XPUTimer:诊断 LLM 训练异常
Jun 19, 2025 00:30 · 1575 words · 4 minute read
原文 XPUTimer: Anomaly Diagnostics for Divergent LLM Training in GPU Clusters of Thousand-Plus Scale
1 介绍
XPUTimer 是一个面向大规模分布式 LLM 训练的实时诊断框架:
- 节点守护进程监控关键代码段(插桩),在 Python 和 C++ 运行时级别拦截
- 诊断引擎识别并解决异常
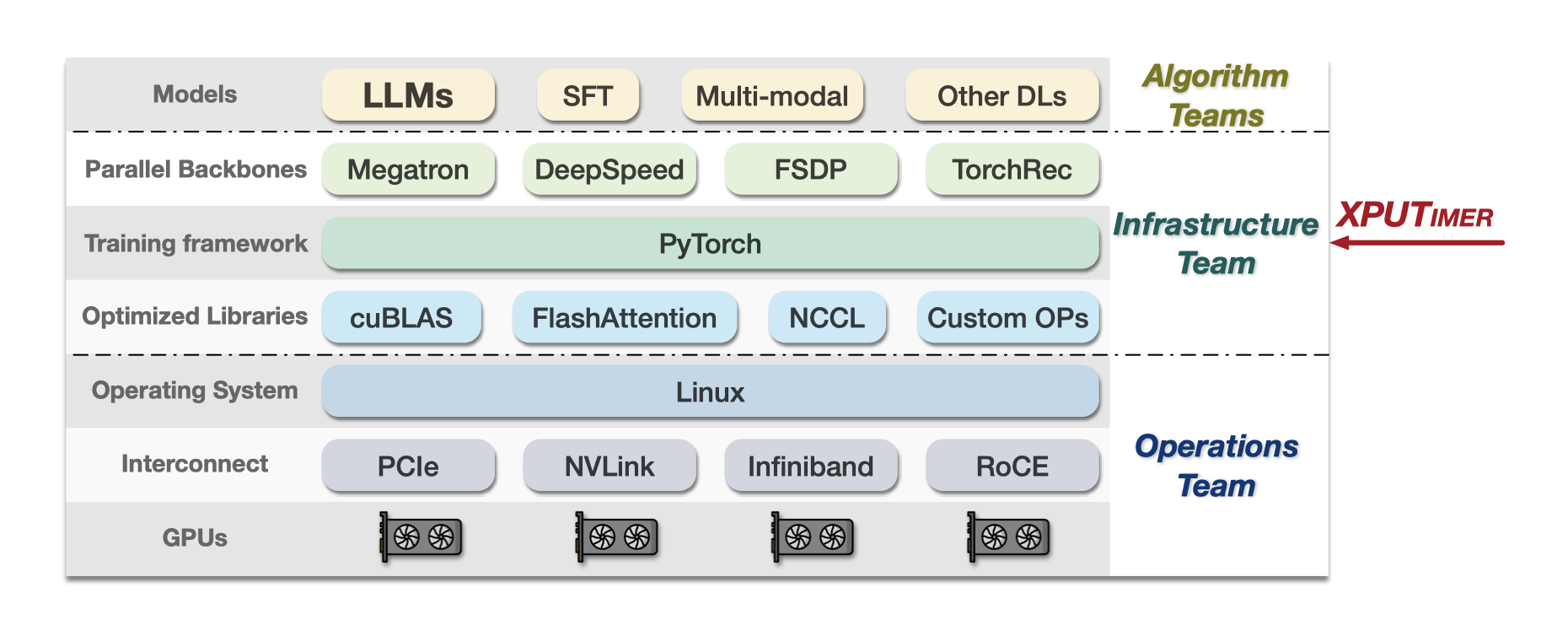
训练异常包括:
- 显式的作业失败
- 隐式的训练变慢
在缺乏框架的情况下,解决这些问题需要跨团队的调查,效率低下。
三个挑战:
- 诊断框架要轻量
- 检测和诊断根本原因(LLM 训练中的错误或减速通常表现出相似的现象)
- 提供可扩展诊断的骨干框架
XPUTimer 作为 DLRover 项目的核心组件开源:https://github.com/intelligent-machine-learning/dlrover/tree/master/xpu_timer。
DLRover 是一个自动化的分布式深度学习系统。
2 背景
大规模 LLM 训练栈中的异常主要分为两大类:错误和降速。可能在任何阶段和时间出现:
- GPU 降频导致 MFU 下降
- LLM 算法的代码更新导致训练启动时的减速
