systemd CPU 高使用率排查
Mar 1, 2023 00:00 · 3552 words · 8 minute read

一句话描述问题现象:Kubernetes 集群中某节点 ssh 连接、命令执行缓慢。
节点规格 24C125G
uptime 查看服务器负载:
$ uptime
15:54:45 up 15 days, 5:09, 6 users, load average: 12.26, 11.89, 11.99
服务器负载相对于节点规格(25C)来说还可以。
top 查看 CPU 使用率(数据已经过筛选):
$ top
Tasks: 533 total, 5 running, 516 sleeping, 0 stopped, 12 zombie
%Cpu(s): 6.8 us, 15.9 sy, 0.5 ni, 75.4 id, 0.2 wa, 0.5 hi, 0.6 si, 0.0 st
MiB Mem : 128621.5 total, 77180.8 free, 15878.6 used, 35562.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 111628.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 250872 22816 7968 R 97.7 0.0 794:03.96 systemd
12797 root 21 1 101984 21384 8196 R 96.7 0.0 745:47.52 systemd
534216 root 20 0 1154216 12104 7712 R 77.1 0.0 0:02.36 runc
534242 root 20 0 1080740 10624 7652 R 76.8 0.0 0:02.35 runc
systemd 和 runc 进程 CPU 使用率非常高,接近 100%。
pidstat 采样进程 CPU 使用率明细(数据已经过筛选):
$ pidstat 1
21:34:08 UID PID %usr %system %guest %wait %CPU CPU Command
21:34:09 0 1 0.00 98.00 0.00 1.00 98.00 1 systemd
21:34:09 0 12797 0.00 100.00 0.00 0.00 100.00 19 systemd
21:34:09 0 541439 1.00 82.00 0.00 0.00 83.00 18 runc
21:34:09 UID PID %usr %system %guest %wait %CPU CPU Command
21:34:10 0 1 4.00 93.00 0.00 0.00 97.00 1 systemd
21:34:10 0 12797 11.00 89.00 0.00 0.00 100.00 19 systemd
21:34:10 0 541439 2.00 100.00 0.00 0.00 102.00 18 runc
21:34:12 UID PID %usr %system %guest %wait %CPU CPU Command
21:34:13 0 1 58.00 38.00 0.00 0.00 96.00 1 systemd
21:34:13 0 12797 60.00 37.00 0.00 1.00 97.00 19 systemd
21:34:13 0 541525 2.00 99.00 0.00 0.00 101.00 18 runc
发现 systemd 和 runc 进程内核态 CPU 使用率非常高,可能系统调用有问题或繁忙。
vmstat 查看 CPU 上下文切换情况:
$ vmstat 1
vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
6 0 0 78838608 6789452 29598068 0 0 62 251 0 1 5 3 93 0 0
3 0 0 78840864 6789708 29597936 0 0 4 8736 24948 36662 6 15 78 0 0
3 0 0 78837712 6789708 29598172 0 0 0 2732 24817 36829 9 12 79 0 0
4 0 0 78837336 6789708 29598384 0 0 8 9792 25053 36963 11 10 78 0 0
3 0 0 78835760 6789716 29598528 0 0 0 4608 24964 38041 11 11 78 0 0
