Schemaless 数据库的设计三
Oct 13, 2022 22:30 · 2645 words · 6 minute read

这是 Uber Schemaless 数据库三部曲的第三篇,详述 Uber Schemaless 数据库的触发器功能。
Schemaless 触发器是一项可扩展、容错且不丢消息的技术,用于监听 Schemaless 实例的变更。它是我们行程处理工作量背后的引擎,从司机按下“结束行程”并向乘客收费,到数据进入我们的仓库以分析。
回顾一下,Schemaless 中最基本的数据实体被称为单元格。它是不可变的,是不可变的,一旦写入就不能被覆写了。单元格由行键、列名和 ref key 引用。通过写入新版本(更高的 ref key)的数据来更新单元格内容。Schemaless 不强制数据按照任何格式来存储,由此得名。从 Schemaless 的视角来看,它只存储 JSON 对象。
触发器示例
下面代码简单地展示了我们是如何异步收费的(大写表示 Schemaless 行名)。
在函数内通过添加一个装饰器(decorator) @trigger 并指定 Schemaless 实例的列定义触发器。这告知了 Schemaless 触发器框架在单元格被写入 BASE 列时调用函数 bill_rider,新单元格写入 BASE 列表示行程结束了。行键即行程的 UUID 被传给调用的函数。如果要更多的数据,开发者要从 Schemaless 获取真实数据。
案例中向乘客计费,bill_rider 触发器函数如下图所示。
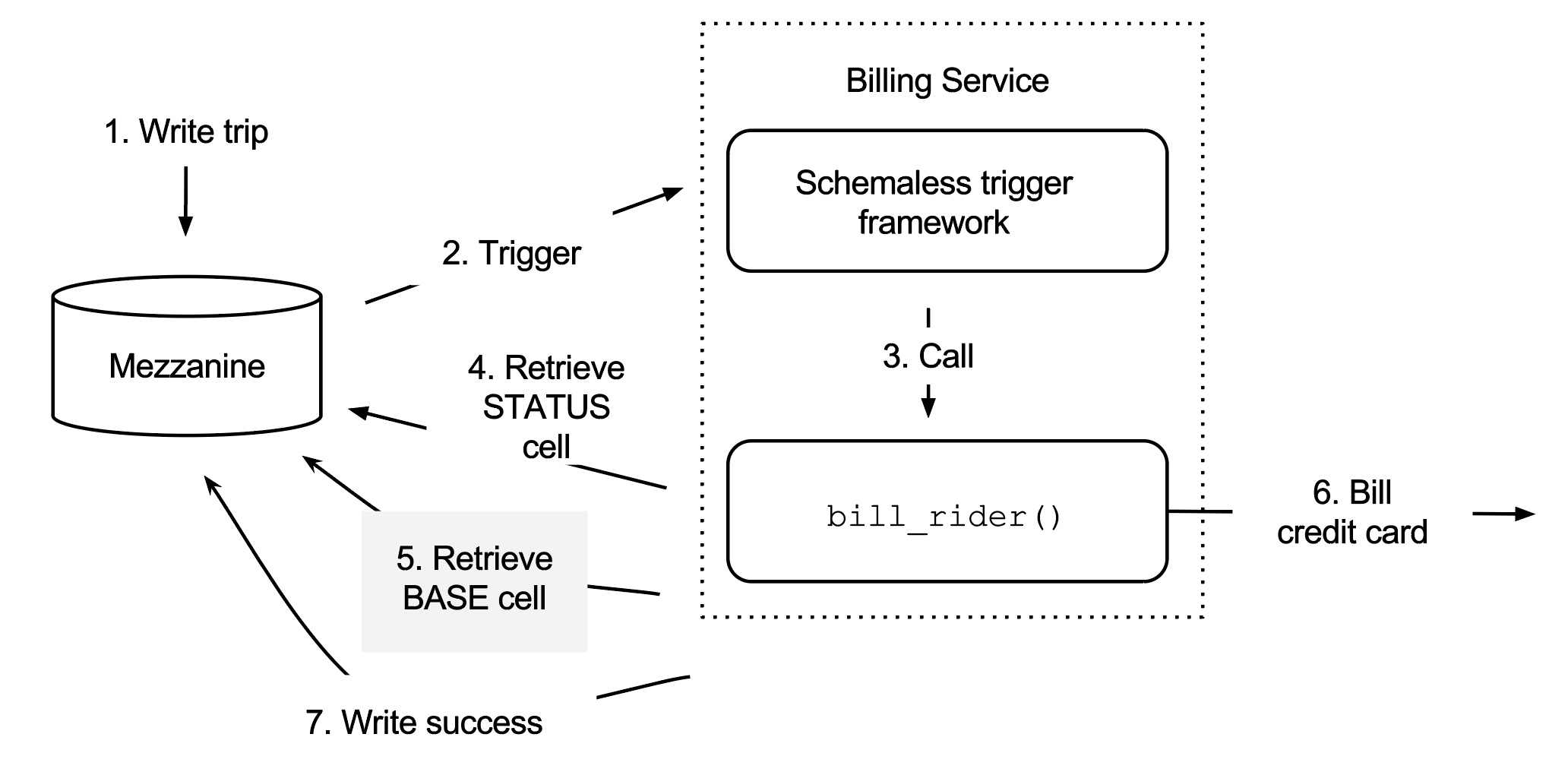
