MegaScale:万卡训练 LLM
Jun 10, 2025 00:30 · 2491 words · 5 minute read
原文 MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
1 介绍
MegaScale 用于万卡训练 LLM,超大规模带来两个调挑战:
- 训练效率:MFU 是评估训练效率的标准指标
- 稳定性:LLM 的训练时间很长,虽然故障和慢节点是常态,但它们确实会拖慢整个任务进度
MegaScale 两个原则:
- 算法与系统协同设计
- 深度的可观测性
核心思想:最大化通信与计算的重叠。
尽可能在 IO 的同时计算
很多难以解决的稳定性问题仅在大规模环境下出现,可能源于深层的软硬件故障。不可能手动排查每个问题,必须依赖可观测性。构建监控和可视化工具,细粒度地收集系统每个组件的数据。这套工具包括:
- 训练框架:故障定位和恢复自动化
- 心跳信息:实时异常检测和早期提醒
- 诊断测试套件:识别导致中断的节点
- 优化检查点和恢复过程:降低中断的影响
- 性能分析工具:记录细粒度的 CUDA 事件,生成系统层的热图
- 3D 并行训练可视化工具:展示各 rank 之间的数据依赖关系以便诊断
3 背景
3D 并行
- Data parallelism
- Pipeline parallelism
- Tensor parallelism
以上并行策略可以组合成 3D 并行,实现跨多个 GPU 的规模化 LLM 训练。
张量并行高通信开销,最好限制在单个节点内;相反数据并行和流水线并行更适合节点间通信。在本例中优先选择数据并行。
3 大规模高效训练
4 个最先进:
- 算法优化
- 通信策略
- 数据流水线管理
- 网络性能调优
3.1 算法优化
略过。
3.2 3D 并行中的通信重叠
系统地分析 3D 并行中所有算子与通信的依赖关系,隐藏所有非关键路径操作的开销。
-
data parallelism
两个主要通信操作:
- all-gather
- reduce-scatter
第一个 all-gather 和最后一个 reduce-scatter 无法被隐藏。
初始的 all-gather 在每个迭代开始时预先获取,使其与数据加载操作重叠。
先启动高优先级通信以最大化重叠。
-
pipeline parallelism
特性包括 p2p 发送/接收通信
MegaScale 使用交错 1F1B 调度方法。将发送和接收解耦,这两个操作可能被较慢的操作阻塞。
- warm-up 做完一次完整的前向之前的阶段
- steady 一次前向一次反向
- cool-down 是 warm-up 的逆过程