- Python 垃圾回收导致变慢
- 作业挂起(hang 死),可能是因为机器故障:
- 计算算子
- GPU 通信算子
- 操作系统内部问题
很难识别训练减速的根本原因,因为无法使用单一指标来识别。
很难将诊断框架集成到训练框架中,常见的训练框架:
- Megatron
- DeepSpeed
- FSDP
它们的运行时环境和编程接口截然不同。
3 设计
XPUTimer 的设计和实现遵循三个原则:
- 足够轻量,长期运行而不会影响训练性能
- 覆盖足够的运行时信息,遇到异常时借助详尽的分析准确地识别根因
- 和底层架构解耦
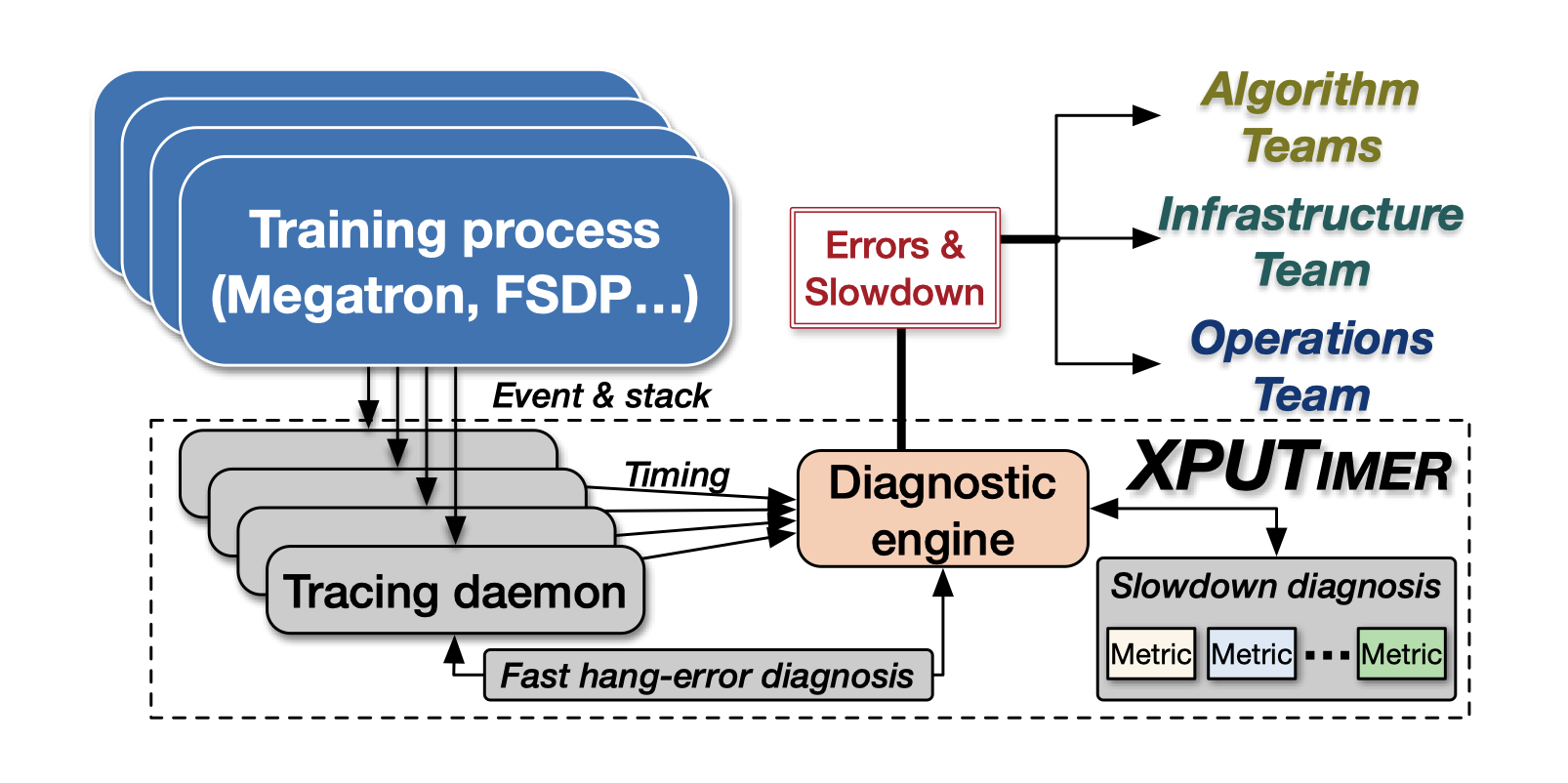
由追踪守护进程(tracing daemon)和诊断引擎(diagnostic engine)两部分组成。
- 自动地将追踪守护进程插到每个训练进程中:仅在 Python 和 C++ 运行时层面上检测关键代码,重点关注 Python API 和 GPU 内核。注入事测量代码段的延迟。
- 守护进程收集的时序数据发送到诊断引擎识别减速。
4 轻量级可选追踪
两个关键设计重点:
- 收集哪些信息
- 如何高效地收集信息
4.1 关键的段指令
CPUTI 这样的性能分析 API 可在后台线程中运行,运行时数据收集开销主要来自高内存使用量而非对计算资源的干扰。
