Megatron:3D 并行训练 LLM
Jul 10, 2025 23:30 · 965 words · 2 minute read
原文 Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
1 介绍
实现一种简单、高效的层内并行方法,用数十亿参数训练 transformer 模型。不需要新的编译器或 library 的变更,与流水线模型并行正交互补,在 PyTorch 中插入少量通信操作即可实现。
项目仓库:https://github.com/NVIDIA/Megatron-LM
2 背景
- Neural Language Model 预训练
- Transformer 模型和 Multi-Head Attention
- 深度学习中的数据和模型并行
扩展深度神经网络训练规模的两个范式:
- 数据并行(Data Parallelism):一个训练小批量被切分到多个 worker 上
- 模型并行(Model Parallelism):模型的内存使用和计算被分配到多个 worker 上
随着模型规模不断增长,一张 GPU 的显存放不下,就利用模型并行将模型拆分到多个 GPU 上。
模型并行中的两种范式:
-
层级流水线并行(layer-wise pipeline parallelism)
一组操作在一个设备上执行,输出传递到流水线的下一个设备执行另一组操作。存在一致性问题。
-
分布式张量计算(distributed tensor computation)
更通用,将张量操作分配到多个设备上,来加速计算或增加模型尺寸。
3 模型并行 Transformers
transformer 层由两部分组成:
- self attention
- MLP(Multi-Layer Perceptron)
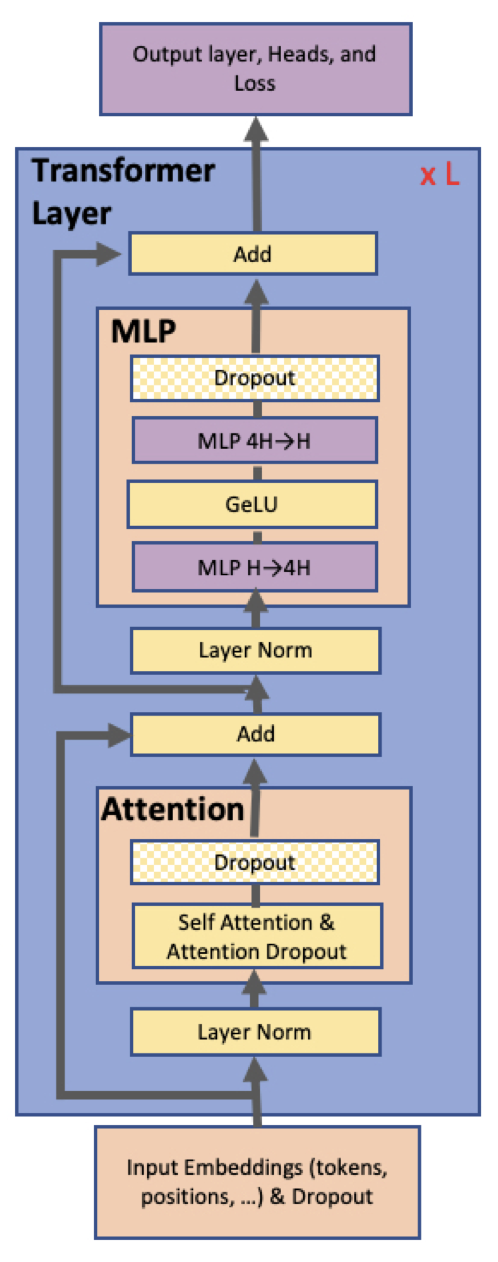
MLP
MLP 块,先 GEMM 再 GeLU:
$${Y} = \mathrm{GeLU}({X}{A})$$并行化 GEMM 的一种方法是切权重矩阵,两种切法:
-
按行切