-
tensor parallelism
用于在计算密集型操作中划分权重。
将 all-gather 和 reduce-scatter 与 FFN 路径上的并行 Linears 融合。
FFN 路径上的 GEMM 内核较大,通信可以更好地被隐藏。将 GEMM 内核拆分成小块,流水线化通信的执行。
3.4 数据流水线
优化数据预处理和加载:
-
异步数据预处理
GPU 工作线程在训练步骤结束同步梯度时,后续的数据预处理就可以开始了。
-
消除冗余数据加载
两层树状结构:
- 用专用的数据加载器将训练数据读取到一块共享内存中。
- 每个 GPU 从共享内存中复制所需数据至 GPU 内存。
3.5 集合通信组初始化
torch.distributed 建连的开销随着集群规模的增大而增加。初始化时间过长的两解法:
- 第一个问题出在同步步骤中,将 TCPStore 换成 Redis,因为后者是异步非阻塞的。
- 第二个问题与全局屏障的使用不当有关,重新设计通信组初始化的顺序,以最小化对全局屏障的需求。
3.6 网络性能调优
-
网络拓扑
三层交换机以类 CLOS 拓扑连接。
每一层交换机的下行与上行链路带宽 1:1。
-
减少 ECMP 哈希冲突
策略性地调度训练任务中的数据密集型节点,使其在同一个顶级交换机(ToR)下,减少通信所需的交换机跳数,进一步降低了 ECMP 哈希冲突的概率。
-
拥塞控制
算法结合 Swift 和 DCQCN,减少 PFC 拥塞。
-
超时重传设置
调整 NCCL 控制重传定时器和重试的参数。
在网卡上启用 adap_retrans 功能。
4 容错
软件和硬件故障是不可避免的。自动故障识别和快速恢复可由训练框架实现。
4.1 训练工作流
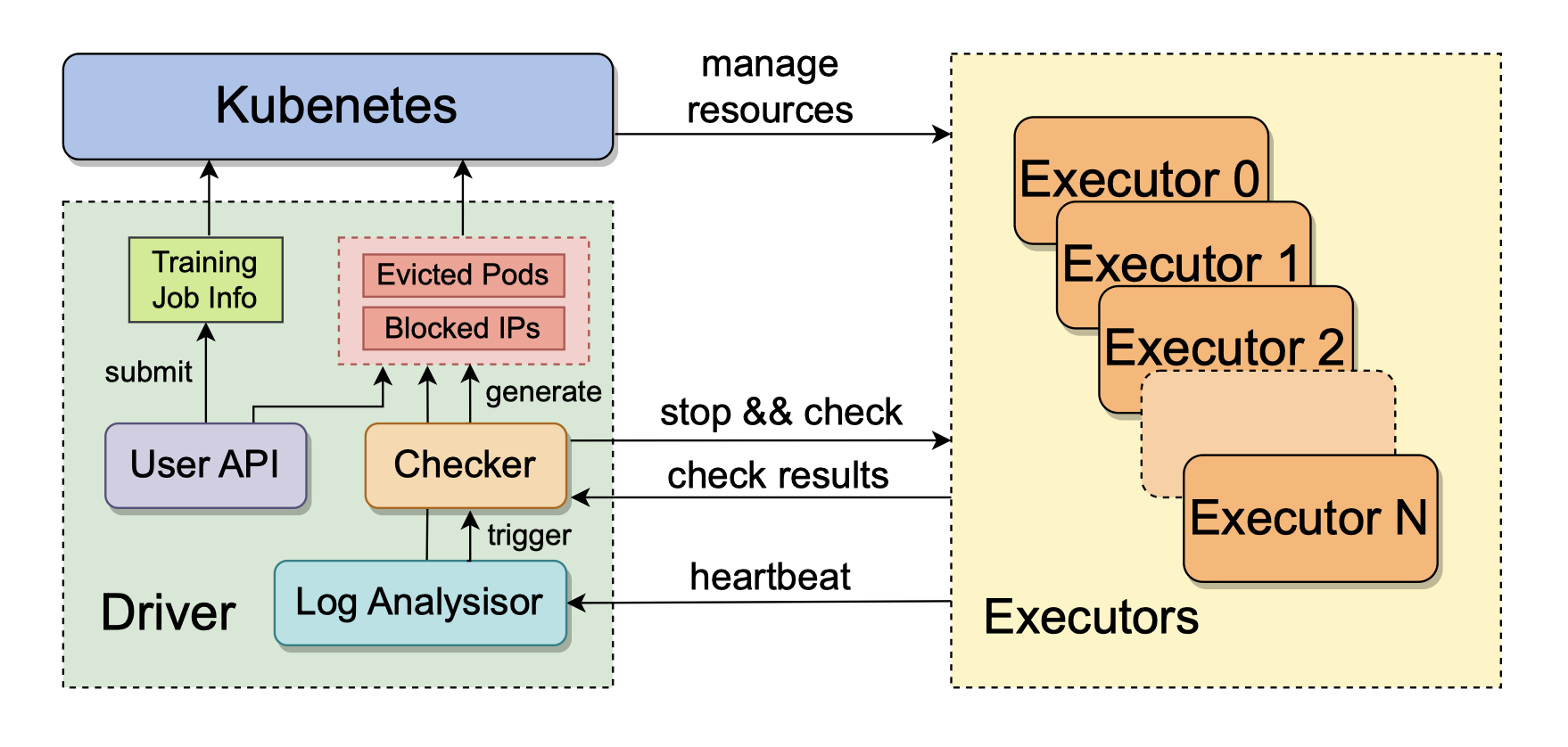
每节点由一个执行器管理,创建训练进程的同时启动一个守护进程向 driver 定时发送心跳。心跳封装的信息实时检测异常和预警。
driver 检测到训练进程异常,出发故障恢复流程:
- 暂停训练任务
- 运行自检以诊断
- 识别故障节点,Kubernetes 将其驱逐
- 补充等量健康节点到集群
- driver 从最新的检查点恢复训练任务
4.2 数据收集与分析
心跳消息包含:
-
IP 地址
-
Pod 名称
-
硬件信息
-
当前训练进程状态
-
训练进程的 stdout/stderr 日志
driver 聚合、过滤分析日志,检测特定错误
-
RDMA 指标
训练过程中的某些异常不明显,检测每个步骤的流量特征(RDMA 流量显著下降或异常波动是潜在异常的信号)
监控与可观测非常重要!