在使用 PyTorch 内置分析器对在 512 个 H800 GPU 上训练的 Llama-70B 模型进行性能分析时,每个训练步骤会产生 5.5GB 的 JSON 日志文件(即使压缩后也有 451MB)
因此 XPUTimer 选择性地检测关键 API 和内核代码,收集实时信息。
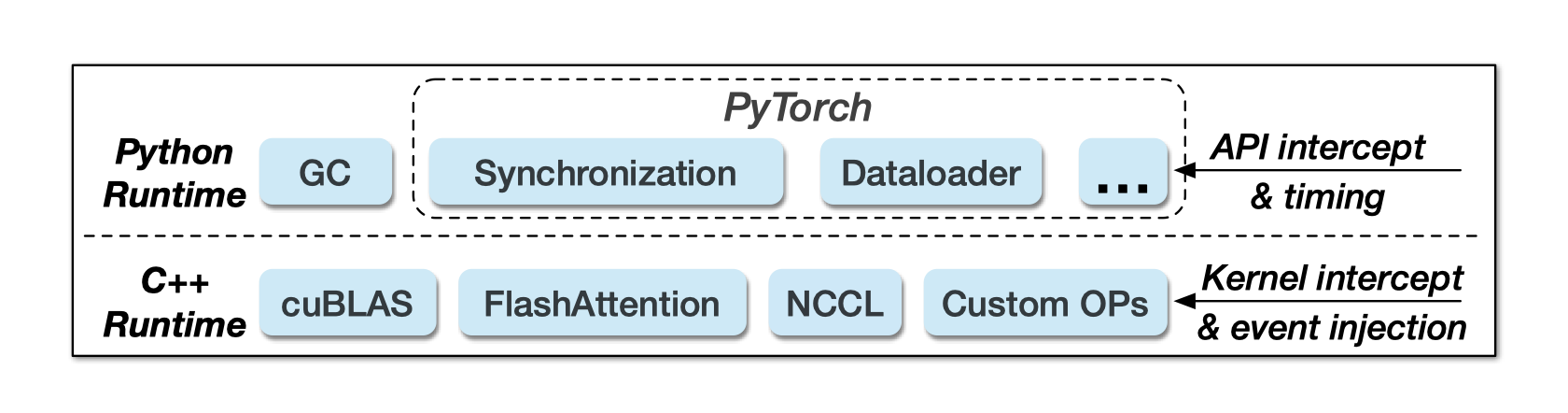
插桩的代码段分为两类:
-
拦截关键 API 调用(同步):
- Python 的垃圾回收
- PyTorch 的 dataloader
- GPU 同步相关 API
-
C++ 运行时级别执行的关键 GPU 计算和通信内核(异步)
由优化库提供,占据大规模训练期间的大部分工作负载。
拦截 C++ 内核需要通过 C++ 接口进行显式注册。
4.2 后台计时
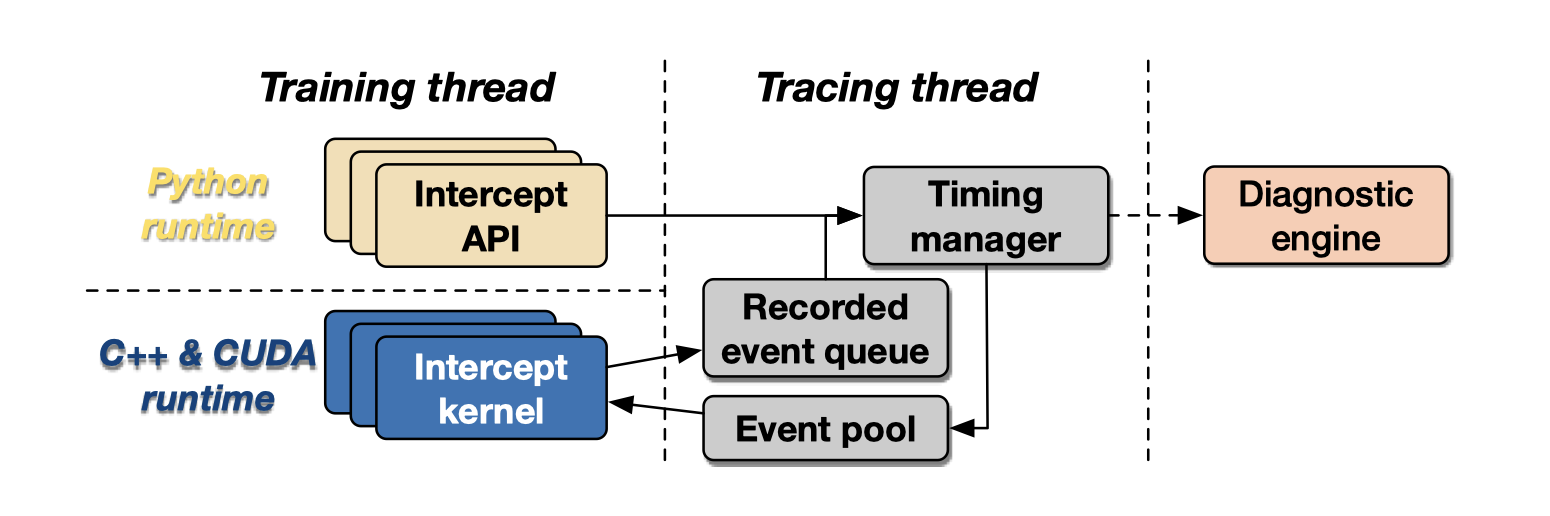
拦截 Python API 和 GPU 内核,测量它们的运行延迟。一个专用的追踪线程在后台运行,管理计时数据。
- 同步的 Python API 调用,直接记录开始结束时间戳后转发。
- 异步的 GPU 内核,拦截后注入 CUDA 事件以记录执行状态,加入队列后续处理。
最后都由计时管理器发送到诊断引擎。
5 异常检测与诊断
5.1 快速运行时错误诊断
训练过程中发生的错误通常源于:
- 操作系统崩溃
- GPU 故障
- 网络中断
典型现象是训练作业挂起。跨多个 GPU 分布式训练 LLM 本质上是训练任务的协调。
