Write-Ahead Log
Jul 19, 2021 21:00 · 1899 words · 4 minute read

问题
一句话讲就是即使服务器发生故障,也要保证数据的强持久性。
解决方案
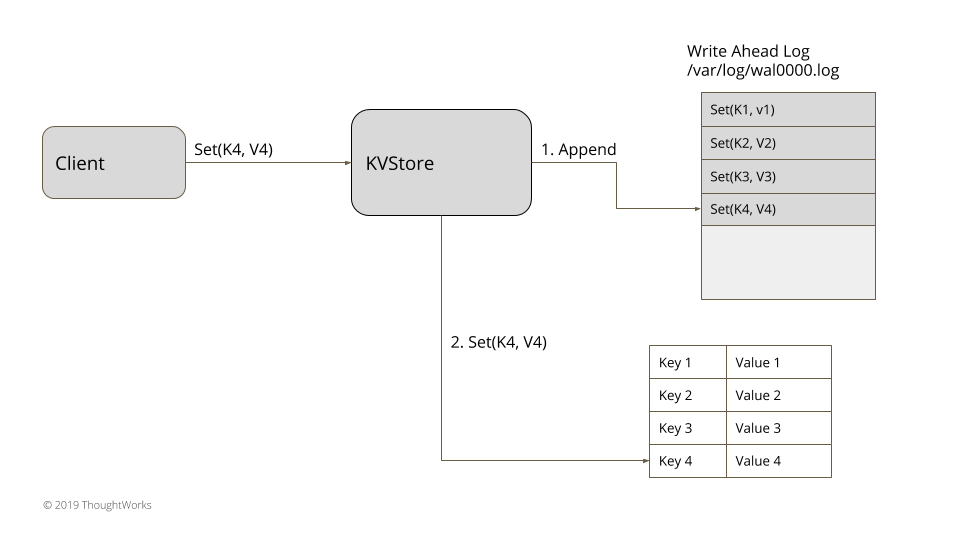
将每次状态变化作为命令存储在磁盘上的文件中。服务器进程维护一份单独的日志,并按顺序追加,这简化了重启时的日志处理和后续操作(日志以命令的形式追加)。每个日志被分配一个唯一的标识符,用于辅助实现一些其他队日志的操作比如 Segmented Log 或者通过 Low-Water Mark 清理日志,而日志的更新可以通过 Singular Update Queue 来实现。
通常日志条目(log entry)结构如下:
type WALEntry struct {
entryID int
data []byte
entryType EntryType
timestamp time.Time
}
日志文件会在进程每次重新启动时被读取,通过回放所有日志条目来恢复状态。
设想一个简单的内存中键值对存储:
type KVStore struct {
KV map[string]string
wal *WAL
}
func (s *KVStore) Put(key, value string) error {
if err := s.appendLog(key, value); err != nil {
return err
}
s.KV[key] = value
}
func (s *KVStore) appendLog(key, value string) error {
return s.wal.writeEntry()
}
put 操作以命令表示,在更新内存中的 map 前要先被序列化并存储到日志中。
type SetValueCommand struct {
key string
value string
attachLease string
}
func NewSetValueCommand(key, value, attachLease string) *SetValueCommand {
return &SetValueCommand{
key: key,
value: value,
attachLease: attachLease,
}
}
func (c *SetValueCommand) Serialize(writer io.Writer) error {
b := bufio.NewWriter(writer)
b.Write([]byte(SetValueType + "\n"))
b.Write([]byte(c.key + "\n"))
b.Write([]byte(c.value + "\n"))
b.Write([]byte(c.attachLease + "\n"))
if err := b.Flush(); err != nil {
return err
}
return nil
}
func Deserialize(reader io.Reader) (*SetValueCommand, error) {
b := bufio.NewReader(reader)
_, _, err := b.ReadLine()
keyBytes, _, err := b.ReadLine()
valueBytes, _, err := b.ReadLine()
leaseBytes, _, err := b.ReadLine()
if err != nil {
return nil, err
}
return NewSetValueCommand(string(keyBytes), string(valueBytes), string(leaseBytes)), nil
}
这就确保了只要 put 方法返回成功,即使持有 KVStore 的进程崩溃,它的状态就可以通过在启动时读取日志文件来恢复。
type KVStore struct {
KV map[string]string
wal *WAL
}
func NewKVStore(config Config) (*KVStore, error) {
store := &KVStore{
KV: map[string]string{},
wal: writeAheadLog.openWAL(config),
}
if err := store.applyLog(); err != nil {
return nil, err
}
return store, nil
}
func (s *KVStore) applyLog() error {
walEntries := s.wal.readAll()
return s.applyEntries(walEntries)
}
func (s *KVStore) applyEntries(walEntries []WALEntry) error {
for _, entry := walEntries {
cmd, err := Deserialize(entry)
if err != nil {
return err
}
s.KV[setValueCommand.key] = setValueCommand.value
}
return nil
}
func (s *KVStore) initialiseFromSnapshot(snapShot SnapShot) {
return s.PutAll(snapShot.deserializeState())
}
func (s *KVStore) PutAll(state map[string]string) {
for key, value := range state {
s.KV[key] = value
}
}
Segmented Log
单一的日志文件体积会越来越大并在启动读取时成为性能瓶颈。要定期处理过期日志,但对一个巨大的文件执行清理操作是很难实现的。
解决方案
将单个日志分成多个段,在日志文件达到限定的大小后会滚动。
writeEntry(entry WALEntry) {
maybeRoll()
return openSegment.WriteEntry(entry)
}
func mayboRoll() {
if openSegment.Size() > config.GetMaxLogSize() {
openSegment.Flush()
SortedSavedSegments = append(SortedSavedSegments, openSegment)
lastID := openSegment.GetLastLogEntryID();