4 0 0 78832176 6790096 29599712 0 0 4 7188 34633 65779 17 12 71 0 0
4 0 0 78819328 6790032 29599856 0 0 1024 5988 27763 47631 10 14 75 0 0
6 0 0 78825392 6790160 29600008 0 0 0 5340 26344 41418 6 16 78 0 0
6 0 0 78827488 6790160 29600088 0 0 8 3152 24837 35637 17 15 68 0 0
4 0 0 78821504 6790160 29600800 0 0 0 5464 27049 44198 9 20 71 0 0
5 0 0 78815976 6790160 29600936 0 0 8 9416 28257 44776 7 19 74 0 0
4 0 0 78812192 6790160 29601100 0 0 0 11324 28447 44089 12 14 74 0 0
5 0 0 78811568 6790160 29601200 0 0 0 1428 25098 38099 12 15 74 0 0
3 0 0 78818696 6790224 29601444 0 0 0 6352 26032 39201 11 14 75 0 0
5 0 0 78819776 6790224 29601592 0 0 0 1444 21625 32205 10 11 80 0 0
4 0 0 78817176 6790224 29601764 0 0 4 6772 24915 36129 6 15 78 0 0
4 0 0 78815776 6790224 29601880 0 0 0 5356 26872 40817 8 14 79 0 0
3 0 0 78813280 6790488 29601764 0 0 0 5708 23786 36510 5 15 80 0 0
4 1 0 78806368 6790304 29602040 0 0 12 11136 26597 37319 10 13 76 0 0
3 0 0 78811376 6790560 29602632 0 0 0 8324 25547 40457 12 11 77 0 0
3 0 0 78811112 6790560 29603584 0 0 0 3584 32293 62859 16 11 73 0 0
5 0 0 78802024 6790496 29603796 0 0 4 16548 27602 46996 12 12 76 0 0
上下文切换数(cs)尚可;内核态代码 CPU 时长(sy)远大于用户态代码 CPU 时长(us),这点很不正常。
利用 htop 找出不正常的 runc 进程:
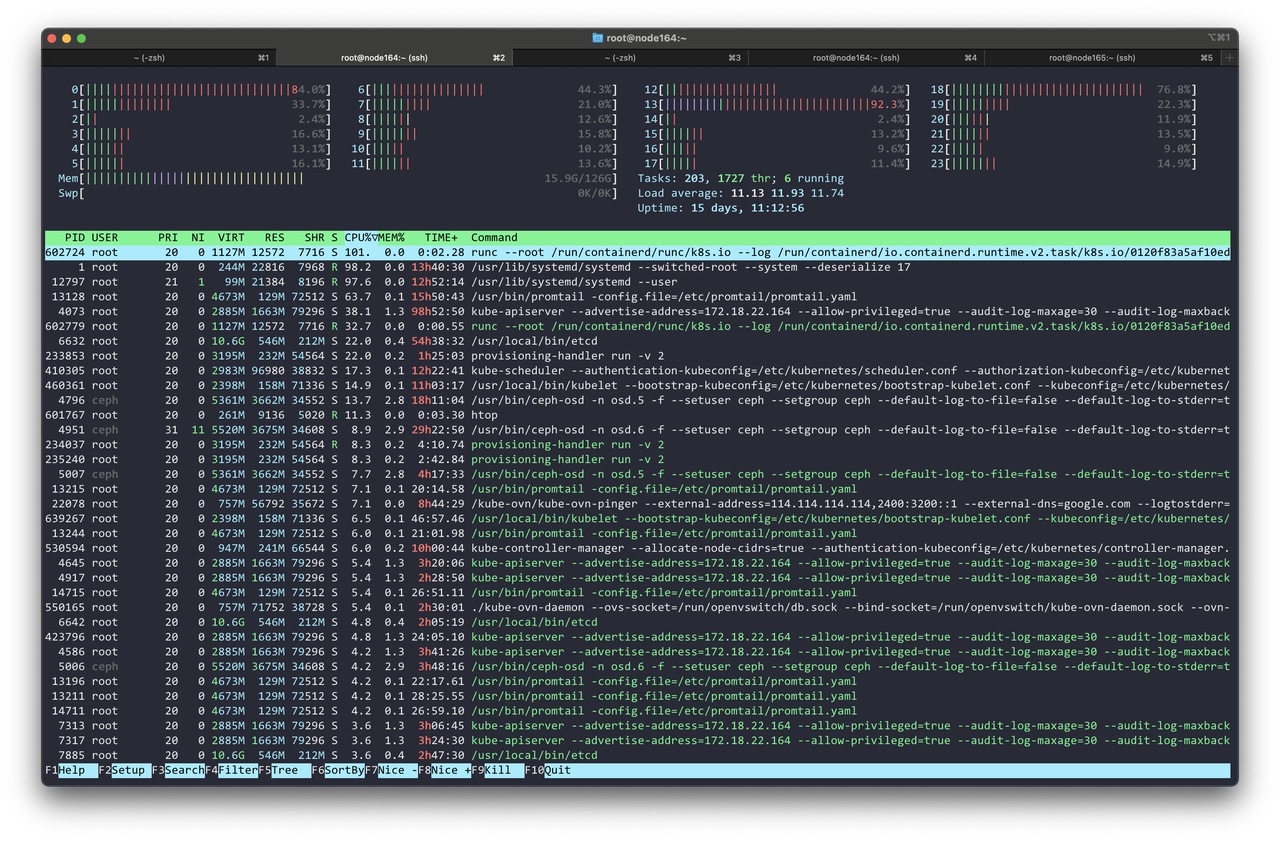
$ ps -ef | grep "runc --root /run/containerd/runc/k8s.io --log /run/containerd/io.containerd.runtime.v2.task/k8s.io/0120f83a5af10ed5c0e1e8cce23711be1b835fb21ea982ec50608be6f6eb91f8/log.json"
root 611998 18772 31 22:02 ? 00:00:00 runc --root /run/containerd/runc/k8s.io --log /run/containerd/io.containerd.runtime.v2.task/k8s.io/0120f83a5af10ed5c0e1e8cce23711be1b835fb21ea982ec50608be6f6eb91f8/log.json --log-format json exec --process /tmp/runc-process3597893812 --detach --pid-file /run/containerd/io.containerd.runtime.v2.task/k8s.io/0120f83a5af10ed5c0e1e8cce23711be1b835fb21ea982ec50608be6f6eb91f8/5240d4f9a8fcb5884e1d08635554f04aa303574332de19502f6efc8d61b0e954.pid 0120f83a5af10ed5c0e1e8cce23711be1b835fb21ea982ec50608be6f6eb91f8
