单一更新队列
Jul 24, 2021 23:00 · 2170 words · 5 minute read

问题
当系统的状态由多个并发的客户端更新时,我们需要安全地更新,一次一个的变更。例如预写日志中的例子,即使多个客户端在并发写,一次只处理一个日志条目。锁,通常被用于防止并发修改,但如果正在写文件,这会阻塞所有其他调用的线程直到任务完成,会大大降低系统的吞吐量和延迟。我们的目标是高效地利用计算资源,同时保证一次执行一个的需求。
解决方案
实现一条工作队列(workqueue)和一条工作线程。多客户端将状态变更提交至队列中,由单线程来处理系统状态修改。在 Golang 自然是通过 goroutine 和 channel 来实现。
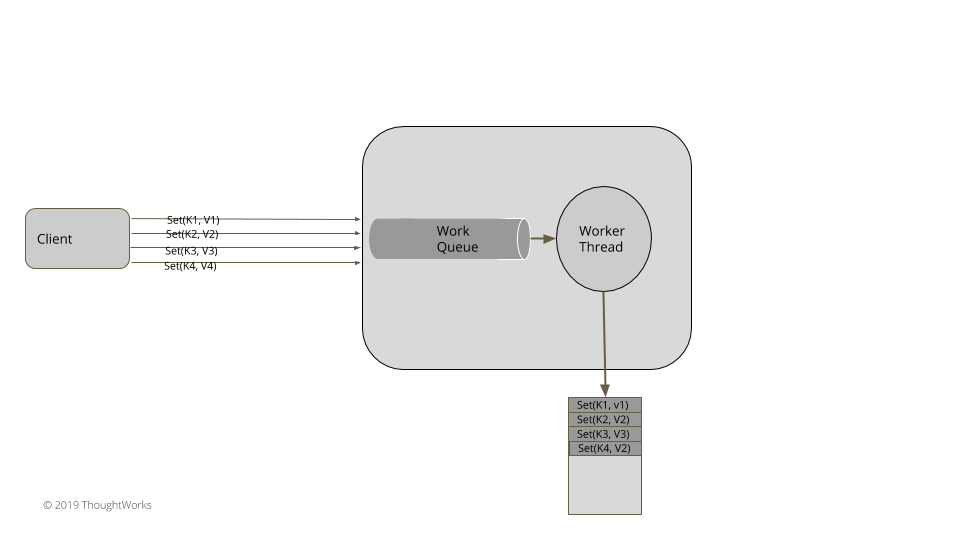
一个典型的 Java 实现:
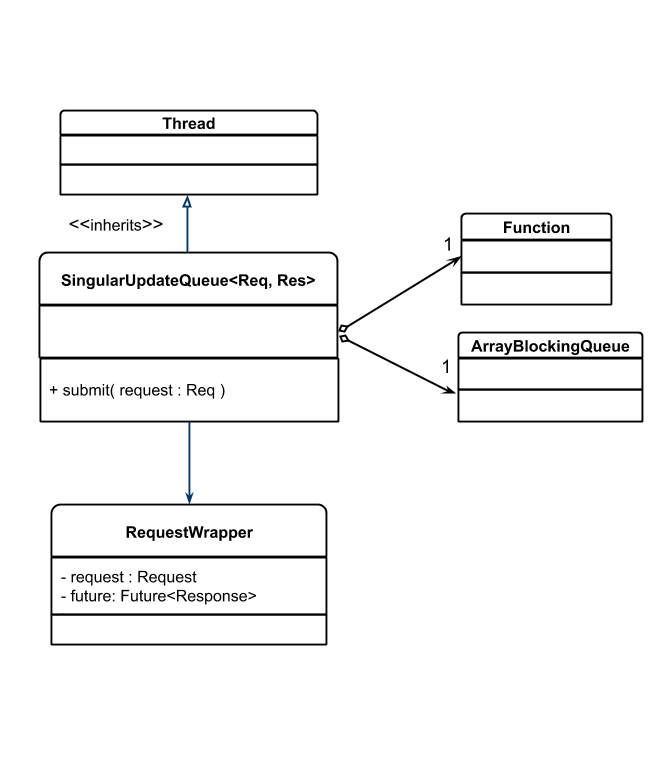
一个 SingularUpdateQueue 类有一条队列和工作函数,继承 java.lang.Thread 以确保单线程执行。
public class SingularUpdateQueue<Req, Res> extends Thread implements Logging {
private ArrayBlockingQueue<RequestWrapper<Req, Res>> workQueue
= new ArrayBlockingQueue<RequestWrapper<Req, Res>>(100);
private Function<Req, Res> handler;
private volatile boolean isRunning = false;
客户端向队列提交请求,队列通过包装器将每个请求包裹进包装类来与一个 future 结合,将 future 返回给客户端,这样当请求最终完成时客户端能够做出反应。
class SingularUpdateQueue…
public CompletableFuture<Res> submit(Req request) {
try {
var requestWrapper = new RequestWrapper<Req, Res>(request);
workQueue.put(requestWrapper);
return requestWrapper.getFuture();
}
catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
class RequestWrapper<Req, Res> {
private final CompletableFuture<Res> future;
private final Req request;
public RequestWrapper(Req request) {
this.request = request;
this.future = new CompletableFuture<Res>();
}
public CompletableFuture<Res> getFuture() { return future; }
public Req getRequest() { return request; }
队列中的元素由单线程处理,队列允许多个并发的生产者向其添加任务。队列的实现应该是线程安全的,不应该在竞争下增加大量开销。执行线程从队列取出请求,一次只处理一个。CompletableFuture 是用任务执行的应答完成的。
class SingularUpdateQueue…
@Override
public void run() {
isRunning = true;
while(isRunning) {
Optional<RequestWrapper<Req, Res>> item = take();
item.ifPresent(requestWrapper -> {
try {
Res response = handler.apply(requestWrapper.getRequest());