openSegment = WALSegment.open(lastID, config.GetWALDir())
}
}
日志分段的难点在于如何将逻辑日志偏移量映射至分段的日志文件。有两种方法:
- 每份日志段文件的名字由统一的前缀和偏移量生成。
- 每个日志序列号被分成两个部分,文件名和传输偏移量。
const (
LogPrefix = "demo"
LogSuffix = ".log"
)
func CreateFileName(startIndex int) string {
return LogPrefix + "_" + strconv.Itoa(startIndex) + LogSuffix
}
func GetBaseOffsetFromFileName(fileName string) (int, error) {
nameAndSuffix := strings.Split(fileName, LogSuffix)
prefixAndOffset := strings.Split(nameAndSuffix[0], "_")
if prefixAndOffset[0] == LogPrefix {
return strconv.Atoi(prefixAndOffset[1])
}
return -1, errors.New("illegal file name")
}
读取操作分成两步。有了偏移量,从日志段中读取所有日志记录。
func ReadFrom(startIndex int) []WALEntry {
segments := getAllSegmentsContainingLogGreaterThan(startIndex)
return readWALEntriesFrom(startIndex, segments)
}
func getAllSegmentsContainingLogGreaterThan(startIndex int) []WALSegment {
segments := []WALSegment{}
for i := len(SortedSavedSegments) - 1; i >= 0; i-- {
walSegment := SortedSavedSegments[i]
segments = append(segments, walSegment)
if walSegment.GetBaseOffset() <= startIndex {
break
}
}
if openSegment.GetBaseOffset() <= startIndex {
segments = append(segments, openSegment)
}
return segments
}
实现
Low-Water Mark
预写日志会将每一次更新都持久化,理论上随着时间的流逝是无限大的。虽然 Segmented Log 允许在某个时间处理更小的文件,但是使用的磁盘空间还是越来越大的。
解决方案
要有一种机制来安全地丢弃日志,这种机制提供了最低的偏移量或者低水位线,在那个点之前的日志都可以丢掉。这就需要单开一条线程在后台跑一个任务,持续检查哪部分日志可以丢弃并删除磁盘上的文件。
1. 基于快照的 Low-Water Mark
绝大多数像 Zookeeper 和 etcd 这样的一致性实现使用快照机制。在这种实现中,存储引擎会定期拍快照。与快照一起存储的还有被成功应用的日志索引。
func (s *KVStore) TakeSnapShot() SnapShot {
snapShotTakenAtLogIndex := wal.GetLastLogEntryID()
return NewSnapShot(s.serializeState(s.KV), snapShotTakenAtLogIndex)
}
当快照被成功持久化至磁盘,log manager 就可以给出低水位线来丢弃不必要的日志:
func GetSegmentsBefore(snapShotIndex int) []WALSegment {
markedForDeletion := []WALSegment{}
sortedSavedSegments := wal.SortedSavedSegments
for _, segment := range sortedSavedSegments {
markedForDeletion = append(markedForDeletion, segment)
}
return markedForDeletion
}
2. 基于时间的 Low-Water Mark
在某些系统中,日志并非用于更新系统状态,那么日志就可以在给定的时间窗口之后丢弃。举个栗子,Kafka 中日志只维护七周,所有超过七周的日志都会被丢弃。这种实现中,每个日志条目在创建时都包含了时间戳。log cleaner 会检查每个日志段的最近条目,并删掉超过时间窗口的日志段。
func GetSegmentsPast(logMaxDuration time.Duration) []WALSegment {
now := time.Now()
markedForDeletion := []WALSegment{}
sortedSavedSegments := wal.SortedSavedSegments
for _, segment := range sortedSavedSegments {
if segment.GetLastLogEntryTimeStamp().Before(time.Now().Add(-logMaxDuration)) {
markedForDeletion = append(markedForDeletion, segment)
}
}
return markedForDeletion
}
实现细节
实现日志时还有一些关键点需要考虑。确保日志条目被正确地持久化至磁盘非常重要。所有编程语言提供的文件处理的库都有强制将文件变化落盘(flush)的机制。在使用落盘机制时也要权衡。
将所有日志都落盘无疑提供了最强的持久性(这也是该日志的主要目的),但是会严重影响到性能,很快就会成为瓶颈。如果落盘延迟或者异步,会提高性能表现但是进程在日志条目落盘前崩溃就有丢失数据的风险。大多数实现使用了批处理技术,来限制落盘操作的影响。
另一个要考虑的点是确保在读取日志时能够识别损坏的日志文件。通常在写日志的时候带上 CRC 记录,用于在读取日志时校验。
预写日志只能被追加(append only)。因为这种天性,在客户端通讯失败并重试的情况下,日志条目就会重复。当日志条目被应用时,需要保证重复被忽略。如果最终状态是类似 HashMap 之类的东西,对同一个 key 的更新是等价的,那就无所谓了;相反地就要用一些机制来用唯一标识符标记每一条请求并检测重复。