4.3 诊断测试
自检诊断要权衡执行时间和准确性。
-
网络测试
测试两点:
- 所有 RDMA 网卡到主机内各端点的回环带宽,根据结果推断链路特定的带宽下降和 PCIe 异常。
- 同一主机上 RDMA 网卡到 RDMA 网卡测试检查网卡之间的连接和带宽,看硬件速度是否达标以及路由配置是否正确。
-
NCCL 测试
在单个节点上测试全互通,观察带宽;与同一 ToR 交换机下的邻近机器 all-reduce 测试,评估节点间 GPU 通信。
4.4 快速恢复
恢复依赖检查点,要权衡检查点的保存频率:检查点越接近故障时的训练进度,计算时间的损失越小;但保存检查点会影响训练效率。
两阶段保存检查点:
- 将 GPU 片上状态写入宿主机内存。
- 后台进程异步地落到持久化存储上,例如 HDFS。
瓶颈是 HDFS 带宽,可优化数据检索策略。
5 训练 Troubleshooting
系统看似正常运行,但实际上停止计算(例如训练进程 hang 死)。要靠监控和分析工具来检测异常。
5.1 CUDA Event Monitor
针对诊断大规模训练性能不稳定的问题,基于 CUDA 事件方法开发一个性能分析工具,记录每个机器上关键代码的执行时间,提供可视化。
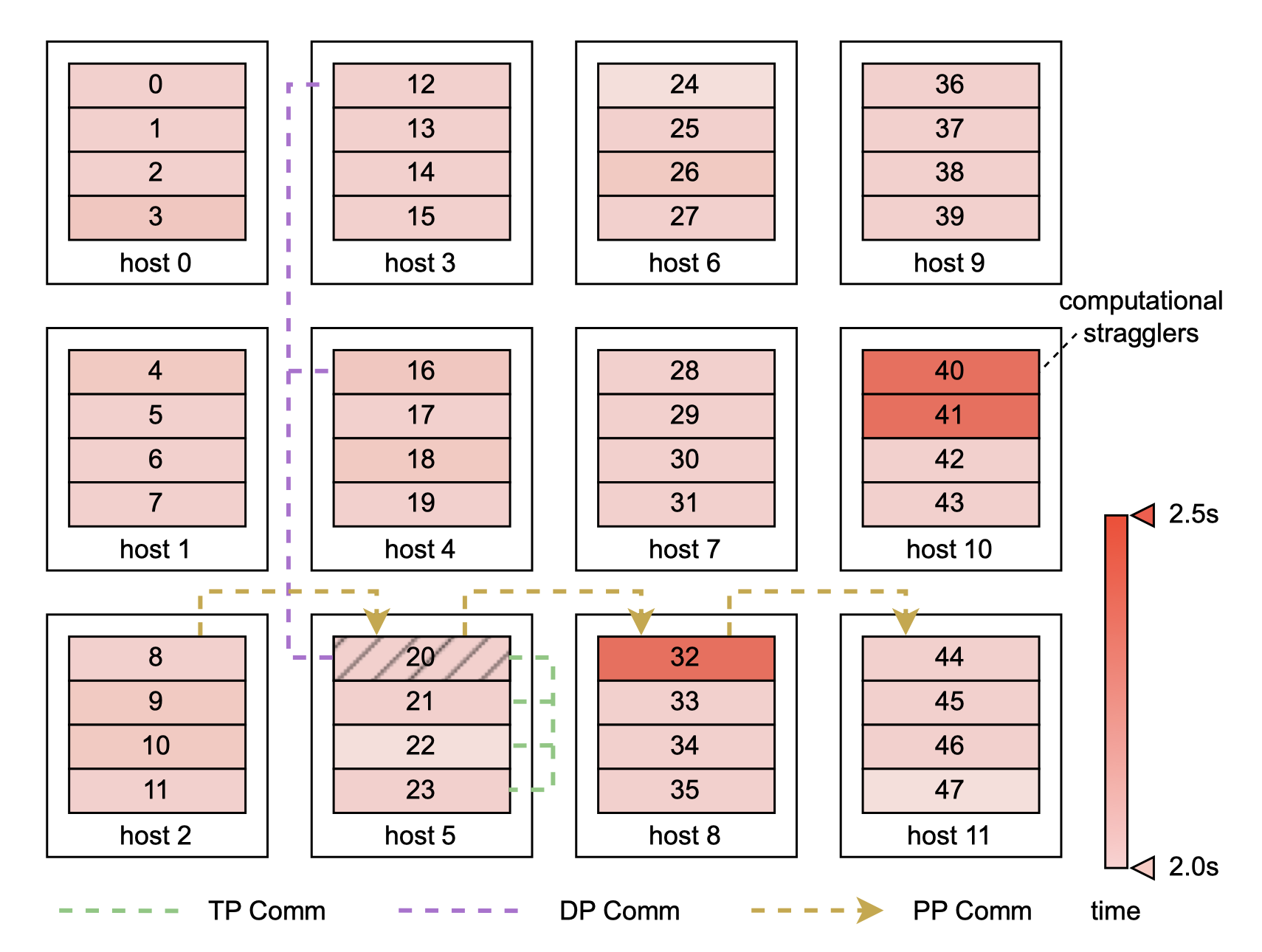
热图模式,颜色越红节点越慢。

另一种模式展示不同分布视图(3D)的机器上的事件时间线。将各个 rank 的追踪区间聚合到单一时间线上,获得了全面的视角。
CUDA 事件计时器的每条数据先写入本地文件,再异步地发送到远程分析数据库。
5.2 3D 并行训练可视化
