数据关系的威力
Jan 18, 2020 20:30 · 2189 words · 5 minute read

译文
你是否曾因被怀疑有欺诈行为而接到银行的电话?大多数银行已经可以自动识别出异常行为或地点并立刻采取措施,很多时候甚至在受害者觉察之前就将身份盗用等犯罪行为扼杀在摇篮中。
深刻理解数据关系就是这样强大。
深入挖掘疾病与基因之间的关系,并通过理解这种联系,在蛋白质的海洋中搜索,寻找与疾病相关的基因。这类信息能够帮助推进疾病研究。
对关系理解得越深,洞察力越强。有了足够多的关系数据点,你甚至可以“预测未来”(就像推荐引擎)。但随着越来越多的数据被联系还有数据的大小和复杂度的增加,越来越难以存储和查询关系。
八月我写了关于现代应用程序开发以及将一刀切的单个数据库拆分成专用数据库的价值。专用数据库支持多种数据模型,允许用户构建用例驱动的高可扩展的分布式应用程序。拥有正确工具才能正确地揭示数据关系,而图形数据库就是处理高度联系的数据的正确工具。
图形数据模型
在图形数据模型中,关系是核心,意味着你可以直接创建关系而不是使用外键(FK)或者连接(JOIN)表。数据被建模成点和线,换句话说,重点不是数据本身而是数据之间的关系。通过图形可以更轻松地表示和遍历数据之间的关系。
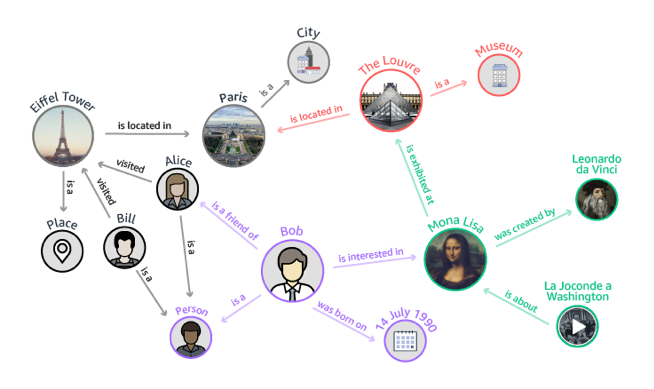
点通常是一个人,一个地方,或者一样东西,而线就是他们联系的方式。比如在下图中,Bob 是个节点,蒙娜丽莎是个节点,卢浮宫也是个节点,他们由不同的关系连接起来。Bob 对蒙娜丽莎感兴趣,蒙娜丽莎在卢浮宫里,卢浮宫是个博物馆。该示例图也叫知识图,能够用来帮助对蒙娜丽莎感兴趣的人在卢浮宫中发现达芬奇的其他作品。
处理关系的应用程序
当你要快速地在数据之间创建关系并查询时,图形不失为一个好的选择,知识图就不错。
社交网络
社会网络应用程序拥有大量用户数据和交互信息来追踪。比如你可能正在为应用程序添加社交订阅源。使用图形来优先显示用户自己家庭的最新动态,来自朋友圈的点赞,和附近的人。
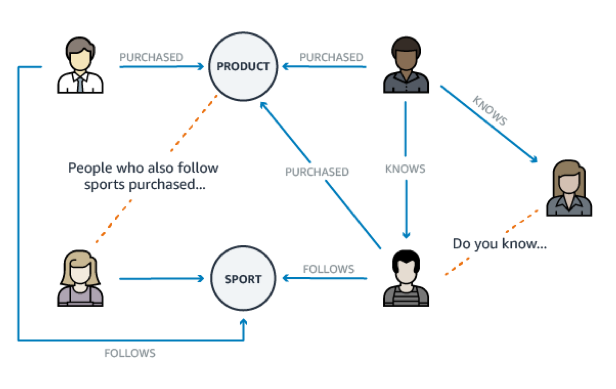
推荐引擎
推荐引擎会存储信息之间的关系:消费者的兴趣,朋友和支付历史。通过图形,能够快速提出与用户相关的个性化建议。
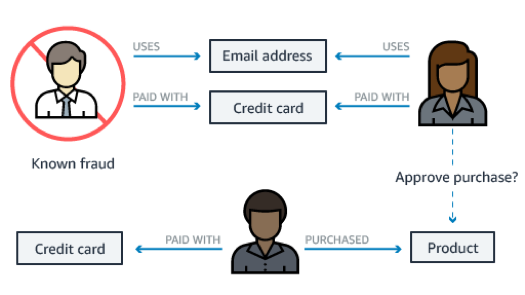
欺诈探测
如果你正在构建一个面向零售的欺诈检测应用程序,图形可以帮助你更轻松地查询关系模式。很多人可能与某个人的电子邮件地址有关,或者多人共享同一个 IP 地址但是有着不同的物理地址。
存储图的难点
图形可以用多种方式存储:关系型数据库,键值对存储或者图形数据库。很多人开始使用带有小型原型的图。通常开始还行,但是随着数据规模的增加就难搞了。基于图形的工作负载往往有高度的随机访问权限。当你在遍历关系(图形扇出),访问的节点数显著增加,并且图形查询的结果数据通常在内存中没有缓存(非本地性)。甚至看似简单的图形查询也要扫描大量数据。这意味着伸缩和操作图形数据库通常需要大量的手动性能调整和优化。
关系形数据库或者键值存储的用户必须使用 SQL 连接语句来查询关系。因为 JOIN 执行速度很慢,所以它们通常必须对数据模型进行非规范化(换句话说,以牺牲写性能为代价来提高读性能)。但是对于非规范化的数据模型,添加每个新的关系都会更改数据模型导致降低开发速度。
图形数据库专为存储图形打造,允许直接链接节点中的数据并直接查询关系。创建新关系就很容易而无需数据非规范化,开发人员能够更轻松地更新数据模型,这极大地提高了查询数据关系的性能。
原文
Have you ever received a call from your bank because they suspected fraudulent activity? Most banks can automatically identify when spending patterns or locations have deviated from the norm and then act immediately. Many times, this happens before victims even noticed that something was off. As a result, the impact of identity theft on a person’s bank account and life can be managed before it’s even an issue.