如果在预定的超时时间内未能确认事件完成或传输任何实时数据,守护进程会向诊断引擎报告潜在的挂起错误。挂起分类为通信/非通信错误,XPUTimer 通过两个步骤进一步诊断:
-
分析调用栈进行粗粒度诊断
用于诊断非通信错误的机器。
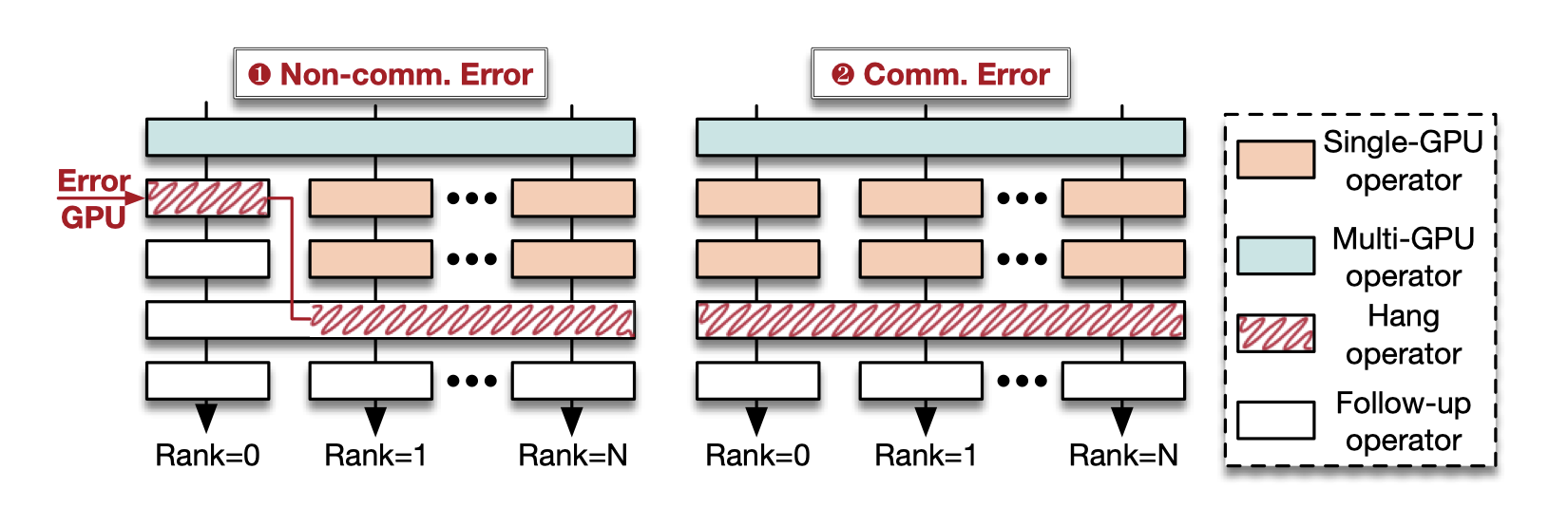
通过调用栈分析挂起错误 当 rank-0 的训练进程由于非通信错误崩溃或暂停时,它会在非通信函数的调用堆栈处停止。而其他 rank 的训练进程继续执行,并最终在与 rank-0 通信的函数相关的调用堆栈处停止。
因为通信挂起的错误无法通过调用栈识别。要找到通信故障的机器,可以简单粗暴地在所有涉及的 GPU 上进行通信测试执行 nccl-test 二分查找。时间复杂度 O(logN),需要数小时才能在数千个 GPU 中找到故障机器。
-
追踪内核进行细粒度诊断
为解决通信错误的机器定位,XPUTimer 利用 CUDA-GDB 进行内核追踪。这种诊断方案是分钟级的。
守护进程通过 CUDA-GDB attach 到挂起的训练进程,然后执行一个脚本,提取详细的通信状态。
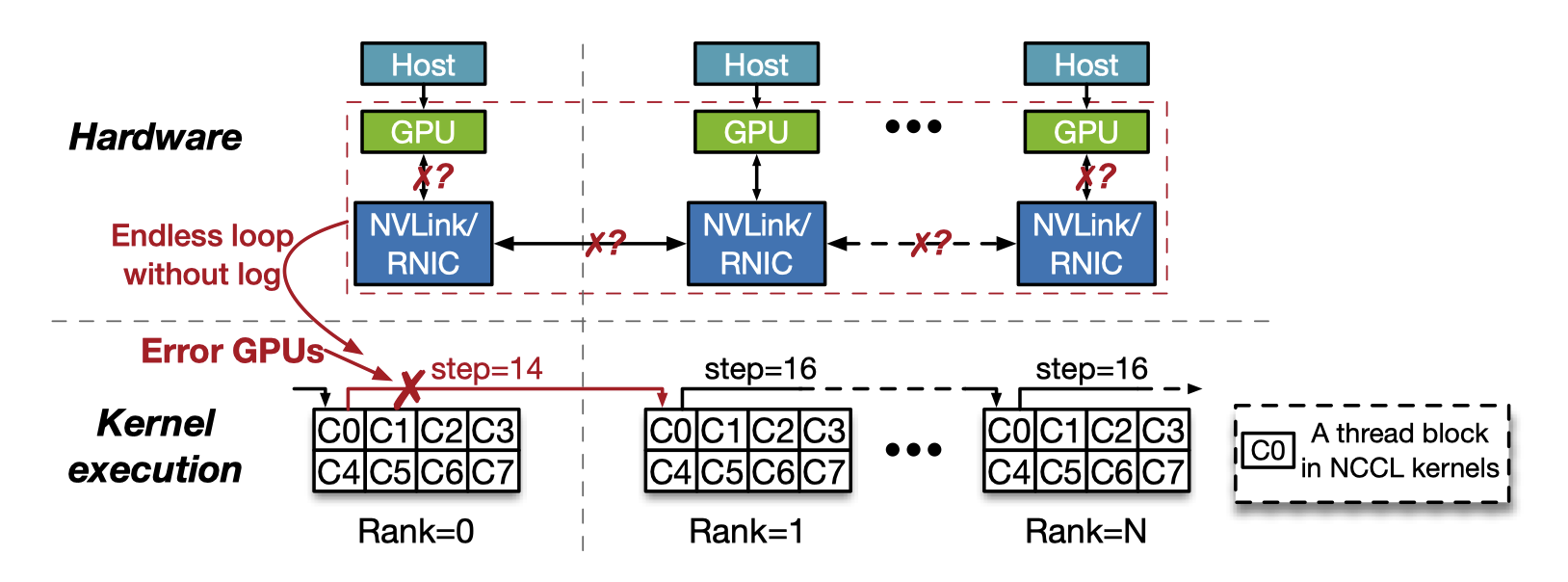
通过内核追踪诊断环状 all-reduce 通信错误 因为在所有涉及的 GPU 上并行执行内核追踪,因此时间复杂度为 O(1),能够在几分钟内完成。
XPUTimer 将检测到错误诊断信息转发给运维团队以进一步处理。
5.2 减速诊断
算法和基础设施团队引入的变更导致的减速难以检测;而硬件导致的相对明显,例如 GPU 降频或网络抖动。