行程首先进入 Mezzanine,使得 Schemaless 触发器框架调用 bill_rider。在函数中查询 STATUS 列最新的数据,此时 is_completed 字段还不存在,意味着还未向乘客收费。获取到 BASE 列中的行程信息,函数调用信用卡付费。收费成功后回写至 Mezzanine 并将 STATUS 列中的 is_completed 字段设置为 True。
触发器框架保证 bill_rider 函数至少被调用一次。触发器函数通常只被触发一次,但出错时可能被多次调用。这就意味着触发器函数必须是幂等的,在本例中是检查单元格是否已经被处理过。如果被处理过了,就返回。
我们将解释如何将 Schemaless 看作是一个记录着变化的日志,讨论相关 API,并分享用于扩展和容错的技术。
Schemaless 作为日志
Schemaless 有着给定行键与列的所有版本单元格。除了随机访问的简直存储,Schemaless 还充当了变更日志的角色。实际上这还是分布式日志,每个分片都是它自己的日志,如下图:
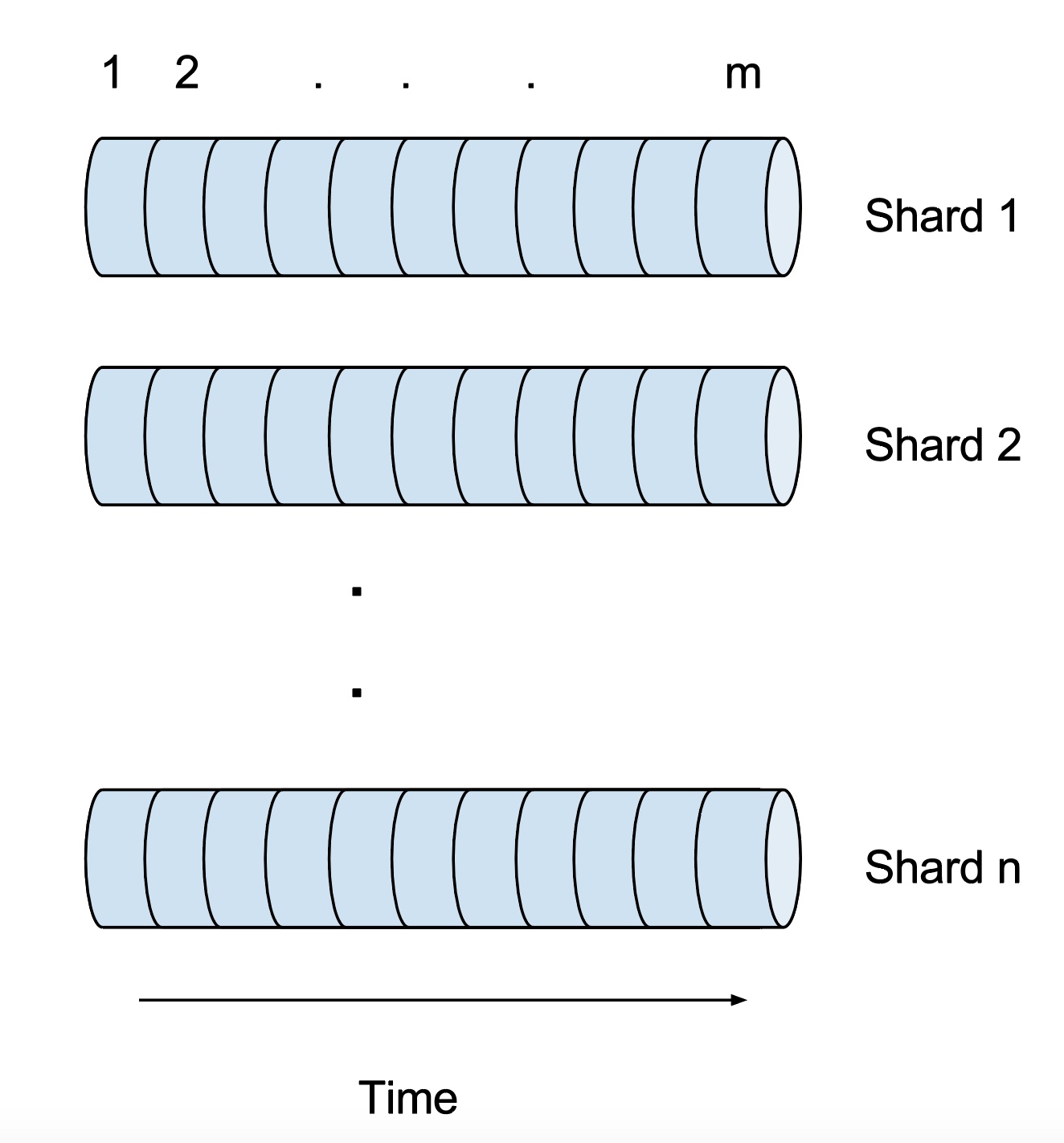
每个格子根据行键被写入特定的分片,即 UUID。在一个分片中的所有单元格都被分配一个唯一 ID,称作 added ID,这是一个表示单元格插入顺序的自增字段(单元格越新 added ID 越大)。除此以外每个单元格还有写入的时间戳。而单元格的 added ID 在所有副本中都是一样的,用于做故障切换。
Schemaless API 同时支持随机访问和日志模式访问。随机访问 API 寻址单个单元格,通过三维坐标 row_key、column_key 和 ref_key 定位:
- 给定行键、列名和 ref key 插入单元格