runc 进程是瞬时的,其父进程的 pid 为 18772,通过 pstree 查看其父进程(containerd-shim)进程树:
$ pstree -p 18772 -s
systemd(1)───containerd-shim(18772)─┬─monitor(20444)───ovsdb-server(20445)
├─monitor(20488)───ovs-vswitchd(20489)─┬─{ovs-vswitchd}(20538)
│ ├─{ovs-vswitchd}(20544)
│ ├─{ovs-vswitchd}(20954)
│ ├─{ovs-vswitchd}(20957)
│ ├─{ovs-vswitchd}(20962)
│ ├─{ovs-vswitchd}(20968)
│ ├─{ovs-vswitchd}(20973)
│ ├─{ovs-vswitchd}(20977)
│ ├─{ovs-vswitchd}(20982)
│ ├─{ovs-vswitchd}(20991)
│ ├─{ovs-vswitchd}(20993)
│ ├─{ovs-vswitchd}(20995)
│ ├─{ovs-vswitchd}(20997)
│ ├─{ovs-vswitchd}(20999)
│ ├─{ovs-vswitchd}(21000)
│ ├─{ovs-vswitchd}(21001)
│ ├─{ovs-vswitchd}(21002)
│ ├─{ovs-vswitchd}(21003)
│ ├─{ovs-vswitchd}(21004)
│ ├─{ovs-vswitchd}(21005)
│ ├─{ovs-vswitchd}(21006)
│ ├─{ovs-vswitchd}(21007)
│ ├─{ovs-vswitchd}(21008)
│ ├─{ovs-vswitchd}(21009)
│ ├─{ovs-vswitchd}(21010)
│ ├─{ovs-vswitchd}(21011)
│ ├─{ovs-vswitchd}(21012)
│ └─{ovs-vswitchd}(21013)
├─monitor(20674)───ovn-controller(20678)─┬─{ovn-controller}(20681)
│ ├─{ovn-controller}(20682)
│ └─{ovn-controller}(20685)
├─pause(18917)
├─runc(618416)─┬─{runc}(618419)
│ ├─{runc}(618420)
│ ├─{runc}(618421)
│ ├─{runc}(618422)
│ └─{runc}(618428)
├─start-ovs.sh(19478)───tail(20924)
├─{containerd-shim}(18773)
├─{containerd-shim}(18774)
├─{containerd-shim}(18775)
├─{containerd-shim}(18777)
├─{containerd-shim}(18779)
├─{containerd-shim}(18780)
├─{containerd-shim}(18781)
├─{containerd-shim}(18782)
├─{containerd-shim}(18784)
├─{containerd-shim}(18785)
├─{containerd-shim}(19285)
└─{containerd-shim}(42068)
刷新进程树发现不断有新的 runc 进程被拉起,pid 越来越大。
runc 进程频繁启动的是 ovs-ovn Pod 的健康检查脚本:
readinessProbe:
exec:
command:
- bash
- -c
- LOG_ROTATE=true /kube-ovn/ovs-healthcheck.sh
failureThreshold: 3
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 45
猜测源源不断的 runc 进程影响到了 systemd 进程,导致其 CPU 高使用率。而 pid 为 18772 的 containerd-shim 进程后面正是 ovs-ovn DaemonSet Pod,于是将其重启。但重启后 systemd CPU 使用率并未下降,ovs-ovn Pod 中仍然有 runc 进程不断被拉起。
strace 分析 systemd 系统调用:
$ strace -c -p 1
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