XPUTimer 将从守护进程收集的实时数据聚合为五个主要指标(3 明显 + 2 隐蔽)。
共识:健康的训练流水线应该在一条时间线上,GPU 内核因计算和通信饱和。任何偏离这些特征的情况都预示着任务中潜在减速。
5.2.1 显式减速
-
训练吞吐量(最直接的指标)
检测 Pytorch 的 dataloader API。
与历史训练任务以及同一任务先前的迭代比较。
-
FLOPS
插桩监控关键计算内核的 FLOPS。
通常由 GPU 降频引起。
要考虑与计算内核重叠的通信内核的影响,会误判。
-
带宽
监控并计算通信内核带宽,与基准数据比较。检测到低带宽通信,就使用二分查找进程通信测试。
虽然以上三个指标确保了关键计算和通信 GPU 内核以高性能运行,但它们没覆盖到不太关键的操作。
5.2.2 隐式减速
未插桩的操作分为三类:
- 步内 CPU 操作
- 步间 CPU 操作
- 少数 GPU 内核 —— 通常占用少量 GPU 计算资源
-
issue latency distribution(kernel-issue stall)
算法团队在修改 LLM 模型时可能会无意中引入不必要的 GPU 同步。同时某些函数调用,例如 GC 可能会由 Python 运行时隐式触发。这些步内 CPU 操作可能会在模型的前向传递过程中重复发生,带来相当大的开销。这些操作会导致被称作 kernel-issue stall 的异常,导致训练步骤中的 GPU 空闲。
