Uber 分布式数据库迁移
Dec 29, 2022 21:30 · 2440 words · 5 minute read

原文:https://www.uber.com/blog/mysql-to-myrocks-migration-in-uber-distributed-datastores/
介绍
Uber 使用 MySQL 作为 Schemaless 和 Docstore 的底层数据库引擎。MySQL 默认使用最流行的 InnoDB 引擎,这是一种 B+ 树结构的数据存储。[MyRocks] 是另一种集成了 RocksDB 的 MySQL 存储引擎。RocksDB 基于日志结构的合并树(或 LSM 树)并且针对快速存储优化过,将出色的空间和写入效率与可接受的读取性能相结合。
Uber 存储平台团队自从 2019 年开始就已经所有 Schemaless 实例和部分 Docstore 实例迁移至 MyRocks。
动机
Schemaless/Docstore 为很多关键业务和平台服务,例如打车、外卖、零售、地图、支付等等。两者都存储几十 PB 的数据,每秒处理几千万个请求。随着 Uber 业务的增长,这些数字只会增大而且磁盘空间成为了瓶颈:有些节点的数据量达到了几 TB,这使得一些日常的运维任务变得更困难,比如数据重新同步和备份。
磁盘成为瓶颈,导致 CPU 和内存资源利用不完全,提高了运行 Schemaless 的成本。对我们来说解决这个问题并降低成本是至关重要的。
挑战
一种解决方案是拆分节点以分布磁盘空间,但是不仅耗时,而且在某些实例上还有分片限制,鉴于我们的规模和增速,不是一个长期可持续的方案。我们尝试着用 InnoDB 表压缩技术来缓解磁盘压力,这只节省了大约 5% 的磁盘空间,因为数据在被存储到数据库之前已经由查询引擎层压缩过,额外的压缩效果不大。
在寻找解决方案的同时,我们用 MyRocks 做了一个基准测试,在适当的延迟下节省了 30% 以上的磁盘空间。一个主要原因是 RocksDB 不使用固定的页面大小,因此可以实现高效的压缩,浪费最少。而且 InnaDB 使用 B+ 树索引可能会碎片化,导致占用额外的磁盘空间。
基本上 MyRocks 就是带有 RocksDB 存储引擎的 MySQL。它有相同的客户端协议,无需改动我们的查询引擎层和客户端,因此我们得出结论,MyRocks 将是支持 Uber 快速业务增长进而导致数据库容量增大的最佳选择。
如此大规模的数据和节点迁移同时保证严格的 SLA 和一致性、可用性还有透明度是很难的。这些挑战包括:
- 详尽的自动迁移策略,不影响下游服务或活用,包括回滚计划。
- 确保迁移后的读取性能是可以接受的。
