3 分钟了解系统可扩展性
Jun 18, 2020 20:00 · 4318 words · 9 minute read
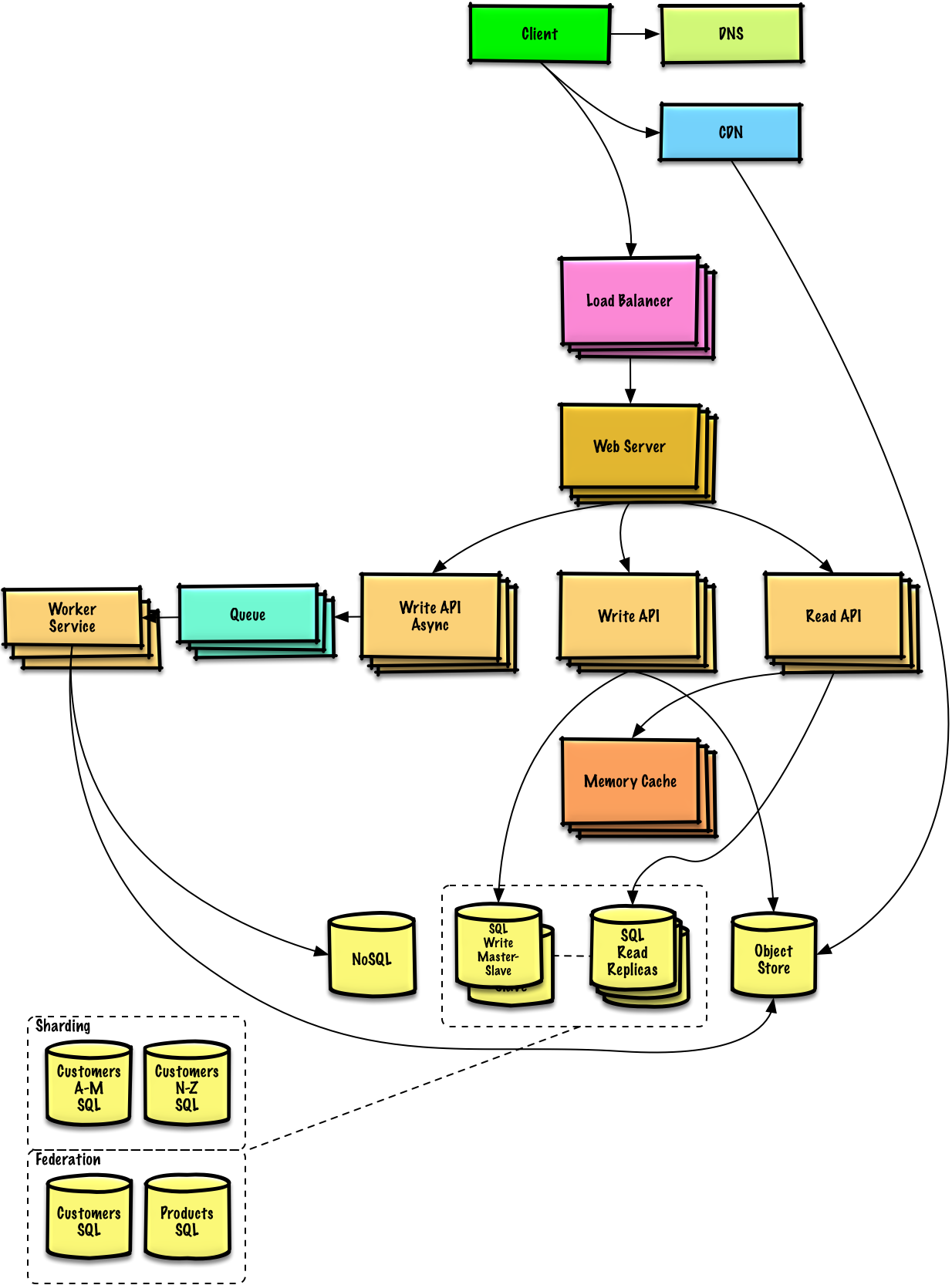
多副本
托管着可扩展的 Web 服务服务器都在负载均衡器后面,LB 将负载(也就是用户请求)分发至应用程序所在的服务器集群,这意味着,如果用户 Steve 访问你的服务,他的第一条请求可能分配至 2 号服务器,第二条请求可能分配至 9 号服务器,而第三条请求可能又被分配至 2 号服务器。
请求无论被分配至哪台服务器 Steve 始终都应该得到相同的结果。这是可扩展性的第一条黄金法则:每台服务器都包含完全相同的代码库,不要在本地存储任何业务数据,例如 session 或个人资料图片。
session 需要被存储到所有应用程序服务器都能访问的中央数据存储中,可以是外部的数据库或持久化缓存(Redis)。即使是持久化的缓存也比数据库性能要更好。外部的意思是数据存储不在任何业务服务器上,相反,它们在数据中心里与应用程序服务器相邻。
数据库
现在你的服务器可以水平扩展和应付成千上万的并发请求了。但是你的应用程序还是越来越慢最终挂掉,瓶颈就是你的数据库。MySQL 对不?
