Schemaless 数据库的设计二
Oct 1, 2022 19:30 · 2341 words · 5 minute read

原文:https://www.uber.com/blog/schemaless-part-two-architecture/
这是 Uber Schemaless 数据库三部曲的第二篇,介绍 Uber Schemaless 数据库的架构。
简介
简而言之,Schemaless 是一个可扩展且高可用的数据库。数据的原子实体被成为单元格(cell),是不可变的,一旦写入就不能被覆写了。单元格由行键、列名和 ref key 引用。通过写入新版本(更高的 ref key)的数据来更新单元格内容。Schemaless 不强制数据按照任何格式来存储,由此得名。从 Schemaless 的视角来看,它只存储 JSON 对象。Schemaless 支持在单元格字段之上的二级索引和最终一致性。
架构
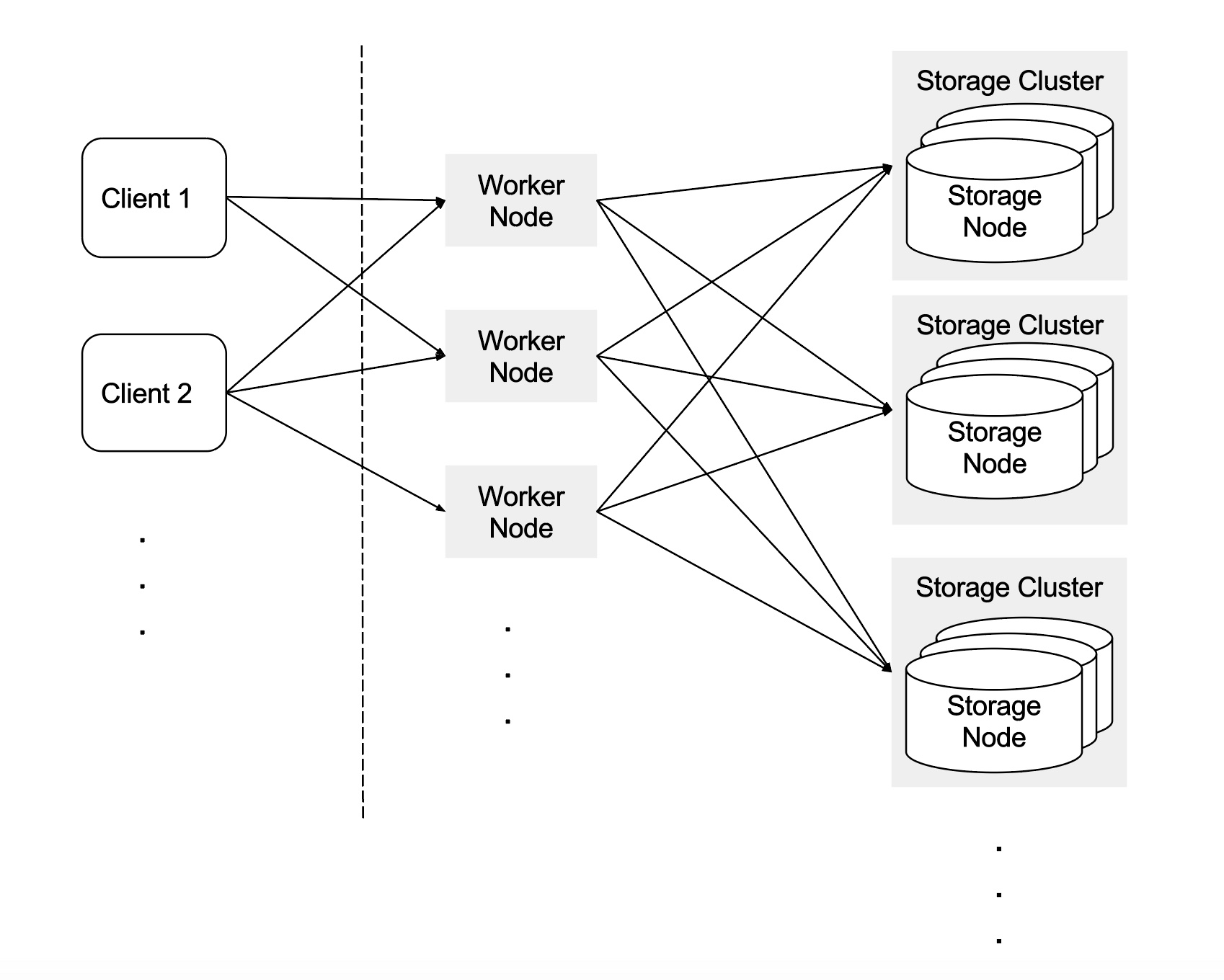
Schemaless 有两种节点:工作(worker)和存储(storage)节点,部署在相同或分开的物理/虚拟机上。工作节点接收客户端的请求,将请求扇出至存储节点,并聚合结果。在同一个存储节点上检索单个或多个单元格是很快的。我们分成两种节点类型,以便独立地对每个部分扩展。
-
工作节点
Schemaless 客户端通过 HTTP 协议与工作节点通信,工作节点将请求路由至存储节点,如有必要聚合来自存储节点的结果,并处理后台任务。为了应对缓慢或故障的工作节点,客户端 lib 会尝试其他主机并重试请求。
-
存储节点
我们将数据集切分至固定数量(通常配置成 4096)的分片中,然后映射至存储节点。一个单元格根据行键映射至分片。每个分片在存储节点上都是多副本的。这些存储节点组成一个存储集群,每个集群由一个主节点群和两个从节点群(副本)组成。从节点分部至多个数据中心来提供数据冗余容灾。
读写请求
当客户端访问 Schemaless,读取单元格或查询索引时,工作节点能够从集群中的任意存储节点读取数据。也可以通过请求指定从主或从存储节点读取;默认从主节点群读取,这意味着客户端一定能够看到写它发送的请求的结果。写请求一定会被发送至集群的主节点。在主节点更新数据后,副本会异步地去更新。
