Schemaless 数据库的设计一
Sep 29, 2022 22:00 · 3348 words · 7 minute read

原文:https://www.uber.com/blog/schemaless-part-one-mysql-datastore
这是 Uber Schemaless 数据库三部曲的第一篇。
Uber 新数据库之路
2014 年初,因为业务增长数据库空间已见底,每个里程碑实际上都在将我们一步步推向悬崖。我们意识到 Uber 的基础设施在年底就要撑不住了:无法使用 Postgres 存足够的行程数据。我们的使命是为 Uber 实现下一代数据库技术,这是一个相当耗费人力物力的任务。
但首先,已经存在大量商业和开源替代方案的情况下为什么还要打造一个可扩展的数据库呢?我们对新的行程数据存储有五个关键需求:
- 通过加服务器即可线性地扩容。这是 Postgres 所缺乏的特性。添加服务器应该既增加磁盘存储又减少系统响应时间。
- 写高可用。我们之前用 Redis 实现了一个简单的缓冲机制,因为行程已存储在 Redis 中,所以如果写入 Postgres 失败可以稍后重试。但当行程只在 Redis 中时,就无法从 Postgres 中读取,就无法计费。虽然不好用,但起码没有丢失行程!随着时间的推移,基于 Redis 的解决方案无法扩展。Schemaless 必须支持与 Redis 类似的机制,但更倾向写可用性而非读语义。
- 需要一种通知下游依赖的方式。在当前系统中,我们有多个组件同时处理行程(例如,计费、分析等等)。这个过程很容易出错:只要有步骤失败,即使某些组件成功,也必须重试。这无法扩展,因为我们希望将这些步骤分解为由数据变更驱动的独立步骤。我们确实有一个异步的行程事件系统,但它基于 Kafka 0.7。但它会丢消息,我们想要一个有类似功能但不丢消息的系统。
- 二级索引。由于我们从 Postgres 迁移,新的存储系统必须支持 Postgres 索引,这意味着二级索引以同样的方式搜索行程。
- 易于运维,因为它包含了关键数据。如果数据库在凌晨失灵导致业务瘫痪,我们是否有足够的能力来快速修复它?
鉴于上述需求,我们分析了一些选项的优点和潜在的局限性:
| 选项 | 线性扩容 | 写高可用 | 通知 | 索引 | 易运维 |
|---|---|---|---|---|---|
| Cassandra | ✓ | ✓ | ✗ | (✓) | ✗ |
| Riak | ✓ | ✓ | ✗ | (✓) | (✓) |
| MongoDB | ✓ | ✗ | ✗ | (✓) | ✗ |
