2 到 7 倍,同时 32 块 GPU(8 台 A100 主机,4 台 H100 主机)保持最大显存使用量(70-80GB)。吞吐量显著提高。
- MFU:在 H100 上 MFU 低于 A100,在最大显存使用情况下,GPU 利用率并未打满。这可能说明对于 Llama 2 70B 的训练瓶颈在内存。这也是为什么 CPU offload 可以最显著地提高 MFU(图 5)。
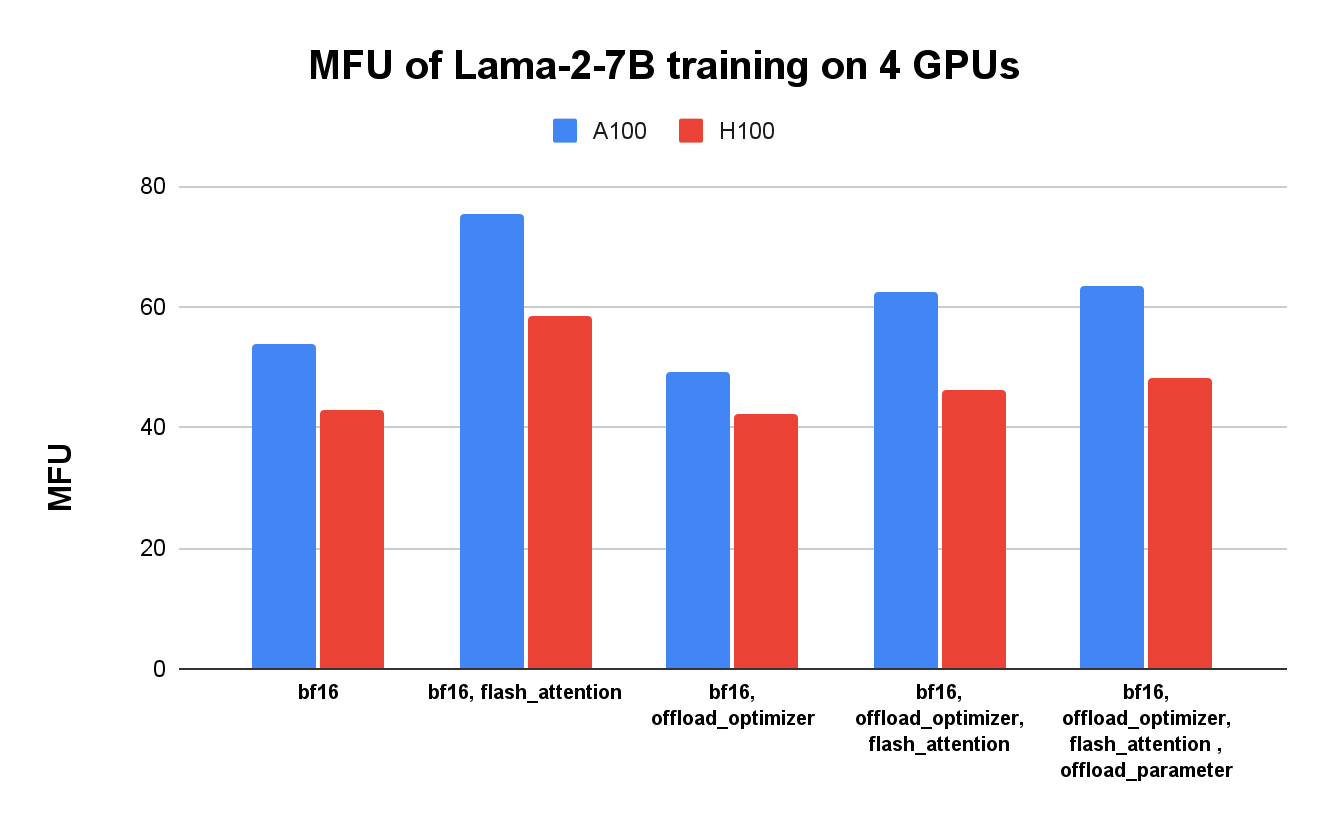
- 计算或内存受限:在 4 块 A100/H100 的单主机上运行 Llama 2 70B 的情况略有不同,可能遇到的是 GPU 计算受限而非内存受限。训练 Llama 2 7B 的 MFU 高于 Llama 2 70B,而且 CPU offload 对提升 MFU 无效。flash attention 可能是最有用的方法(图 6)
- 网络:在 Llama 2 70B 模型训练的实验中,H100 的网络使用率约 10GB/s,而 A100 则是 3GB/s。相比于网络基础设施的极限来说还小,这就表示相比计算和内存,网络不是瓶颈。
LLM 评分
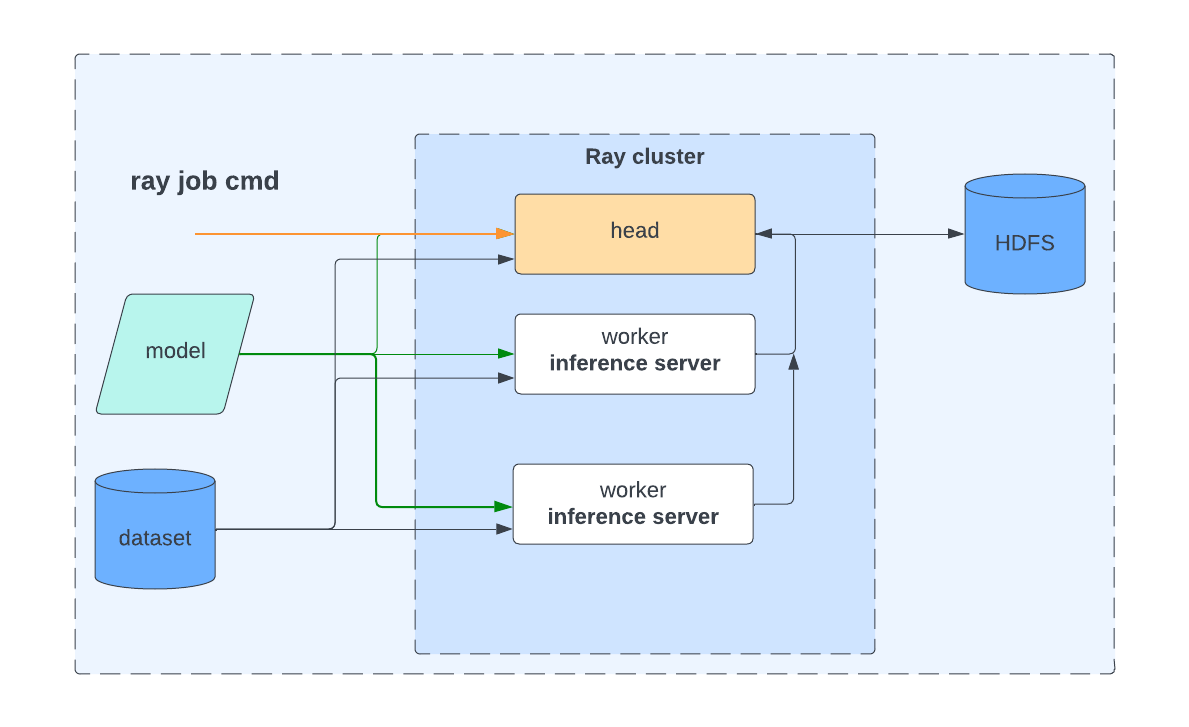