put_cell (row_key, column_key, ref_key, cell) - 返回由行键、列名和 ref key 指定的单元格
get_cell(row_key, column_key, ref_key) - 返回指定行键和列名的最新单元格
get_cell_latest(row_key, column_key)
而对于日志模式访问的 API,我们关心的是单元格的分片号、时间戳以及 added ID:get_cells_for_shard(shard_no, location, limit)
类似于随机访问 API,日志模式 API 可以一次从多个分片中批量获取单元格,但最主要的还是上述方法。时间戳或 added_id 都能作为位置。调用 get_cells_for_shard 除单元格外还返回下一个 added ID。举个栗子,如果通过位置 1000 调用 get_cells_for_shards 查询十个单元格,下一个位置偏移量将是 1010。
追踪日志
通过日志模式 API 可以追踪一个 Schemaless 实例,很像追踪系统上的文件(例如 tail -f)或事件队列(例如 Kafka),观察最新的变更,客户端会持续追踪偏移量。要开始追踪,从第一个条目(位置 0)或之后的任意时间都可以。
Schemaless 触发器通过使用日志模式访问 API 实现追踪,持续追踪偏移量。相较于直接轮询 API 的好处是 Schemaless 触发器使得该过程可扩展且容忍故障。客户端程序通过配置目标 Schemaless 实例和列来连接触发器框架。回调函数被附加到框架中的数据流上,当新的单元格被插入,由 Schemaless 触发器调用。框架在程序会运行的主机上启动期望数量的工作进程,将任务分配给可用的进程,并将失败的任务分散到进程中,来优雅地处理失败的进程。这种分工意味着程序员只要编写处理函数,并确保它是幂等的。剩下的就由 Schemaless 触发器来处理。