这三种系统都能够通过添加新服务器扩容,只有两个在故障切换期间也能够接收写请求。没有一种有内置的发生变更时提醒下游依赖方式,需要在应用层实现。都有索引,但要索引不同值的话,查询会变慢因为要聚合所有节点。最后我们有使用经验的系统并不面向在线用户的流量,而且有一些运维问题。
最后,我们的决定不仅取决于所使用的技术,也取决于团队中的技术经验。
我们相信 Schemaless
在规定时间内上述方案都不能满足我们的要求,我们决定打造自己的系统,尽可能地简化操作,同时应用学来的扩展经验。设计的灵感来自 Friendfeed 和 Pinterest。
我们最终构建了一个无模式(schemaless)的键值存储,允许保存任何 JSON 数据而无需严格的结构验证。它有 append-only 分片的 MySQL,在主库故障时支持缓冲写入,还有用于数据变更通知的发布-订阅功能,我们称之为触发器。最后,Schemaless 支持数据的全局索引。下面,我们将讨论数据模型和一些关键特性,包括 Uber 的行程剖析。
Schemaless 数据模型
Schemaless 是一个三维的持久化哈希表,只可追加(append-only),很像 Google 的 Bigtable。Schemaless 最小数据实体叫做单元格(cell),是不可变的;一旦写入,既不能重写也不能删除。单元格是一个由 UUID(行键)、列名和 ref key(整数)引用的 JSON blob。
你可以把行键看作关系型数据库中的主键,但是在 Schemaless 中没有预定义或强制的模式,行无需共享列名;实际上列名完全是由应用程序定义的。ref key 用于单元格的版本控制。如果要更新一格,就要写一个有更高的 ref key 的单元格(最新的单元格就是有最高的ref key 的那个)。
应用程序通常将相关数据分组到同一列中,每一列中的所有单元格的应用程序端模式大致相同。这种分组是将一起变更的数据捆绑的好方法,允许应用程序快速改变模式而需要将数据库停机。
示例:存储在 Schemaless 中的行程
在深入如何在 Schemaless 中建立行程模型前,先剖析 Uber 的行程。行程数据是在不同时间点产生的,从上车、下次到计费,这些不同的信息碎片随着评价、或后台程序的执行而异步到达。
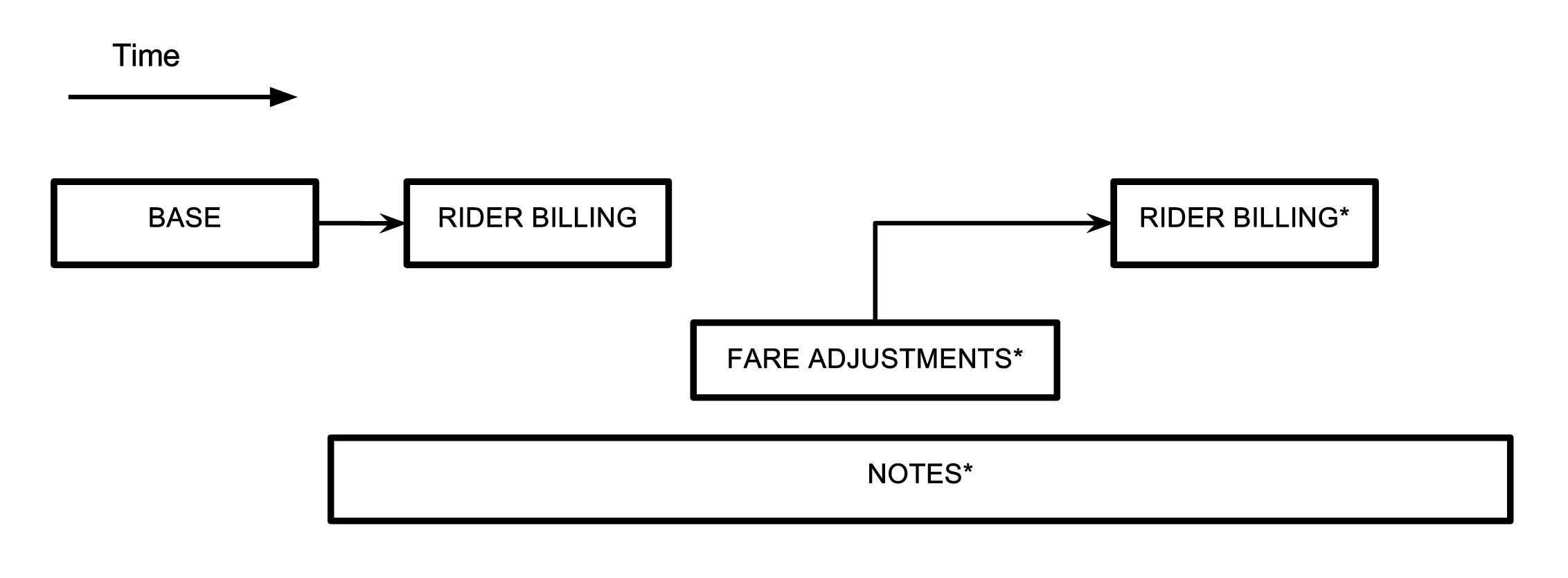
行程由乘客发起,由司机接受,有开始和结束的时间戳。这些信息构成了基本行程,由此计算出费用。行程结束后可能要调整费用,添加注解(司机或乘客的反馈)。要么,我们可能得重试多种信用卡,以防止第一张信用卡过期。Uber 的行程流是一个数据驱动的过程。当数据被插入时,某些特定的程序就会执行。其中的某些信息,比如乘客和司机的评分,可能行程结束后几天才来。
那么在 Schemaless 中建模上述行程呢?