为了评估原始或微调后的模型,我们还实现了一个离线 LLM 评分器来对大型数据集预测。使用 Ray 在 Kubernetes 上创建一个多实例集群,每个实例配备多 GPU,通过这种方式分发数据并行评分。在每个实例上运行诸如 vLLM 之类的推理服务器。
在我们的实现中使用 Ray 作业作为操作原子单位,每个 Ray 作业分配指定数量的 CPU 和 GPU 资源,下载模型并按排名划分数据集。Ray 的 ActorPool 聚合来自不同 Ray Actor 的输出。图 7 展示了该 LLM 评分器的实现。
结论
随着越来越多更大规模的开源模型发布,例如 Llama 3 450B,我们将改进 LLM 的训练基础设施以支持微调,使用这些模型将有助于改进诸如 Uber 外卖推荐和搜索功能。
站在行业的角度上,内部探索 LLM 训练带来了这些理解:
- 拥抱开源是追赶生成式人工智能潮流的关键。 在短时间内我们见证并受益于快速发展的 Hugging Face 开源社区和 DeepSpeed 的快速普及:像 Falcon、Llama 和 Mixtral 这样的开源模型每几个月就会相继发布,通过开源解决方案,我们可以训练最先进的 LLM,并实现最大化 GPU 使用率。
- 拥有经过长期验证且可扩展的集群管理对于快速捕捉最新趋势至关重要。 成熟的 Ray 和 Kubernetes 技术栈使得生产环境可以轻而易举集成新的开源解决方案。