架构
下图以前面的计费服务为例,从高层次展示了该架构:
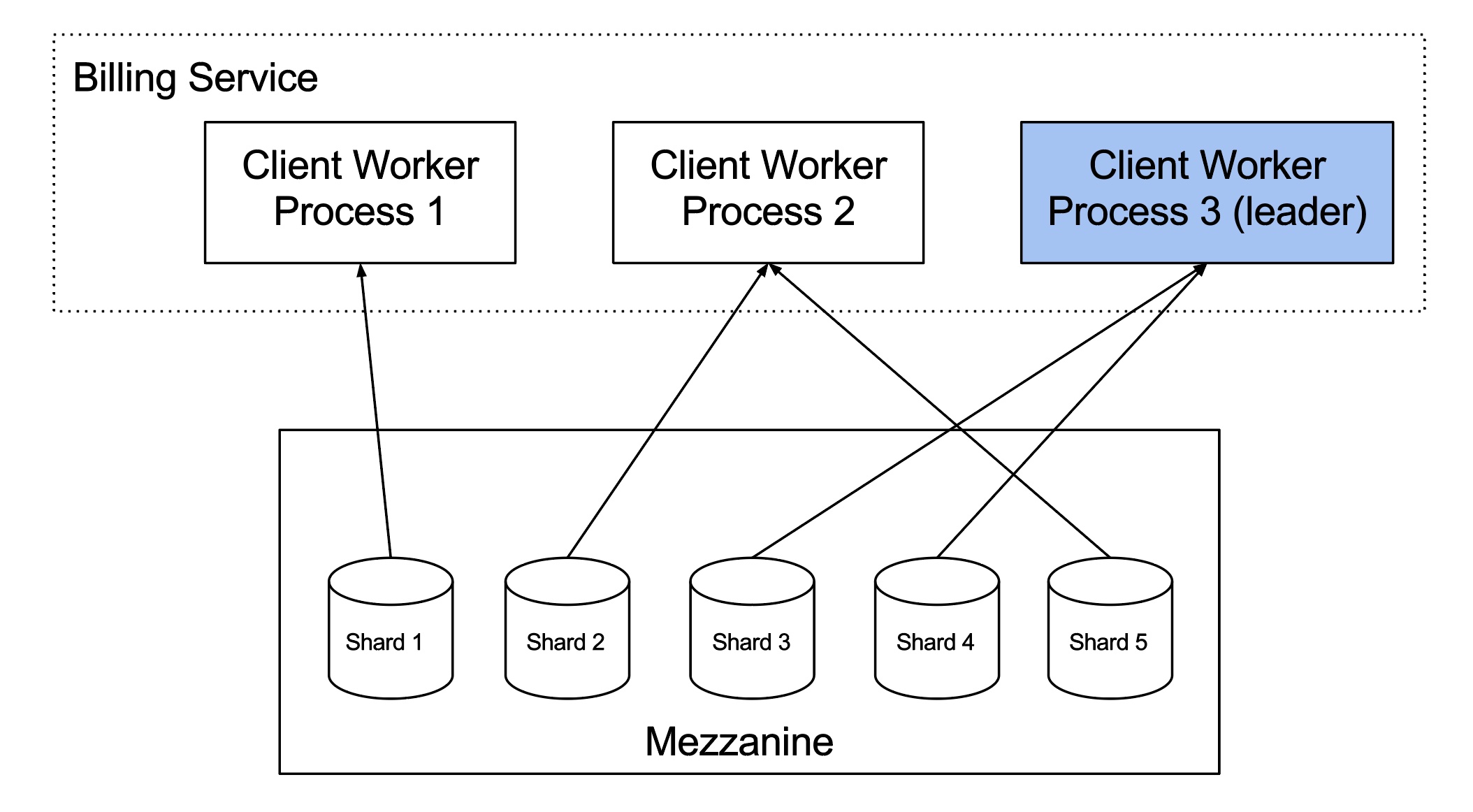
使用 Schemaless 触发器的计费服务运行在三个不同的主机上,假设每台主机一个工作进程。Schemaless 触发器框架在工作进程之间划分分片这样只有一个工作进程处理特定的分片。工作进程 1 从分片 1 拉取数据,同时工作进程 2 在处理分片 2 和 5,工作进程 3 处理分片 3 和 4。工作进程只处理分配了分片的单元格,为这些分片调用注册过的回调函数。有一个工作进程被指定为 leader,负责为工作进程分配分片。如果工作进程挂了,leader 将分片重新分配至其他进程。
在一个分片中,单元格按它们被写入的顺序依次触发。这也意味着如果因为程序问题触发某个单元格总是失败,会阻塞来自该分片的单元格处理。为了防止这种情况,你可以配置使 Schemaless 触发器标记重复失败的单元格,并将它们放到单独的队列中,然后 Schemaless 触发器将继续处理下一个单元格。如果被标记的单元格数量超过了某个阈值,就会停止触发。这往往表明存在系统错误,需要人工修复。
Schemaless 触发器通过存储每个分片最近成功触发的单元格的 added ID 来追踪触发过程。框架将这些偏移量持久化到共享存储中,例如 Zookeeper 或 Schemaless 本身,这意味着如果程序重启,触发能够从共享存储中的偏移量继续。共享存储也用于元数据,例如协调 leader 选举和发现添加和移除的工作进程。