$${X} = [X_1, X_2], \quad {A} = \begin{bmatrix} A_1 \\ A_2 \end{bmatrix}$$$${Y} = \mathrm{GeLU}(X_1A_1 + X_2A_2)$$在 GeLU 函数之前需要一个同步点。
-
按列切
$${A} = [A_1, A_2]$$$$\left[ Y_1, Y_2 \right] = \left[ \mathrm{GeLU}(X A_1),\ \mathrm{GeLU}(X A_2) \right]$$这样的优势是消除了一个同步点。
第一个 GEMM 按列切,再做 GeLU,无需任何通信。 第二个 GEMM 按行切,dropout 前只需做一次 all-reduce(正向传递 g 算子)。
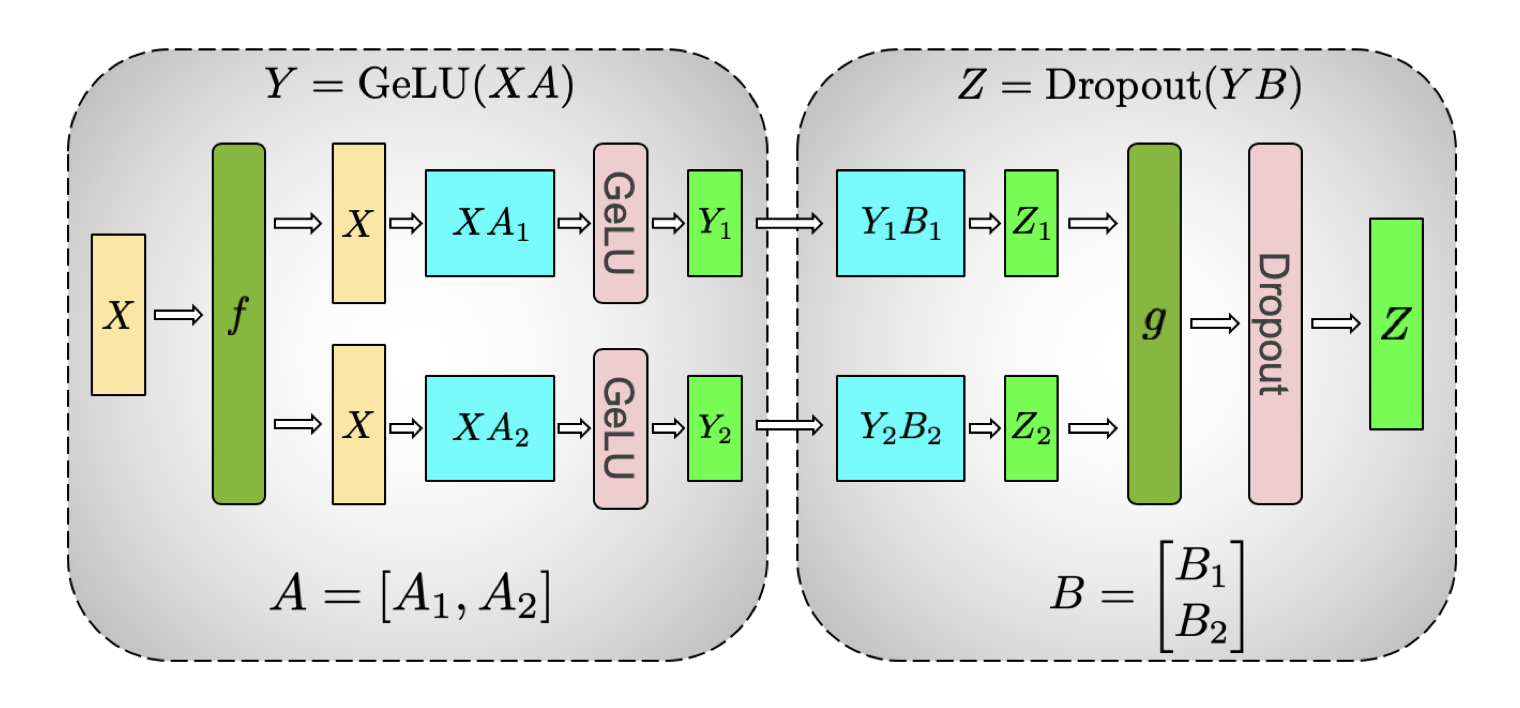
self attention
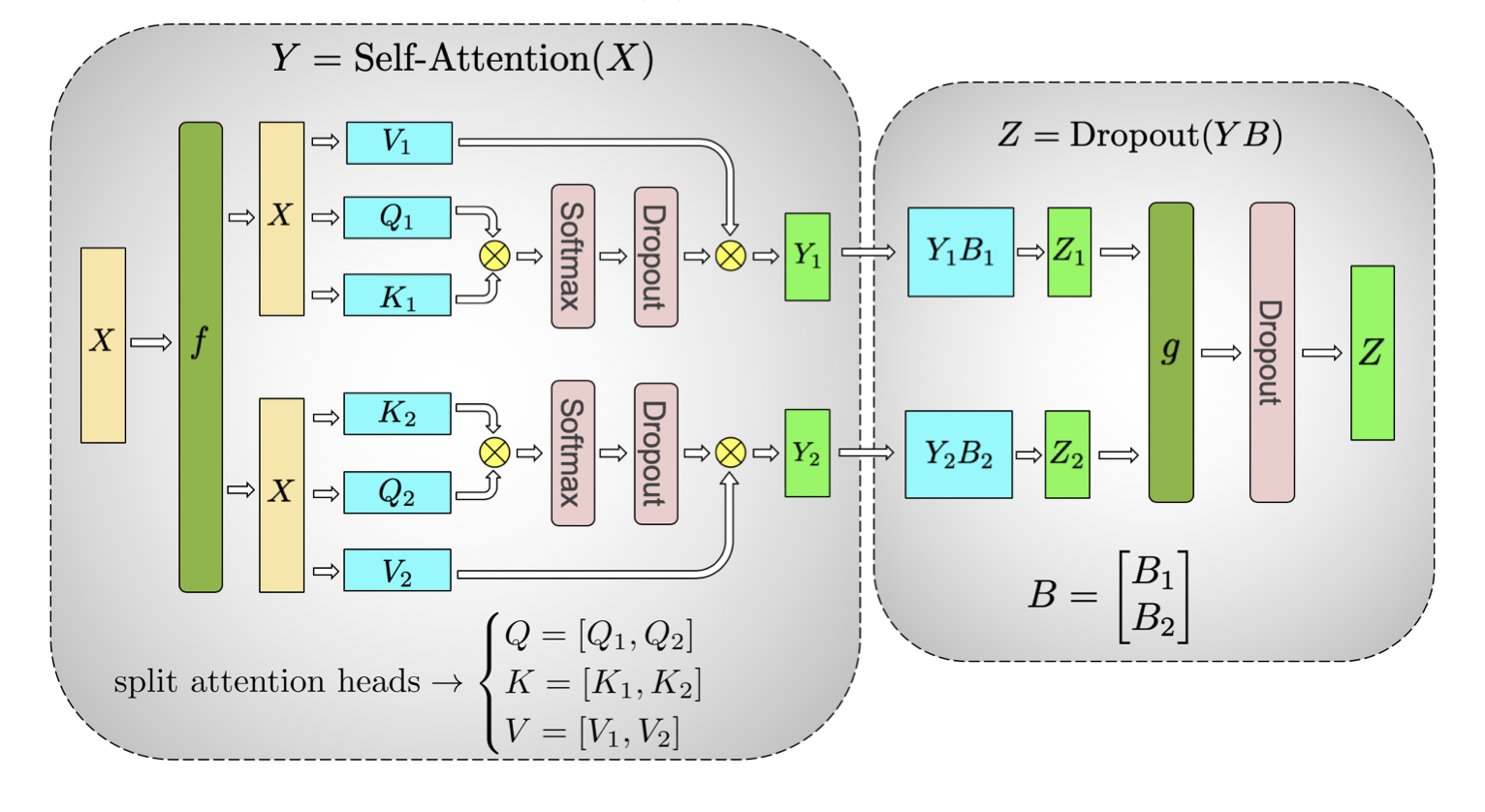
把 K、Q、V 都按列切成两份,使得每个 attention head 对应的矩阵乘在单个 GPU 上本地完成(无需通信)。