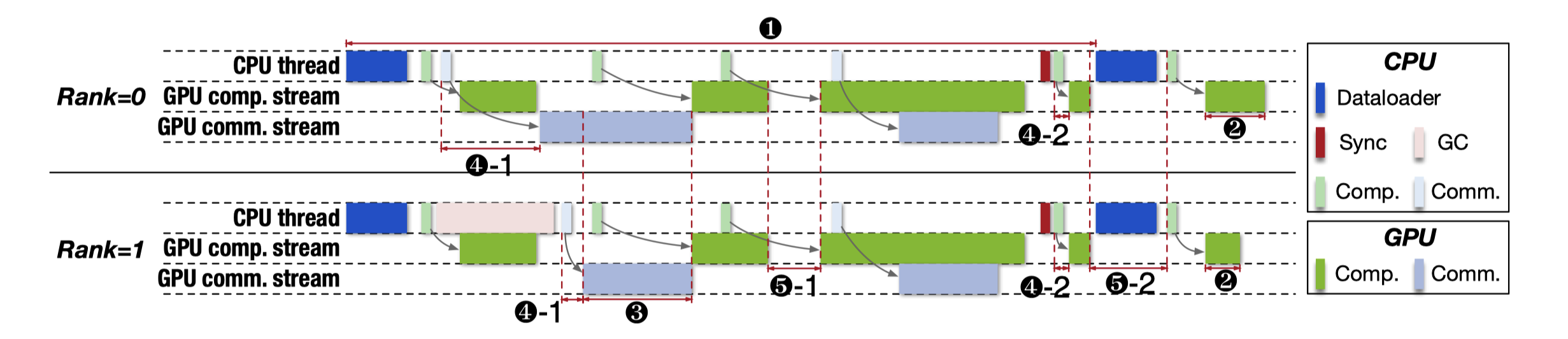
- 不必要的 CPU 操作:Python 运行时 GC 中止了 CPU 线程并导致 rank-1 上的 GPU 内核滞后(图中 4-1)
- 引入不必要的 GPU 同步(图中 4-2)
新指标叫做 issue latency distribution,定义为 kernel 问题时间戳 - 执行开始时间戳
通过监控该指标,并将其与历史数据进行比较,可以识别 kernel-issue stall 异常。
-
其他未覆盖操作的 void percentage
步间的 CPU 操作和少数 GPU 内核操作均以可视化时间线中的空白形式体现,引入了一个指标:void percentage。
计算步间 CPU 操作的 void percentage:Vinter = Tinter / Tstep
- Tinter 表示和步间 CPU 操作相关的延迟
- Tstep 表示训练步骤的总延迟
少数 GPU 内核的 void percentage 计算:Vminority = Tminority / (Tstep - Tinter)
- Tminority 表示所有少数 GPU 内核操作的延迟
当两种 void percentage 超过阈值,步间 GPU 操作或少数 GPU 内核操作可能导致减速。
6 评估
6.1 运行时开销
环境 128 节点 1024 个 H800 GPU,网络走 RoCE。