行程数据模型
有两个行程(trip_uuid1 和 trip_uuid2):
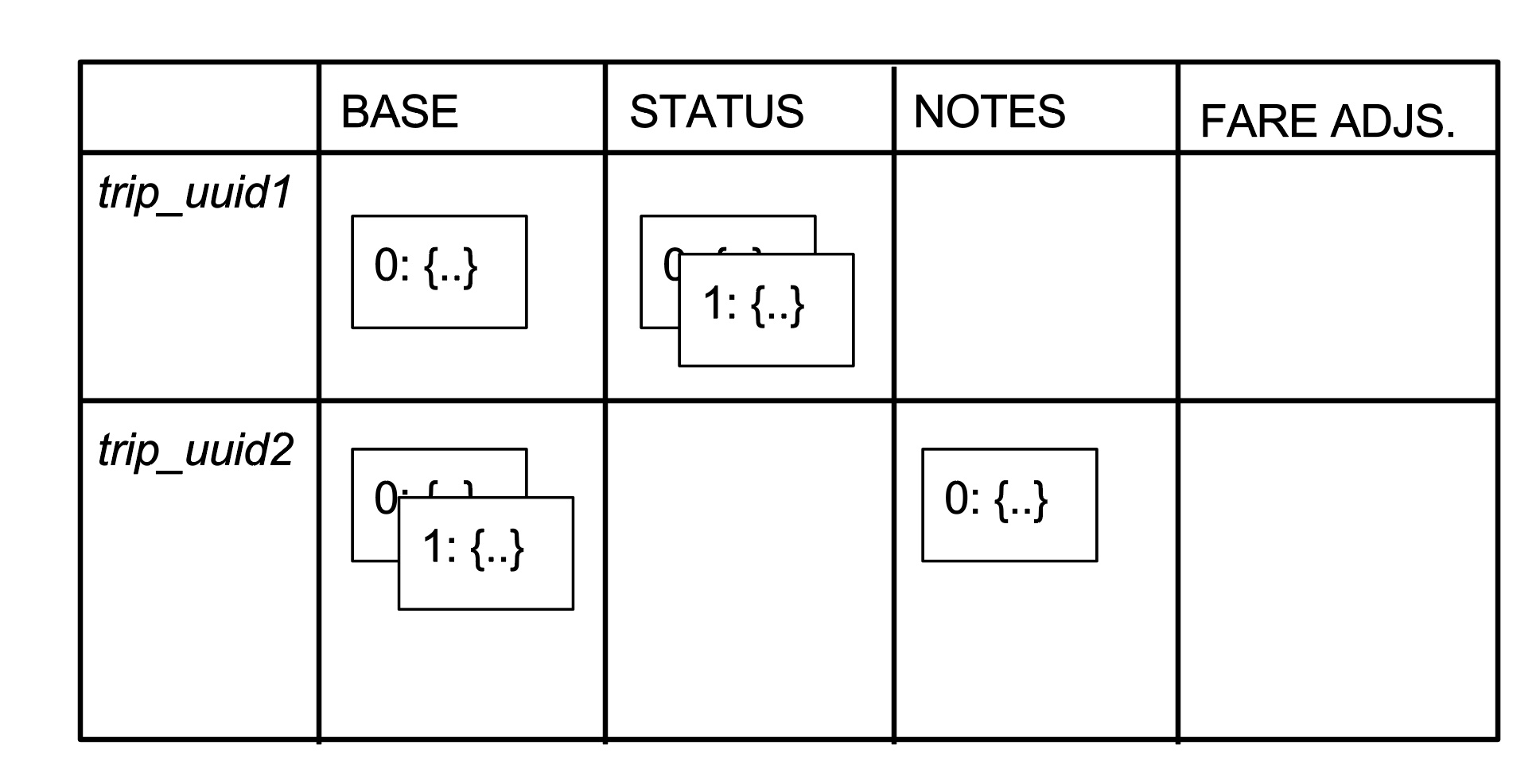
trip_uuid1 有三个单元格:一个在 BASE 列中,另外两个在 STATUS 列中。trip_uuid2 在 BASE 列中有两个单元格,NOTES 列中有一个。FARE ADJUSTMENTS 列中一个都没有。对于 Schemaless 来说列并无不同;列的语义都是由应用程序定义的,在这个案例中是 Mezzanine 服务。
在 Mezzanine 中 BASE 列的单元格包括基本的行程信息,比如司机的 UUID 和行程的日期时间。STATUS 列包含行程的当前支付状态,为每个尝试计费的行程插入一个单元格(如果信用卡资金不够或已过期,就会失败)。NOTES 列包含本次行程的司机或 Uber 运营人员的留言。最后如果行程费用有所调整 FARE ADJUSTMENTS 列就会有单元格。
我们拆分成这样的列来避免数据竞争,并最小化需要写入或更新数据的次数。当行程结束写 BASE 列,通常只有一次。在数据写入 BASE 列后,尝试计费就会写 STATUS 列,如果计费失败会重复几次。NOTES 类似也是在 BASE 写入后被写入多次,但与写 STATUS 列是完全分开的。 FARE ADJUSTMENTS 只有当行程费用变更时才会写入,比如绕路。
Schemaless 触发器
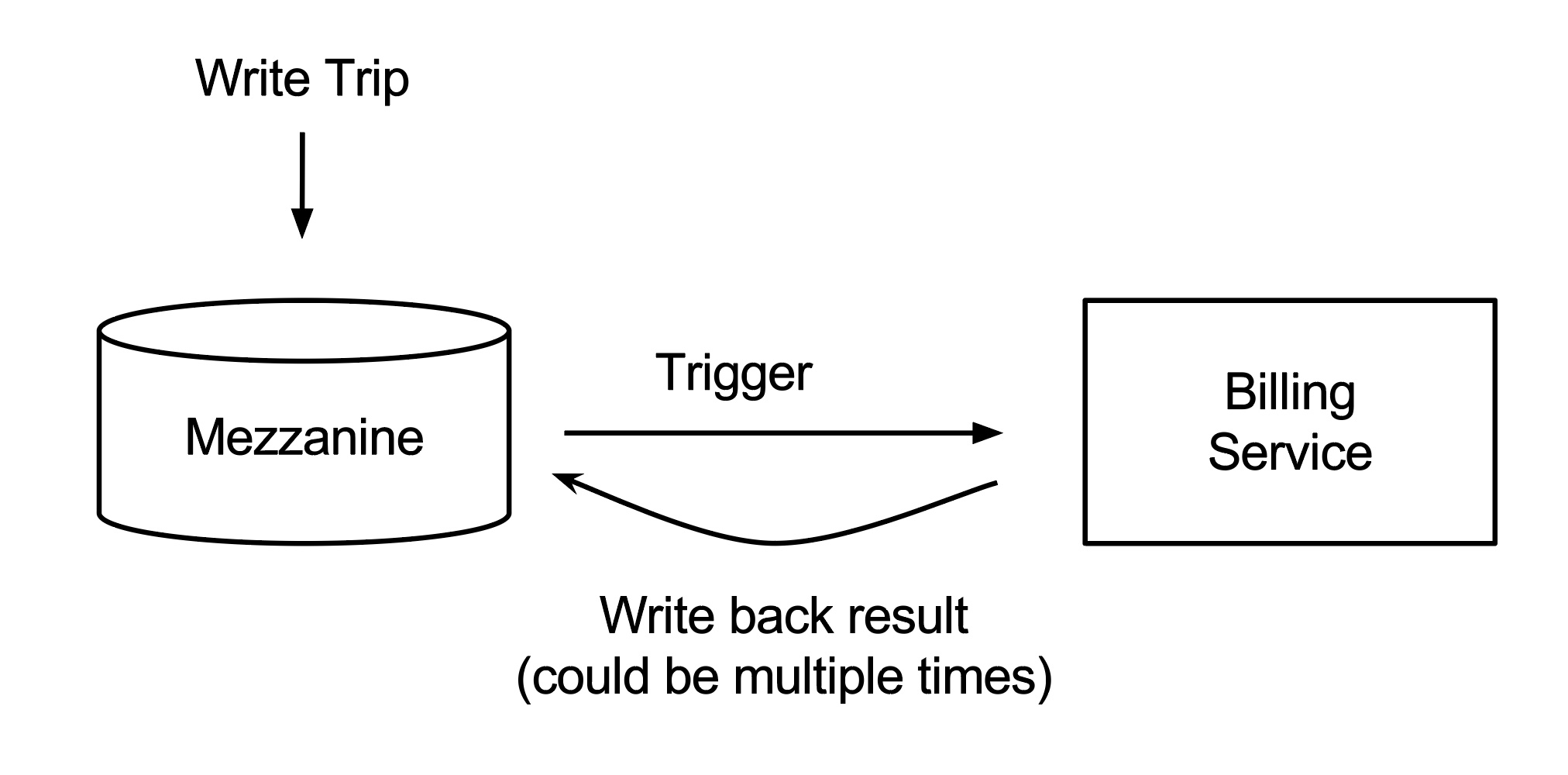