在单个 GPU 上先做 \({K_n} \times {Q_n}\),结果先做 softmax 和 dropout 再乘 \({V_n}\) 得到 \({Y_n}\)。
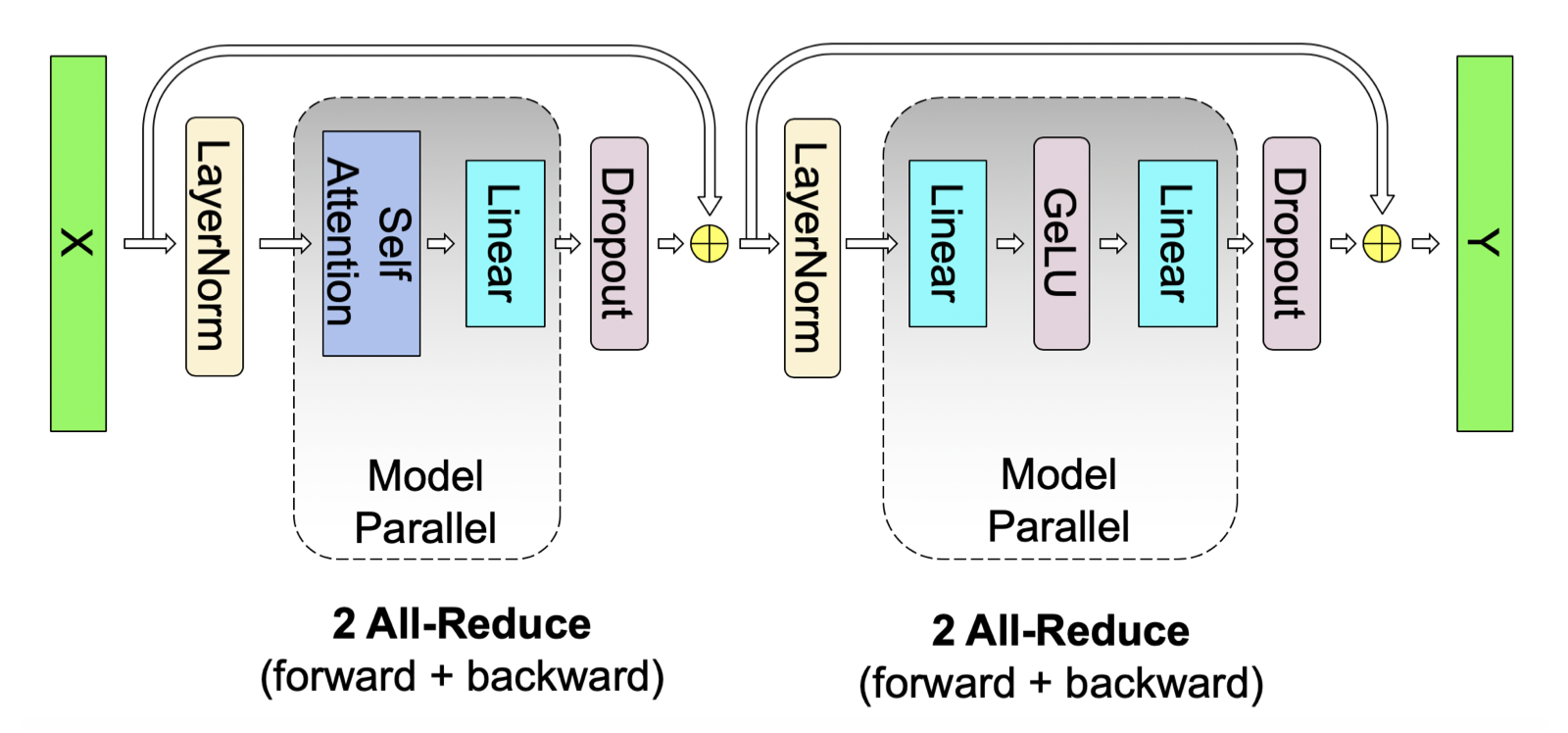
在简单 transformer 层中仅使用前向路径中的两次 all-reduce 和后向路径中的两次 all-reduce 来执行所有 GEMM。
模型并行旨在保持 GPU 计算,减少通信,这是 Megatron 的核心。
实验相关略
4 结论
通过少量修改现有的 PyTorch Transformer,成功超越传统单 GPU 训练模型的限制,实现了模型并行。在 512 块 NVIDIA V100 GPU 上使用 8 路模型并行高效地训练了最多 83 亿参数的 Transformer 基模型,并在过程中持续达到了最高 15.1 PFLOPs 的性能。
术语
- MLP(Multi-Layer Perceptron):多层感知器
- GEMM(General Matrix Multiply):通用矩阵乘法
- GeLU(Gaussian Error Linear Unit):高斯误差线性单元