现在所要做的比堆服务器更彻底,甚至可能要推倒重来。最终,你会二选一:
第一条路:MySQL 到底。招个 DBA 让他搞主从高可用(主写从读)并持续升级主数据库服务器,内存拉满。在接下来的几个月中,你的 DBA 会念念有词“分库分表”、“SQL 调优”什么的,并担心能不能睡个好觉。到那时,数据库保持运行的每个操作都付出巨大的代价。如果你的数据量不大而且方便迁移最好选择方案二。
第二条路:从一开始就不走寻常路,在任何查询语句中都不要 Join。可以继续使用 MySQL,像用 NoSQL 那样用它,或者直接切换到更容易扩展的 NoSQL 数据库,例如 MongoDB 或 CouchDB。Join 的逻辑现在需要在应用程序代码中实现。越早这么做以后代码的变动越少。但即使你成功切换最新最强大的 NoSQL 数据库,很快数据库查询还是会越来越慢。你将要引入缓存。
缓存
现在你有了可扩展的数据库方案,也不必再担心 TB 级别的数据存储了,岁月静好。但因为要从数据库中大量获取数据你的用户不得不忍受缓慢的请求。解决方案就是接入缓存。
这里所说的都是基于内存的缓存,例如 Memcached 和 Redis。不要让缓存落盘,这对高可用是噩梦。
回到 in-memory 缓存。缓存以键值对的形式存储,作为应用程序和数据库之间的缓冲层存在。每当你的应用程序要捞数据,首先应该从缓存中检索,只有缓存中没有期望的数据时才去主数据源中获取。为啥要这样?因为缓存非常非常快。它在内存中保持所有数据并且在技术上尽可能快地处理请求。举个栗子,运行在标准服务器上的 Redis 每秒可进行数十万次读取操作,写数据(尤其是自增)也非常快。盘它!
缓存数据有两种模式,老的和新的:
1 缓存数据库查询
这仍然是最常用的缓存模式。每当查询数据库时,都把结果存到缓存中,查询语句的哈希结果就是缓存的键。下次查询时首先从缓存中捞一把看看有没有。这种模式有点问题,主要是缓存过期,当数据源变了就要把与之相关的缓存全都删掉,你懂的。
2 缓存对象
墙裂推荐,我永远喜欢这种模式。总而言之,将数据视为对象,就像你在代码里干的那样。让类从数据库中组装一个数据集,然后将类的完整实例或封装好的数据集存储在缓存中。听起来很呆板,我知道,就看看你平常怎么写代码的。举个栗子有个叫 Product 的类,某个属性叫 data,是个包含产品价格、文本、图片和客户评论的数组。Product 类有几个方法将数据注入 data,这些方法会执行几条难以缓存的数据库查询,因为它们相互关联。现在照下面的做:当类完成了数组的封装,直接在缓存中存数据或完整的类实例。只要发生任何变更就可以轻松清除该对象,这使得代码的整体操作更快更合理。
最棒的是:这让异步处理成为可能!想象下有一堆给你组装对象的工作进程!应用程序也只消费最新的缓存对象,几乎不再接触数据库!
你可能意识到我是缓存狂热的粉丝。它易于理解,实现起来非常简单,而且能达到令人叹为观止的效果。相比 Memcached 我更喜欢 Redis,尤其是可持久化的数据库功能和内置的数据结构(列表与集合)。借助 Redis 和巧妙的键值,甚至可以完全摆脱数据库。但是如果你只想缓存,就用 Memcached 好了,因为它的扩展能力实在迷人。
异步
想象你要去面包房买面包,你进走了进去,但是卖光了!当被告知两小时后来取预定的面包,这不是很烦人吗?