触发器是 Schemaless 的关键功能,当数据变更时通知客户端。因为单元格是不可变更的,只能追加新版本,每个单元格也代表一次变更或一个新版本。可以监听数据变更并触发函数,很像 Kafka 这样的事件总线系统。下游的依赖可以利用该功能来监控并触发应用程序特定的代码(有一个类似的系统是 LinkedIn DataBus),因此解耦了数据创建和处理。
Uber 利用 Schemaless 触发器对行程计费:当 trip_uuid1 的 BASE 列被写入,会触发计费服务读取 BASE 列单元格并尝试用信用卡付费,信用卡支付的结果会被回写至 STATUS 列。这样计费服务就和行程的创建解耦了,Schemaless 充当异步事件总线的角色。
易于访问的索引
Schemaless 支持在 JSON blob 字段上定义索引。通过这些预定义的字段查询索引来找到匹配查询参数的单元格。查询索引很高效,因为只需要去一个分片中查找单元格。实际上查询可被进一步优化,因为 Schemaless 允许单元格数据直接被反序列化至索引中,意味着一次索引查询在查询的同时就能检索信息。我们通常建议 Schemaless 的用户将可能需要的数据反序列化至索引中。从某种意义上说,用存储换查找速度。
以 Mezzanine 为例,我们定义了一个二级索引来找到某个司机的行程。我们反序列化了行程创建时间和所在的城市,就能够在既定的时间范围内查询城市中某个司机的所有行程。我们给出 YAML 格式的 driver_partner_index 的定义,这是行程数据的一部分,在 BASE 列上定义。