为了快速定位问题节点,让每个 GPU 工作进程在超时时记录自身正在进行的事件,这些日志用于构建基于 3D 并行逻辑拓扑的数据依赖关系的可视化。通过检查日志和可视化工具中的数据流,就可以轻松地定位问题节点。
6 经验
6.1 训练性能
比较 MegaScale(也是基于 Megatron-LM 构建的)和原生 Megatron-LM。比较方法:
- 使用相同的 batch size
- 1750 亿和 5300 亿两种模型尺寸
- 分别使用六阶段和三阶段交错流水线并行调度
唯一比较指标:MFU
通信是大规模 LLM 训练的主要瓶颈。
6.3 发现并解决的问题
-
慢节点
机器自身存在问题,并非软件,将其从集群中驱逐后 MFU 有所提升。
-
MFU 衰减
现象是训练效率会随着训练的推荐而下降。分析 CUDA 事件计时器指标,所有 rank 都必须等待最慢的 rank。这种不规律归因于某些代码片段引起的波动:不规则的垃圾回收会干扰训练过程,某些 PyTorch 操作也会导致性能波动。
-
频繁的网络抖动
- 超时阈值应明确设置为更大的值,否则默认值会很快使 NCCL 超时。
- 网卡、AOC 光缆、交换机之间的链路质量差。
术语
- MFU(Model FLOPs utilization) 模型 FLOPs 利用率
- FNN(Feedforward Neural Network) 前馈神经网络
- GEMM(General Matrix Multiply) 通用矩阵乘法
- PFC(Priority-based Flow Control) 基于优先级的流量控制,是目前应用最广泛的能够有效避免丢包的流量控制技术,是智能无损网络的基础。
- DCQCN(Data Center Quantized Congestion Notification) 数据中心量化拥塞通知