requestWrapper.complete(response);
} catch (Exception e) {
requestWrapper.completeExceptionally(e);
}
});
}
}
class RequestWrapper…
public void complete(Res response) {
future.complete(response);
}
public void completeExceptionally(Exception e) {
e.printStackTrace();
getFuture().completeExceptionally(e);
}
当从队列读取时加一个超时是很管用的,防止永久阻塞。通过将 isRunning 设置成 false 如有必要退出线程,这样当队列为空时就不会无限阻塞工作线程。所以我们使用带超时的 poll 方法。这使得我们可以干净利落地关闭执行线程。
class SingularUpdateQueue…
private Optional<RequestWrapper<Req, Res>> take() {
try {
return Optional.ofNullable(workQueue.poll(300, TimeUnit.MILLISECONDS));
} catch (InterruptedException e) {
return Optional.empty();
}
}
public void shutdown() {
this.isRunning = false;
}
举个栗子,服务器处理多个客户端的请求并更新预写日志,就可以使用单一更新队列技术。
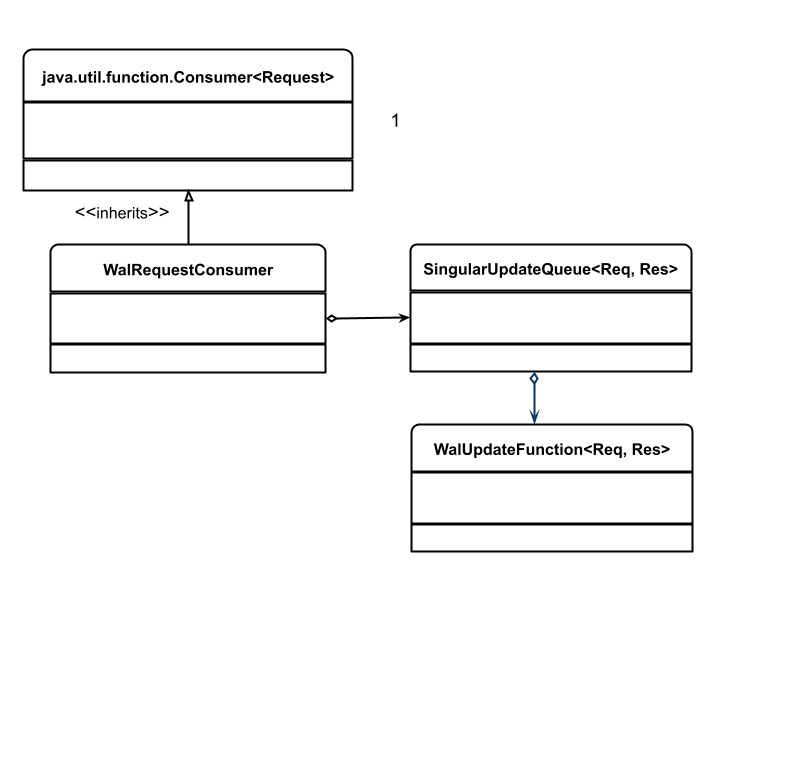
在这个例子中,我们为 WAL 使用了一个消费者。这个消费者是一个单例,它来控制对日志数据结构的访问。消费者要将每个请求放入日志并返回应答。应答消息必须要在消息被写入日志后才能发送。于是我们使用 SingularUpdateQueue 来确保这些操作有一个明确的顺序。
public class WalRequestConsumer implements Consumer<Message<RequestOrResponse>> {
private final SingularUpdateQueue<Message<RequestOrResponse>, Message<RequestOrResponse>> walWriterQueue;
private final WriteAheadLog wal;
public WalRequestConsumer(Config config) {
this.wal = WriteAheadLog.openWAL(config);
walWriterQueue = new SingularUpdateQueue<>((message) -> {
wal.writeEntry(serialize(message));
return responseMessage(message);
});
startHandling();
}
private void startHandling() { this.walWriterQueue.start(); }
消费者的 accept 方法接收消息,将它们入队并在每个消息被处理后发送一个响应。这个方法在调用者的线程上运行,这就允许诸多调用者同时调用 accept。
@Override
public void accept(Message message) {
CompletableFuture<Message<RequestOrResponse>> future = walWriterQueue.submit(message);
future.whenComplete((responseMessage, error) -> {
sendResponse(responseMessage);
});
}
队列的选项
队列数据结构非常重要,在 JVM 中,有多种可供选择的数据结构:
-
ArrayBlockingQueue(Kafka 的请求队列中使用)