- 在迁移之前大规模从 MySQL 5.7 升级到 MySQL 8.0 以适应 MyRocks 的版本要求。
- 快速解决 MyRocks 中的 bug。
升级和迁移
Schemaless/Docstore 实例的拓扑结构中数据是分片的,映射至可配置数量的物理分区。每个分区在单个区域内有多个数据副本,并通过 Raft 共识协议保证一致性。分区也会跨地域区域复制。
为确保迁移对用户透明且无影响,我们设计了一种增量迁移策略,从单个分区到多个分区,从单个区域到所有区域。在每个节点迁移期间,我们验证了数据的完整性并监控延迟和错误率以确保没有性能下降,所有这些都是自动完成的。
升级 MySQL 8.0
Uber 利用 XtraBackup 来做数据同步和备份。Xtrabackup 从 MySQL 8.0 版本开始支持 MyRocks,所以作为 MyRocks 迁移进程的第一步,我们要把集群升级到 MySQL 8.0。另一个升级动机则是因为 Docstore 计划使用 MySQL 8.0 提供的 JSON 特性。
我们只通过替换二进制就地进行了 MySQL 升级。总体步骤如下:
- 升级单个区域中单个分区的一个 follower
- 升级同一个区域中相同分区的所有 follower
- 升级同一个区域中相同分区的 leader
- 在相同区域中重复上述步骤
- 在另一个区域中重复上述步骤
Uber 在 2018 年用了几个月将 MySQL 从 5.6 升级到 5.7,但是从 5.7 升级到 8.0 用了一年。我们花了很多时间解决在 MySQL 8.0 中遇到的 bug 和性能下降,包括:
- MySQL 8.0 相较于 5.7 内存占用更多
- 由于 MySQL 优化器变更而导致不同的执行计划,例如 bug 104083
- 如果表太多,MySQL 升级需要很长时间才能填充数据字典表
- 线程阻塞在等待 THD::release_resources 上 PS-7525
- InnoDB 索引数损坏
MyRocks 迁移
我们同时在已经升级到 MySQL 8.0 的节点上将 MySQL 迁移至 MyRocks。与 MySQL 就地升级不同,MyRocks 迁移策略有点像 MySQL 逻辑升级:我们向一个区域添加额外的节点,使用 Xtrabackup 并在它们上面启动迁移进程。
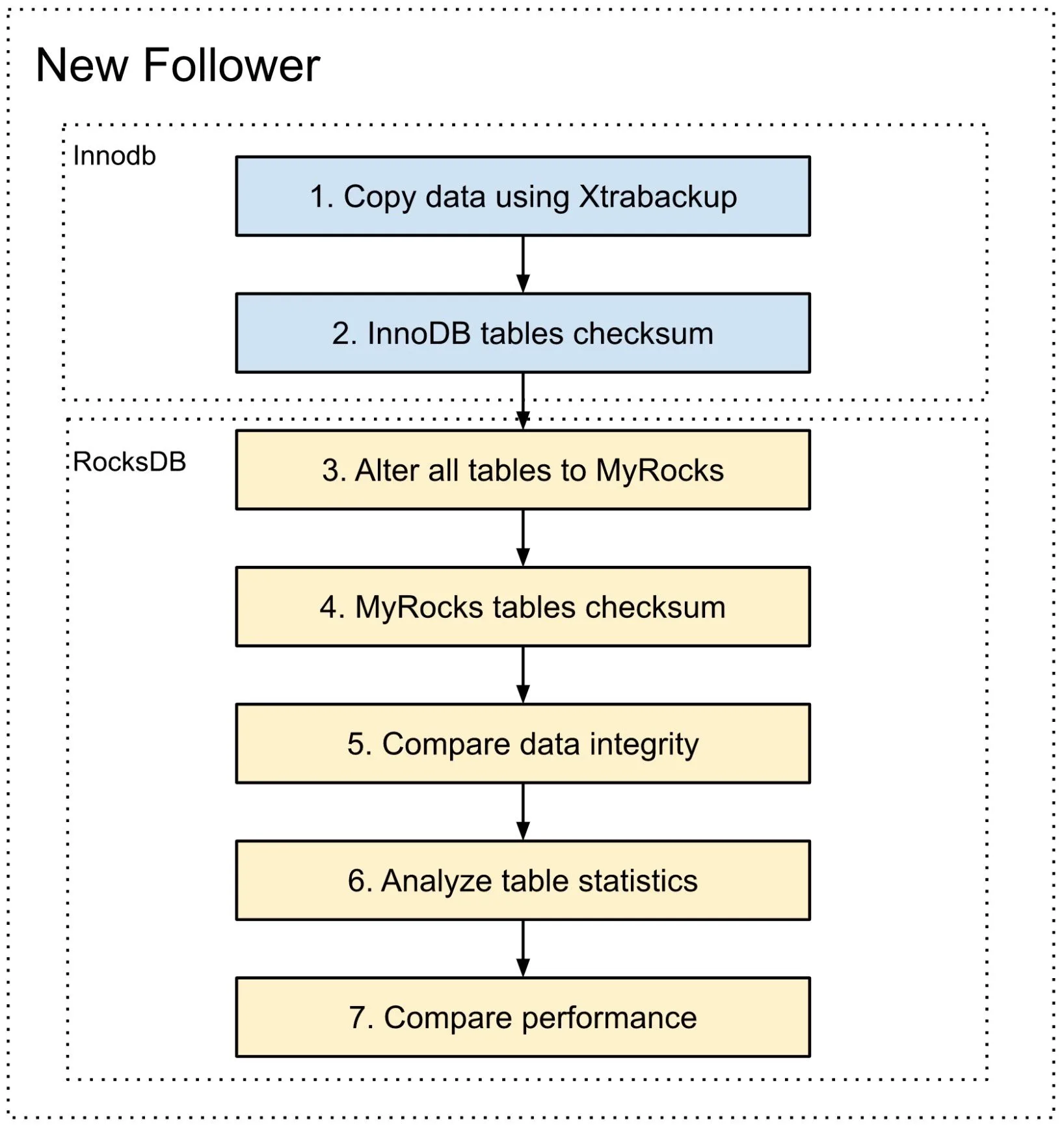
节点迁移包括每张表上的引擎转换,还有一系列验证来确保 MyRocks 节点提供与 InnoDB 节点相同的数据一致性和查询性能。
- 首先我们需要构建一个节点。我们持续使用 Xtrabackup,它在 Uber 内部已经验证过比其他方式(比如 mysqldump)快速和靠谱。