45.57 1.966737 115 17083 read
19.73 0.851359 10 79828 openat
13.75 0.593647 7 79827 close
12.06 0.520498 6 75624 fstat
3.02 0.130164 7 16804 getrandom
2.98 0.128699 15 8403 readlinkat
1.77 0.076212 18 4201 access
1.05 0.045184 10 4204 stat
0.08 0.003403 12 279 poll
0.00 0.000069 17 4 lstat
0.00 0.000016 16 1 readlink
0.00 0.000007 7 1 prctl
0.00 0.000006 6 1 geteuid
0.00 0.000005 5 1 getuid
0.00 0.000005 5 1 getgid
0.00 0.000005 5 1 getegid
------ ----------- ----------- --------- --------- ----------------
100.00 4.316016 15 286263 total
相当多的 read 系统调用。
perf 采样 60s 并利用 brendangregg/FlameGraph 绘制出 systemd 进程的火焰图:
$ perf record -F 99 -p 1 -g -- sleep 60
$ perf script > out.perf
$ stackcollapse-perf.pl out.perf > out.perf-folded
$ flamegraph.pl out.perf-folded > perf-kernel.svg
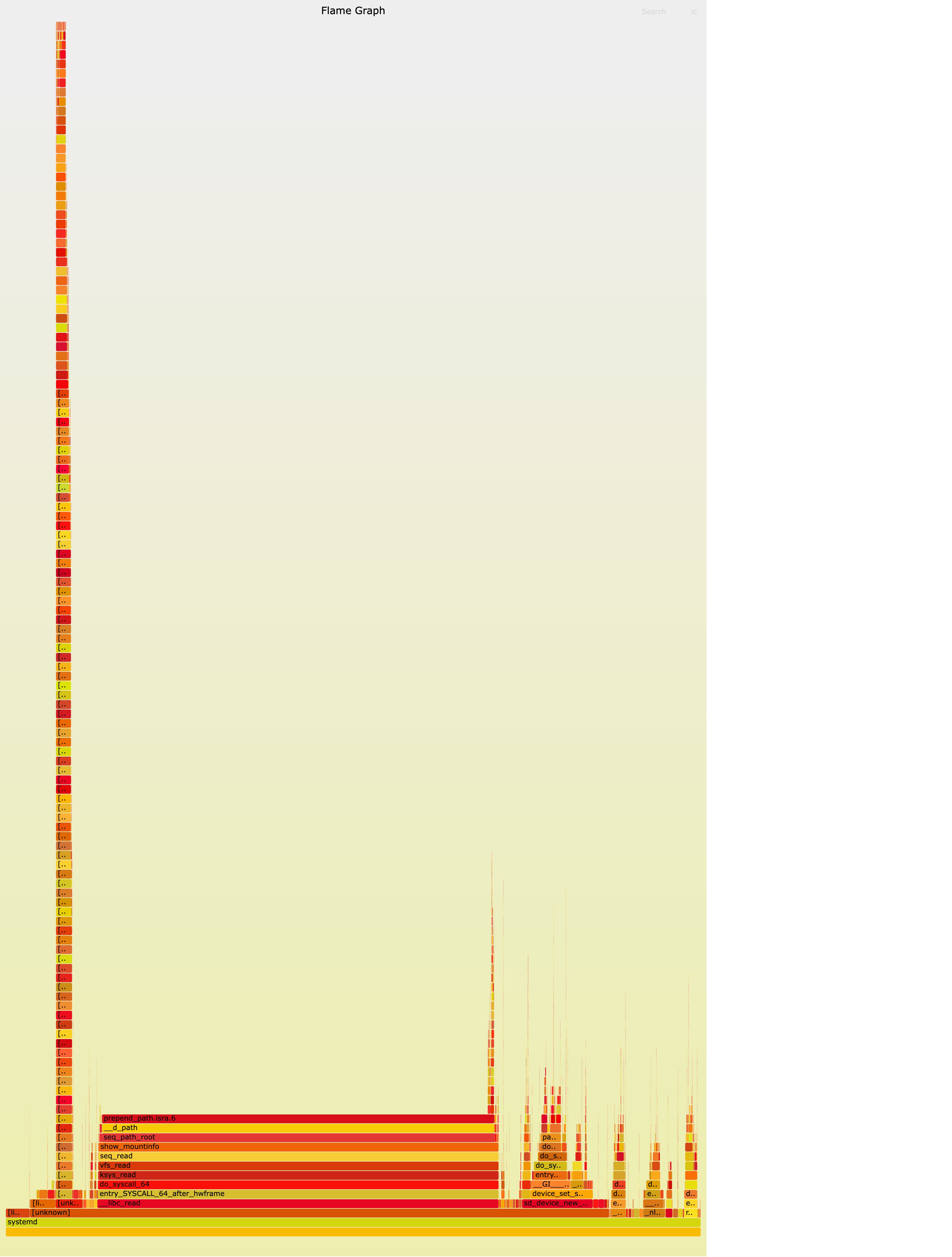
通过火焰图得知确实 Linux 内核态代码中的 show_mountinfo 函数占用了 systemd 进程的绝大部分 CPU 时间。
与 https://www.cnblogs.com/yaohong/p/16046670.html#_label3 一文所描述的猜想基本符合,ovs-ovn Pod 频繁的健康检查要去拉起 runc,导致 systemd 总是在遍历挂载点。看一下挂载点数量:
$ mount | wc -l
8366
mount 命令过了好几秒钟才有输出,挂载点多得不正常。绝大多数都是同一个挂载点:
$ grep "/var/lib/kubelet/device-plugins" /proc/mounts | wc -l
8191
$ grep "/var/lib/kubelet/device-plugins" /proc/mounts | head
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sda2 /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
从 /var/lib/kubelet/device-plugins 路径本身下手,经过排查发现某个 DaemonSet 同时挂载了宿主机的 /var/lib/kubelet 与 /var/lib/kubelet/device-plugins 路径:
volumes:
- hostPath:
path: /var/lib/kubelet/device-plugins
type: ""
name: device-plugin
- hostPath:
path: /var/run/libvirt
type: ""
name: libvirt
- hostPath:
path: /var/log
type: ""
name: log
- hostPath:
path: /var/run/kubevirt-ephemeral-disks
type: DirectoryOrCreate
name: ephemeral
- hostPath:
path: /var/run/kubevirt-private
type: DirectoryOrCreate
name: private
- hostPath:
path: /var/run/openvswitch
type: ""
name: openvswitch
- hostPath:
path: /var/lib/kubelet
type: ""
name: kubelet-root-dir
- configMap:
defaultMode: 420
name: ph-config
name: config