Having a deep understanding of the relationships in your data is powerful like that.
Consider the relationships between diseases and gene interactions. By understanding these connections, you can search for patterns within protein pathways to find other genes that may be associated with a disease. This kind of information could help advance disease research.
The deeper the understanding of the relationships, the more powerful the insights. With enough relationship data points, you can even make predictions about the future (like with a recommendation engine). But as more data is connected, and the size and complexity of the connected data increases, the relationships become more complicated to store and query.
In August, I wrote about modern application development and the value of breaking apart one-size-fits-all monolithic databases into purpose-built databases. Purpose-built databases support diverse data models and allow customers to build use case–driven, highly scalable, distributed applications. Navigating relationships in data is a perfect example of why having the right tool for a job matters. And a graph database is the right tool for processing highly connected data.
Graph data models
In a graph data model, relationships are a core part of the data model, which means you can directly create a relationship rather than using foreign keys or join tables. The data is modeled as nodes (vertices) and links (edges). In other words, the focus isn’t on the data itself but how the data relates to each other. Graphs are a natural choice for building applications that process relationships because you can represent and traverse relationships between the data more easily.
Nodes are usually a person, place, or thing, and links are how they are all connected. For example, in the following diagram, Bob is a node, the Mona Lisa is a node, and the Louvre is a node. They are connected by many different relationships. For example, Bob is interested in the Mona Lisa, the Mona Lisa is located in the Louvre, and the Louvre is a museum. This example graph is a knowledge graph. It could be used to help someone who is interested in the Mona Lisa discover other works of art by Leonardo da Vinci in the Louvre.
Applications that process relationships
A graph is a good choice when you must create relationships between data and quickly query those relationships. A knowledge graph is one example of a good use case. Here are a few more:
Social networking
Social networking applications have large sets of user profiles and interactions to track. For example, you might be building a social feed into your application. Use a graph to provide results that prioritize showing users the latest updates from their family, from friends whose updates they ‘Like,’ and from friends who live close to them.
Recommendation engines
Recommendation engines store relationships between information, such as customer interests, friends, and purchase history. With a graph, you can quickly query it to make recommendations that are personalized and relevant to your users.
Fraud detection
If you’re building a retail fraud detection application, a graph helps you build queries to easily detect relationship patterns. An example might be multiple people associated with a personal email address, or multiple people sharing the same IP address but residing in different physical addresses.
The challenges of storing a graph
Graphs can be stored in many different ways: a relational database, key value store, or graph database. Many people start using graphs with a small-scale prototype. This typically starts out well but becomes challenging as the data scale increases. Graph-based workloads tend to have a high degree of random access. The number of nodes visited increases significantly as you traverse relationships (graph fan-out), and the data required to answer a graph query are often not cached in memory (non-locality). Even seemingly simple graph queries can require accessing and scanning a large amount of data. This means that scaling and operating graph databases often requires significant manual performance tuning and optimization.
People who use a relational database or a key value store for a graph must use SQL joins (or an equivalent) to query the relationships. Because joins can execute slowly, they often must denormalize their data model (in other words, improve read performance at the expense of write performance). However, with a denormalized data model, each new relationship added requires a data model change and reduces the pace of development.
Graph databases are purpose-built to store graphs and allow data in the nodes to be directly linked and the relationships to be directly queried. This makes it easy to create new relationships without data denormalization, and makes it easier for developers to update their data models for applications that must query highly connected data. It dramatically improves query performance for navigating data relationships.