名副其实,这是一个基于数组的阻塞队列。当需要固定边界的队列时可以使用 ArrayBlockingQueue。一旦队列填满,生产者将阻塞。当消费者速度缓慢而生产者速度很快时很有用。
-
ConcurrentLinkedQueue 和 ForkJoinPool(Akka Actors 邮箱的实现中使用)
没有消费者等待生产者的场景中可以使用 ConcurrentLinkedQueue,但也有些协调器可以做到在任务入队至 ConcurrentLinkedQueue 时才安排消费者。
-
LinkedBlockingDeque(Zookeeper 和 Kafka 的应答队列所使用)
最主要在无限制入队中使用,不会阻塞生产者。要谨慎选择,如果没有实现 backpressure 技术,队列可能会迅速填满,耗光所有内存。
-
环形缓冲区(LMAX Disruptor 使用)
有些场景对延迟很敏感。ArrayBlockingQueue 队列在处理阶段之间的复制操作会增加延迟,这是不可接受的。环形缓冲区可用于在阶段之间传递任务。
使用 channel 和 goroutine
这对于支持轻量级线程和通道概念的语言或库(比如 Golang 和 Kotlin)来说是很自然的。所有的请求被传递到单一的 channel 被处理,还有一个 goroutine 在处理所有的消息来更新状态。然后应答被写入另一个 channel,并由另一条 goroutine 发回客户端。从下面的代码可以看到,更新键值对的请求被传递到一个共享的请求 channel。
func (s *Server) putKV(w http.ResponseWriter, r *http.Request) {
kv, err := s.readRequest(r, w)
if err != nil {
log.Panic(err)
return
}
request := &requestResponse{
request: kv,
responseChannel: make(chan string),
}
s.requestChannel <- request
response := s.waitForResponse(request)
w.Write([]byte(response))
}
请求由单条 groutine 处理来更新所有状态。
func (s *Server) Start() error {
go s.serveHttp()
go s.singularUpdateQueue()
return nil
}
func (s *Server) singularUpdateQueue() {
for {
select {
case e := <-s.requestChannel:
s.updateState(e)
e.responseChannel <- buildResponse(e)
}
}
}
背压(Backpressure)
当工作队列被用于线程间的通讯时,背压是一个要关注的点。在消费者的速度很慢而生产者的速度飞快这样的案例中,队列很快就会被填满,内存有可能被耗尽。一般,如果队列满了,发送者会阻塞。例如,java.util.concurrent.ArrayBlockingQueue 有两个方法来添加元素。如果数组满了,put 方法将阻塞生产者;而 add 方法会抛出 IllegalStateException 而不是阻塞生产者。所以要仔细阅读文档,在 ArrayBlockingQueue 的案例中,应该用 put 方法来阻塞发送者,通过阻塞提供“背压”。也可以使用 reactive-streams 这样的框架来帮助实现一个更复杂的从生产者到消费者的背压机制。
案例
所有像 ZooKeeper(ZAB) 和 etcd(RAFT)这类一致性实现都要以严格的顺序处理请求,一次一个。他们使用了相似的代码结构。
- ZooKeeper 通过单线程的请求处理器实现了请求处理的流水线。
- etcd 这类基于 Golang 的实现有条单独的 goroutine,从请求 channel 接收数据来更新状态。
- Kafka 的控制器需要根据来自 ZooKeeper 的多个并发事件更新状态,在单线程中处理这些事件。