利用该索引,我们能够通过 city_uuid 和 trip_created_at 过滤给定 driver_partner_uuid 的所有行程。在这个例子中只用了 BASE 列中的字段,但 Schemaless 支持对多个列的数据进行反序列化处理。
如上所述 Schemaless 有着高效的索引,通过基于分片字段的分片索引实现。因此对索引的唯一要求就是索引中的一个字段要被指定为分片字段(上面的例子中那就是 driver_partner_uuid,因为它是第一个给定的)。分片字段决定了索引条目被写入哪个分片或从哪个分片检索,因为我们在查询索引时需要提供分片字段。这意味着在查询时只要访问一个分片来得到索引。关于分片要注意的是,应该分布均匀。UUID 是最好的,城市 ID 次优,而枚举的状态字段就不行。
分片字段以外的其他字段, Schemaless 支持各种查询。目前分片字段必须是不可变的,因为 Schemaless 只需访问一个分片。但是我们也在探索使它可变更同时不会产生很大的性能开销。
索引是最终一致的,每当写一个单元格,也会更新索引条目,但不在同一个事务中。单元格和索引通常不在一个分片中。所以如果要提供一致的索引,就要引入二阶段锁,会带来巨大的开销。最终一致性意味着 Schemaless 用户有可能看到过期的数据。大多数时候,索引滞后时间都远低于 20ms。
总结
我们概述了数据模型、触发器和索引,这些都是定义 Schemaless 的关键特征,它是我们行程数据的存储引擎。在未来的文章中我们将看看 Schemaless 的其他特性,说说它如何成为 Uber 的基础设施:更多的架构、为何使用 MySQL 作为存储节点,以及我们如何在客户端实现容错。