扩展和容错
Schemaless 触发器是为了可扩展而设计的。对于任意客户端程序,我们可以添加最多 Schemaless 分片数量个(通常是 4096)工作进程。此外,可以通过在线添加或删除工作者以应对负载。通过完全在框架中追踪进度,我们可以为 Schemaless 实例添加尽可能多的客户端以发送数据。在服务器端没有任何逻辑来或向它们推送状态。
Schemaless 触发器也容忍错误,会发生故障而不损伤系统:
- 如果一个客户端工作进程挂了,leader 将分发它的工作,确保所有分片得到处理。
- 如果 Schemaless 触发器节点中的 leader 挂了,一个新的节点将被选主。在选主期间,单元格仍会被处理,但任务不能重新分配,工作进程也不能添加和删除。
- 如果共享存储(ZooKeeper)挂了,单元格仍会被处理。但是就行选主期间,不能重新分配任务,工作进程不能变更。
- 最后 Schemaless 触发器框架与 Schemaless 实例内部的故障无关。任意数据库节点都可以下线,因为 Schemaless 触发器从副本读取数据。
总结
从操作方来看,Schemaless 触发器是低心智负担的。Schemaless 是真实数据源的理想存储,通过随机访问 API 或日志模式访问 API 访问数据。在日志模式 API 之上使用 Schemaless 触发器将数据的生产者和消费者解耦,使程序员专注于业务逻辑,无需考虑扩展和容错的问题。最后,我们可以热添加更多存储服务器来增加数据容量和性能,因为有了更多地 CPU 和内存。如今 Schemaless 触发器框架驱动了行程的处理流,包括纳入我们的分析仓库和跨数据中心副本。