故障处理
分布式存储系统有趣在它们是如何处理故障的,比如一个存储节点未应答请求。Schemaless 被设计为尽可能减小存储节点读写请求失败的影响。
读请求
主从架构意味着只要集群中有一个节点可用,就能为读取请求提供服务。如果主节点是可用的,Schemaless 总是能够返回最新的数据;如果主节点不可用,有些数据可能还未同步至从节点,所以就有可能返回过期的数据。在生产中,主从复制的延迟很小,所以从节点的数据大概率是最新的。工作节点利用断路器模式探测存储节点是否有问题,将读请求发送至其他节点。
写请求
从节点挂掉不会影响写入;写请求总会被发送到主节点。如果有主节点挂了,Schemaless 仍会接收写请求,但持久化至其他主节点的磁盘上。有点像 Dynamo 和 Cassandra 的 hinted handoff。写到其他主节点意味着随后的读请求在主节点恢复前(或从节点被提升为主节点)无法读到本次写入。实际上 Schemaless 总是会写到其他主节点来处理异步复制中的故障。我们称之为缓冲写。
单节点写入有利有弊。一个好处是形成了顺序。这对 Schemaless 触发器(异步处理框架)来说非常重要,从任意节点的任意分片读取数据能够保证相同的处理顺序。单元格的写入顺序在集群中的所有节点都是一样的。
单主节点最大的问题是一旦宕机,缓冲写是无法被读取到的。Schemaless 会告知客户端主节点挂了,客户端知道此时被写入的单元格是不能立即被读取到的。
缓冲写
因为 Schemaless 使用 MySQL 的异步复制,如果主节点接收到写请求,在它同步至从节点前就失败了(比如硬盘故障),写入就会丢失。为了解决这个问题我们使用了缓冲写技术。缓冲写最小化了丢数据的几率。如果主节点挂了,虽然数据一时半会读取不了,但至少持久化下来了。
通过缓冲写,当一个工作节点收到一条写请求,将请求先后发送至两个集群:主集群和次集群。只有两个都成功客户端才会收到写入成功的应答。
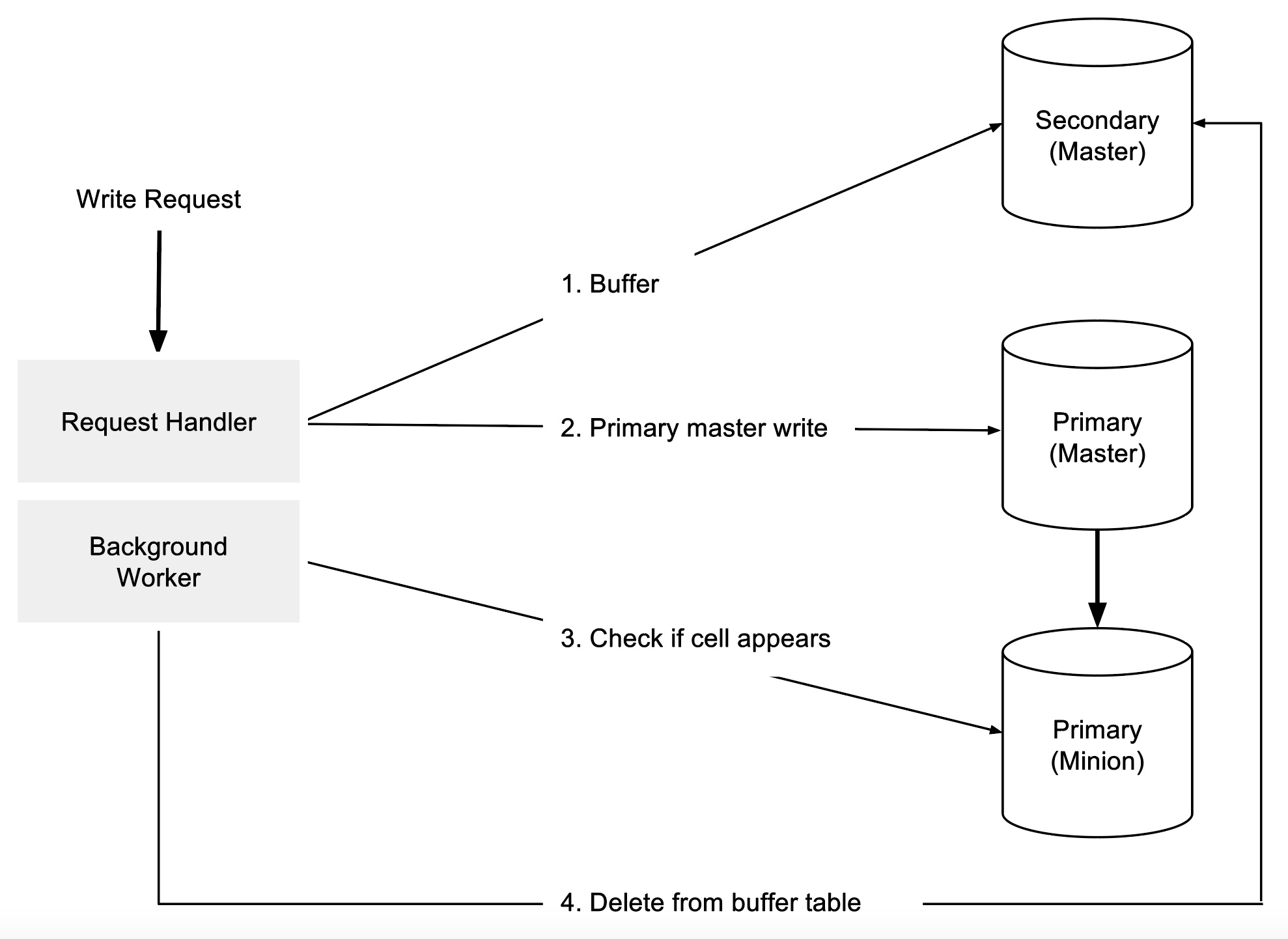
主集群的主节点是在随后的读取中期望找到数据的地方。如果主机群的主节点在 MySQL 异步复制主集群从节点之前遭遇不错,次集群作为数据的一个临时备份。