而 /var/lib/kubelet/device-plugins 正是 /var/lib/kubelet 的子路径,这里形成嵌套。
不断重建 DaemonSet Pod 的同时通过 bcc mountsnoop 工具观察 mount/umount 系统调用:
$ ./tools/mountsnoop.py
runc:[2:INIT] 147637 147637 runc 147627 4026535336 mount("/var/lib/kubelet/device-plugins", "/proc/self/fd/6", "bind", MS_BIND|MS_REC, "") = 0
runc:[2:INIT] 151927 151927 runc 151917 4026535336 mount("/var/lib/kubelet/device-plugins", "/proc/self/fd/6", "bind", MS_BIND|MS_REC, "") = 0
# ...
同时观察挂载点:
$ grep "/var/lib/kubelet/device-plugins" /proc/mounts
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/mapper/rl-root /var/lib/kubelet/device-plugins xfs rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
在 Pod 被删除时并没有 umount /var/lib/kubelet/device-plugins,在新 Pod 创建时又 bind mount /var/lib/kubelet/device-plugins 路径,每 bind mount 一次,挂载点数量以 2n + 1 增长。
进一步分析 Pod 定义,发现容器开启了特权模式:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
securityContext:
privileged: true
image: nginx:1.14.2
ports:
- containerPort: 80
volumeMounts:
- mountPath: /var/lib/kubelet
#mountPropagation: Bidirectional
name: kubelet-root-dir
- mountPath: /var/lib/kubelet/device-plugins
#mountPropagation: Bidirectional
name: device-plugin
volumes:
- hostPath:
path: /var/lib/kubelet/device-plugins
type: ""
name: device-plugin
- hostPath:
path: /var/lib/kubelet
type: ""
name: kubelet-root-dir
数据卷的 mountPropagation 字段设置为 Bidirectional,会导致容器内的 mount 传播回宿主机。
This volume mount behaves the same the HostToContainer mount. In addition, all volume mounts created by the container will be propagated back to the host and to all containers of all pods that use the same volume.
我们测试了以下几种情况:
| /var/lib/kubelet mountPropagation |
/var/lib/kubelet/device-plugins mountPropagation |
容器删除后挂载点是否残留 |
|---|---|---|
| X | X | 否 |
| X | Bidirectional |
否 |
Bidirectional |
X | 是 |
Bidirectional |
Bidirectional |
是 |
如果 Pod 定义中的 volumeMounts 存在嵌套,并且其中的父级目录的 mountPropagation 字段设置为了 Bidirectional,那就会导致子目录的挂载传播到宿主机,并且在容器删除之后也不会被卸载。
修正 DaemonSet Pod 定义并手动 umount /var/lib/kubelet/device-plugins,环境恢复正常。