为了避免这种“请稍等”的情况,就要异步处理了。对面包房对你的 web 服务或者 web app 都好。
通常有两种方式实现异步:
方案一 #1
继续留在面包房的情景中,异步处理的第一种方法是“晚上烤面包早上卖面包”。对应至 web 应用程序意味着要提前进行耗时的工作,并以较低的请求延迟为完成的工作提供服务。
通常这么搞来将动态内容转换成静态内容。网站的页面(也许使用 web 框架或 CMS 构建)会预先渲染,并在每次更改时以静态 HTML 文件的形式本地存储。这些任务一般定期执行,可能由 cronjob 每小时跑一把脚本完成。这种对常规数据的预计算可以极大地优化网站和 web 应用程序的性能并兼具可扩展性。试想一下如果脚本将这些渲染好的 HTML 页面上传到 AWS S3 或者 CDN!你的网站就有了超强的响应能力,每小时处理数百万访问者都是毛毛雨!
方案二 #2
回到面包房,有些顾客要定制生日蛋糕,面包房也没法预见这类客户的需求,因此必须在客户来之后才开始执行任务,并跟他说第二天回来拿。对应至 web 服务意味着异步处理任务。
下面是典型的工作流程:
用户访问你的服务并启动了一项非常吃计算资源的任务,要几分钟才能完成。web 前端将任务发送至作业队列并立即告诉用户,你的任务已经在处理,请继续浏览。应用程序会不停检查作业队列中是否有新任务。如果有新任务的话就拿来处理,在几分钟后发送信号表示任务已完成。前端会不断检查“已完成”这个信号,一旦完成就通知用户。这是最简化的例子。
如果你想深挖细节和真正的技术设计,推荐看下 RabbitMQ,这是一种帮助实现异步的系统。基本思想就是搞个任务队列让工作进程处理。异步看似复杂,但绝对值得花时间学习和自行实现。后端几乎可以无限扩展,前端也更有灵气,对用户体验的提升巨大。
如果有啥东西很费时,异步吧!
Clones
Public servers of a scalable web service are hidden behind a load balancer. This load balancer evenly distributes load (requests from your users) onto your group/cluster of application servers. That means that if, for example, user Steve interacts with your service, he may be served at his first request by server 2, then with his second request by server 9 and then maybe again by server 2 on his third request.
Steve should always get the same results of his request back, independent what server he “landed on”. That leads to the first golden rule for scalability: every server contains exactly the same codebase and does not store any user-related data, like sessions or profile pictures, on local disc or memory.
Sessions need to be stored in a centralized data store which is accessible to all your application servers. It can be an external database or an external persistent cache, like Redis. An external persistent cache will have better performance than an external database. By external I mean that the data store does not reside on the application servers. Instead, it is somewhere in or near the data center of your application servers.
Database
After following Part 1 of this series, your servers can now horizontally scale and you can already serve thousands of concurrent requests. But somewhere down the road your application gets slower and slower and finally breaks down. The reason: your database. It’s MySQL, isn’t it?
Now the required changes are more radical than just adding more cloned servers and may even require some boldness. In the end, you can choose from 2 paths:
Path #1 is to stick with MySQL and keep the “beast” running. Hire a database administrator (DBA,) tell him to do master-slave replication (read from slaves, write to master) and upgrade your master server by adding RAM, RAM and more RAM. In some months, your DBA will come up with words like “sharding”, “denormalization” and “SQL tuning” and will look worried about the necessary overtime during the next weeks. At that point every new action to keep your database running will be more expensive and time consuming than the previous one. You might have been better off if you had chosen Path #2 while your dataset was still small and easy to migrate.
Path #2 means to denormalize right from the beginning and include no more Joins in any database query. You can stay with MySQL, and use it like a NoSQL database, or you can switch to a better and easier to scale NoSQL database like MongoDB or CouchDB. Joins will now need to be done in your application code. The sooner you do this step the less code you will have to change in the future. But even if you successfully switch to the latest and greatest NoSQL database and let your app do the dataset-joins, soon your database requests will again be slower and slower. You will need to introduce a cache.
Cache
After following Part 2 of this series, you now have a scalable database solution. You have no fear of storing terabytes anymore and the world is looking fine. But just for you. Your users still have to suffer slow page requests when a lot of data is fetched from the database. The solution is the implementation of a cache.
With “cache” I always mean in-memory caches like Memcached or Redis. Please never do file-based caching, it makes cloning and auto-scaling of your servers just a pain.
But back to in-memory caches. A cache is a simple key-value store and it should reside as a buffering layer between your application and your data storage. Whenever your application has to read data it should at first try to retrieve the data from your cache. Only if it’s not in the cache should it then try to get the data from the main data source. Why should you do that? Because a cache is lightning-fast. It holds every dataset in RAM and requests are handled as fast as technically possible. For example, Redis can do several hundreds of thousands of read operations per second when being hosted on a standard server. Also writes, especially increments, are very, very fast. Try that with a database!