次主节点是随机选出的,写入被放置在一张特殊的缓冲表中。有一个后台任务在监控主机群的从节点中单元格是否出现;然后才删除缓冲表中的记录。拥有次集群意味着所有数据至少要写到两台主机上,此外次集群的数量是可以配置的。
缓冲写遵循幂等性:如果存在同行键、列名和 ref key 的单元格,就拒绝写入。幂等性意味着当主集群的主节点恢复,被缓冲的单元格只有行键、列名和 ref key 不同的那些才会被写入主集群。
使用 MySQL 作为存储后端
Schemaless 的很多功能源自于我们在存储节点上使用 MySQL。Schemaless 本身覆盖在 MySQL 之上,将请求路由至正确的数据库。通过使用 MySQL 索引和 InnoDB 内置的缓存,我们就获得了快速查询单元格和二级索引的性能。
每个 Schemaless 分片都是一个单独的数据库,每个 MySQL 数据库服务器包含了很多个数据库。每个数据库都有一张单元格表(称之为 entity table),每个二级索引也有一张数据表和一组辅助表。Schemaless 单元格相应的 MySQL 表结构:
| 名称 | 类型 |
|---|---|
| added_id | int, auto-increment |
| row_key | uuid |
| column_name | string |
| ref_key | int |
| body | blob |
| created_at | datetime |
added_id 列是整个表的自增主键。此外,added_id 作为每个单元格的唯一指针,Schemaless 触发器用其按插入的时间顺序高效地提取单元格。
row_key、column_name 和 ref_key 列分别对应 Schemaless 单元格的行键、列名和 ref key。为了高效地通过这三个查找单元格,我们在这三列上定义了一个复合索引。
body 列包含了单元格的 JSON 对象,并压缩为 MySQL blob。我们试验了各种编码和压缩算法,权衡压缩速度和体积,最终使用了 MessagePack 和 ZLib。created_at 列用于插入的时间戳,被触发器用于根据时间范围查找单元格。
通过这种设计,我们让客户端控制对象结构,而非修改 MySQL 的表结构,能够高效地查找单元格。此外 added_id 使得插入的数据被线性地写入磁盘,所以我们可以将数据作为分区日志来访问。