在主流框架上评估 XPUTimer:
- Megatron
- DeepSpeed
- FSDP
- TorchRec(蚂蚁自研)
测试四种模型:
-
Llama 70B
-
Llama 18B
-
Llama Vision 40B
-
DLRM 72M
-
延迟开销:前三个框架 0.43% 的延迟,TorchRec 1.02%
-
内存开销:
16 块 A100
XPUTimer 在 Pytorch profiler 的三种配置下分别占用 0.39%、1.76% 和2.48% 的内存
6.2 内核追踪的有效性
最长在 309.2s 内检测到故障 GPU,时间复杂度为 O(1),无视规模。
6.3 issue latency distribution 的有效性
- Unhealthy-GC
- Unhealthy-Sync
- Healthy 场景
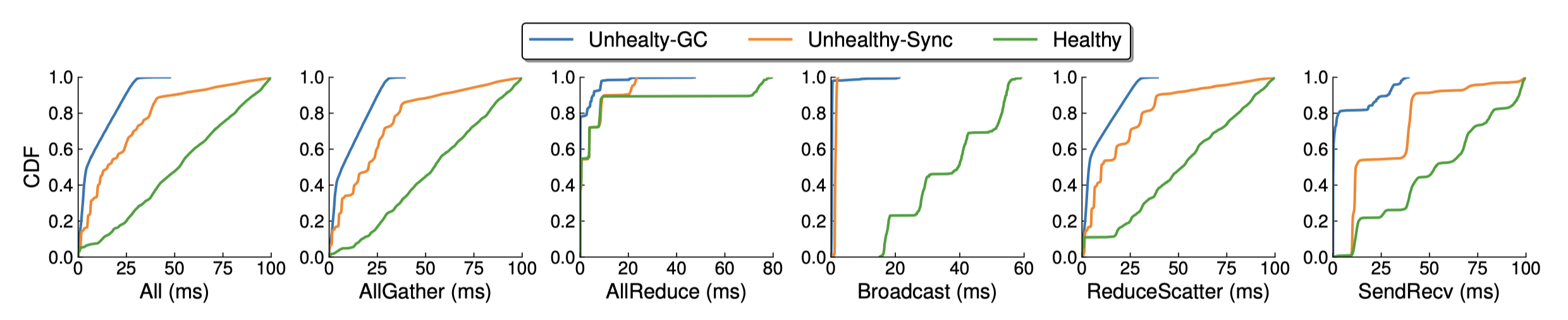
健康的 LLM 训练作业的 issue latency CDF(累积分布函数)呈线性增长,Unhealthy 的骤升,这是因为在健康场景中,不同 rank 的 issue latency 仅受集体通信操作的影响,分布均匀。相比之下,在 Unhealthy-GC 和 Unhealthy-Sync 的情况下,虽然某些 rank 受到影响,但由于 issue 开始时间延迟了,它们的延迟反而变得非常短。
因为处处需要与“基准数据”比较,后续将开源不同模型在不同框架下的数据集。