There are 2 patterns of caching your data. An old one and a new one:
1 - Cached Database Queries
That’s still the most commonly used caching pattern. Whenever you do a query to your database, you store the result dataset in cache. A hashed version of your query is the cache key. The next time you run the query, you first check if it is already in the cache. The next time you run the query, you check at first the cache if there is already a result. This pattern has several issues. The main issue is the expiration. It is hard to delete a cached result when you cache a complex query (who has not?). When one piece of data changes (for example a table cell) you need to delete all cached queries who may include that table cell. You get the point?
2 - Cached Objects
That’s my strong recommendation and I always prefer this pattern. In general, see your data as an object like you already do in your code (classes, instances, etc.). Let your class assemble a dataset from your database and then store the complete instance of the class or the assembed dataset in the cache. Sounds theoretical, I know, but just look how you normally code. You have, for example, a class called “Product” which has a property called “data”. It is an array containing prices, texts, pictures, and customer reviews of your product. The property “data” is filled by several methods in the class doing several database requests which are hard to cache, since many things relate to each other. Now, do the following: when your class has finished the “assembling” of the data array, directly store the data array, or better yet the complete instance of the class, in the cache! This allows you to easily get rid of the object whenever something did change and makes the overall operation of your code faster and more logical.
And the best part: it makes asynchronous processing possible! Just imagine an army of worker servers who assemble your objects for you! The application just consumes the latest cached object and nearly never touches the databases anymore!
As you maybe already realized, I am a huge fan of caching. It is easy to understand, very simple to implement and the result is always breathtaking. In general, I am more a friend of Redis than Memcached, because I love the extra database-features of Redis like persistence and the built-in data structures like lists and sets. With Redis and a clever key’ing there may be a chance that you even can get completly rid of a database. But if you just need to cache, take Memcached, because it scales like a charm.
Asynchronism
This 4th part of the series starts with a picture: please imagine that you want to buy bread at your favorite bakery. So you go into the bakery, ask for a loaf of bread, but there is no bread there! Instead, you are asked to come back in 2 hours when your ordered bread is ready. That’s annoying, isn’t it?
To avoid such a “please wait a while” - situation, asynchronism needs to be done. And what’s good for a bakery, is maybe also good for your web service or web app.
In general, there are two ways / paradigms asynchronism can be done.
Async #1
Let’s stay in the former bakery picture. The first way of async processing is the “bake the breads at night and sell them in the morning” way. No waiting time at the cash register and a happy customer. Referring to a web app this means doing the time-consuming work in advance and serving the finished work with a low request time.
Very often this paradigm is used to turn dynamic content into static content. Pages of a website, maybe built with a massive framework or CMS, are pre-rendered and locally stored as static HTML files on every change. Often these computing tasks are done on a regular basis, maybe by a script which is called every hour by a cronjob. This pre-computing of overall general data can extremely improve websites and web apps and makes them very scalable and performant. Just imagine the scalability of your website if the script would upload these pre-rendered HTML pages to AWS S3 or Cloudfront or another Content Delivery Network! Your website would be super responsive and could handle millions of visitors per hour!
Async #2
Back to the bakery. Unfortunately, sometimes customers has special requests like a birthday cake with “Happy Birthday, Steve!” on it. The bakery can not foresee these kind of customer wishes, so it must start the task when the customer is in the bakery and tell him to come back at the next day. Refering to a web service that means to handle tasks asynchronously.
Here is a typical workflow:
A user comes to your website and starts a very computing intensive task which would take several minutes to finish. So the frontend of your website sends a job onto a job queue and immediately signals back to the user: your job is in work, please continue to the browse the page. The job queue is constantly checked by a bunch of workers for new jobs. If there is a new job then the worker does the job and after some minutes sends a signal that the job was done. The frontend, which constantly checks for new “job is done” - signals, sees that the job was done and informs the user about it. I know, that was a very simplified example.
If you now want to dive more into the details and actual technical design, I recommend you take a look at the first 3 tutorials on the RabbitMQ website. RabbitMQ is one of many systems which help to implement async processing. You could also use ActiveMQ or a simple Redis list. The basic idea is to have a queue of tasks or jobs that a worker can process. Asynchronism seems complicated, but it is definitely worth your time to learn about it and implement it yourself. Backends become nearly infinitely scalable and frontends become snappy which is good for the overall user experience.
If you do something time-consuming, try to do it always asynchronously.