- 为了确保迁移过程中没有数据损坏或丢表,我们收集了每张表的校验和,还有表号。
- 通过 RocksDB 批量加载模式,我们使用多线程更改所有用户表至 RocksDB 引擎。
- 在改完所有表后,我们就像步骤 2 那样收集相同的信息,但是在 MyRocks 上。
- 是时候对比步骤 2 收集到的 InnoDB 和步骤 4 收集到的 MyRocks 信息了。我们看到有时将数据表变更至 RocksDB 引擎,如果 MySQL 被 OOM,MySQL 重启后有些表不见了。
- 分析数据表重新生成 MyRocks 的统计数据。不能保证每个执行计划在转换后仍旧是一样的,所以分析数据表可以避免这种执行计划的改变,这可能会导致 SQL 性能下降。
- 为了对比性能,我们在 MyRocks 节点上回放了实时的生产查询以比较结果。我们遇到了一个问题,同样的查询 InnoDB 和 RocksDB 引擎返回了不同的结果(PS-7722)。我们也重放了查询来比较执行计划和执行时间,确保性能没有下降。
如果分区中的第一个节点成功转换至 MyRocks 并且通过了全部验证,我们将继续处理同一分区中的剩余节点。
- 添加第二个 MyRocks 节点作为 follower
- 添加第三个 MyRocks follower 节点(此时分区中有 3 个 MyRocks 2 个 MySQL 节点)
- 将 MyRocks 提升为 leader 接管服务的写流量
- 一个接一个移除 MySQL 节点
我们并行地在一个区域内的所有分区重复上述步骤,在完全转换为 MyRocks 后,我们暂停了该过程并比较两个区域的性能(例如延迟、错误率、CPU/IO 使用率等等)。如果需要我们仍可以回滚并将流量切换到 MySQL 的区域。
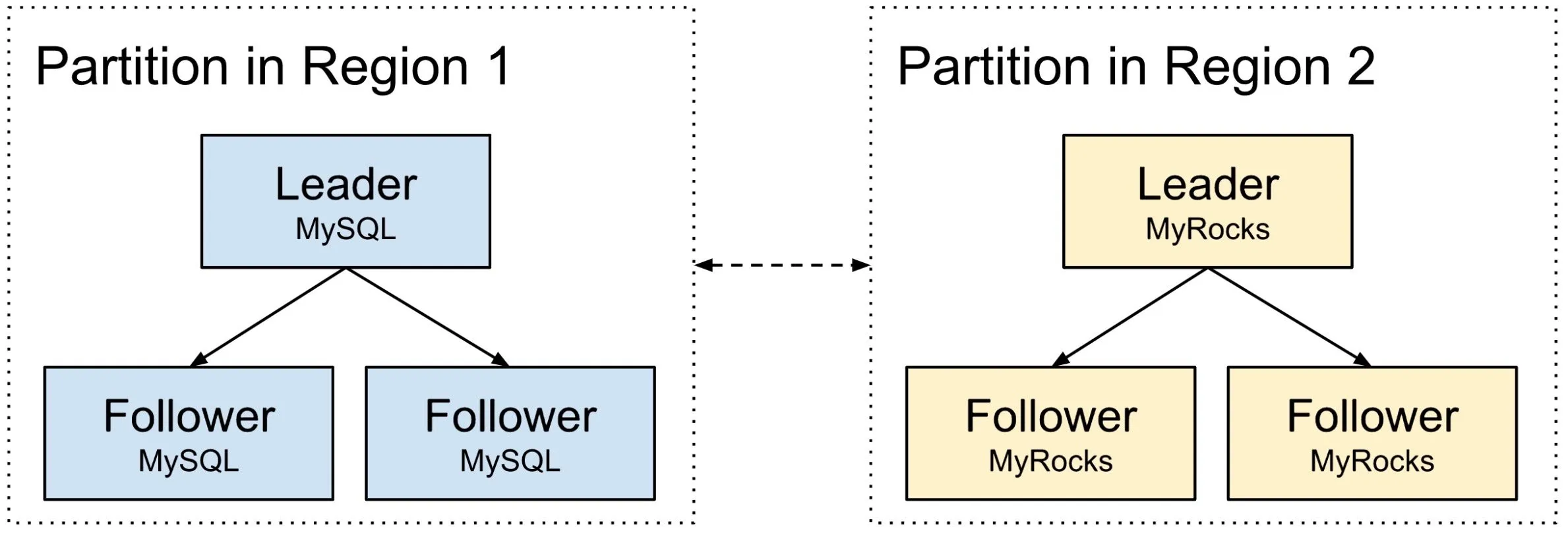
如果 MyRocks 区域万事大吉,我们就开始对下一个区域迁移。这时我们不会再增加一个额外的 MyRocks 节点了,因为一切都已经在之前的区域中经过了验证——就用 MyRocks 替换 MySQL 以节省需要的额外容量。最后我们在一个 Schemaless/Docstore 实例上完成了 MyRocks 迁移。
总结
通过迁移至 MyRocks 我们看到磁盘空间节省了 30% 以上。然而我们从迁移中得到的结论是,并非所有使用案例都可以迁移到 MyRocks。我们观察到一些实例的 CPU 和磁盘 IO 使用率更高了,这是节省磁盘空间带来的副作用。
整个升级和迁移的耗时比最初预计的要长。其中一个原因是 MyRocks 是一个非常新的数据库,没有成熟的社区可以让我们获取支持,我们需要等待来自 Percona 的补丁,或者在遇到问题时自己研究和解决。