MapReduce 为何如此设计
Jun 24, 2021 22:10 · 5580 words · 12 minute read

作为 Google 三剑客(MapReduce、BigTable 和 GFS)之一,MapReduce 出自 Jeffrey Dean 和 Sanjay Ghemawat 于 2004 年在 OSDI 发表的同名论文 https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf。
当时的 Google 就已经需要处理海量数据,例如为爬取到的网页文本、web 服务请求日志这类原始数据计算倒排索引(inverted indices)、网络文件的图形结构呈现、某一天最频繁的查询集合等等。尽管计算本身简单明了,然而输入数据太过庞大,为了节省大量时间不得不将其分发至成百上千台机器上并行计算:
- 如何并行计算
- 分发数据
- 错误/故障处理
大量的代码都用于处理这些问题,使得原本的简单计算变得非常复杂。
受到 Lisp 语言中 map 和 reduce 函数的启发,Jeff 意识到绝大部分计算都可以抽象为对输入的“逻辑记录”应用 map 操作来计算出一组中间态的键值对,然后对所有 key 相同的值应用 reduce 操作来合并衍生数据。所以他们要设计一种程序模型来让用户自定义 map 和 reduce 操作,而自动的大规模并行计算、重试和错误处理都由框架来封装,在集群中实现高性能。
Our abstraction is inspired by the
mapandreduceprimitives present in Lisp and many other functional languages. We realized that most of our computations involved applying a map operation to each logical “record” in our input in order to compute a set of intermediate key/value pairs, and then applying a reduce operation to all the values that shared the same key, in order to combine the derived data appropriately.
1. 程序模型
计算的输入和输出都是一组键值对。
整个计算的步骤为:Input -> Split -> Map -> Shuffle -> Reduce -> Finalize,都是由 MapReduce 库也就是计算框架提供的,而用户只需要将计算行为抽象成 Map 和 Reduce 两个函数:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, 1);
reduce(String key, Iterator values):
// key: a word
// value: a list of counts
int result = 0;
for each v in values:
result += 1;
Emit(result);
- Map 函数(由用户自行实现)以一对键值作为输入,输出一组中间态键值对
- MapReduce 库会将 Map 函数生成的具有相同 key 的键值对汇总起来后按 key 分别传递给 Reduce 函数(这个步骤叫做 Shuffle)
- Reduce 函数(也由用户自行实现)以某个 key 和所有该 key 关联的键值对作为输入,它将这些数据合并成一组更少的值。通常每个 Reduce 只输出不多于一个值。
Google 的 MapReduce 库(由 C++ 实现)会将用户代码链接到一起。
2. 应用
- 分布式搜索
- URL 访问频率计数
- 倒排索引
大家可以先自己想想如何将以上需求拆解成符合 MapReduce 模型的 map 和 reduce 操作,并与 Google 给出的案例对照。
- 分布式搜索
- map 输出匹配的字符串为中间态数据
- reduce 将中间态数据直接输出
- URL 访问频率计数
- map 处理网页访问请求并输出 <URL, 1> 作为中间态数据
- reduce 将相同 URL 的所有值累加输出 <URL, total count>
- 反转超链接图
- map 输出所有的指向某个目标 URL 的链接 <target, source>
- reduce 将指向某个目标 URL 的所有链接汇聚成列表并输出 <target, list(source)>
- 倒排索引
- map 解析每个文档,并输出 <word, document ID> 作为中间态数据
- reduce 接收同一个 word 的所有值,对 document ID 排序并输出 <word, list(document ID)> 键值对
- 分布式排序
- map 从每个记录中裁切出 key,并输出 <key, record> 作为中间态数据
- reduce 原封不动将输入输出
- 这个计算还要依赖 MapReduce 库提供的排序功能
3. 实现
Google 内部的一个生产环境配置(2004 年之前):
- 2C2-4G,操作系统为 Linux
- 百兆/千兆网卡,实际带宽不大
- 集群由上千台机器组成,因此硬件故障很正常
- 使用分布式文件系统(GFS)管理磁盘上的数据
- 用户在调度系统上提交作业,每个作业由一组任务组成,由调度器分配至集群中的可用机器
由于 MapReduce 在多台机器上并行计算,所以 Map 和 Reduce 都有并行度参数可供调节。通过并行度 M 将输入数据分成 M 份并分发至多个节点上并行执行 Map;Reduce 也差不多,将中间态键值对分成 R 份,用户甚至还可以自定义分片算法(比如 hash(key) mod R)。
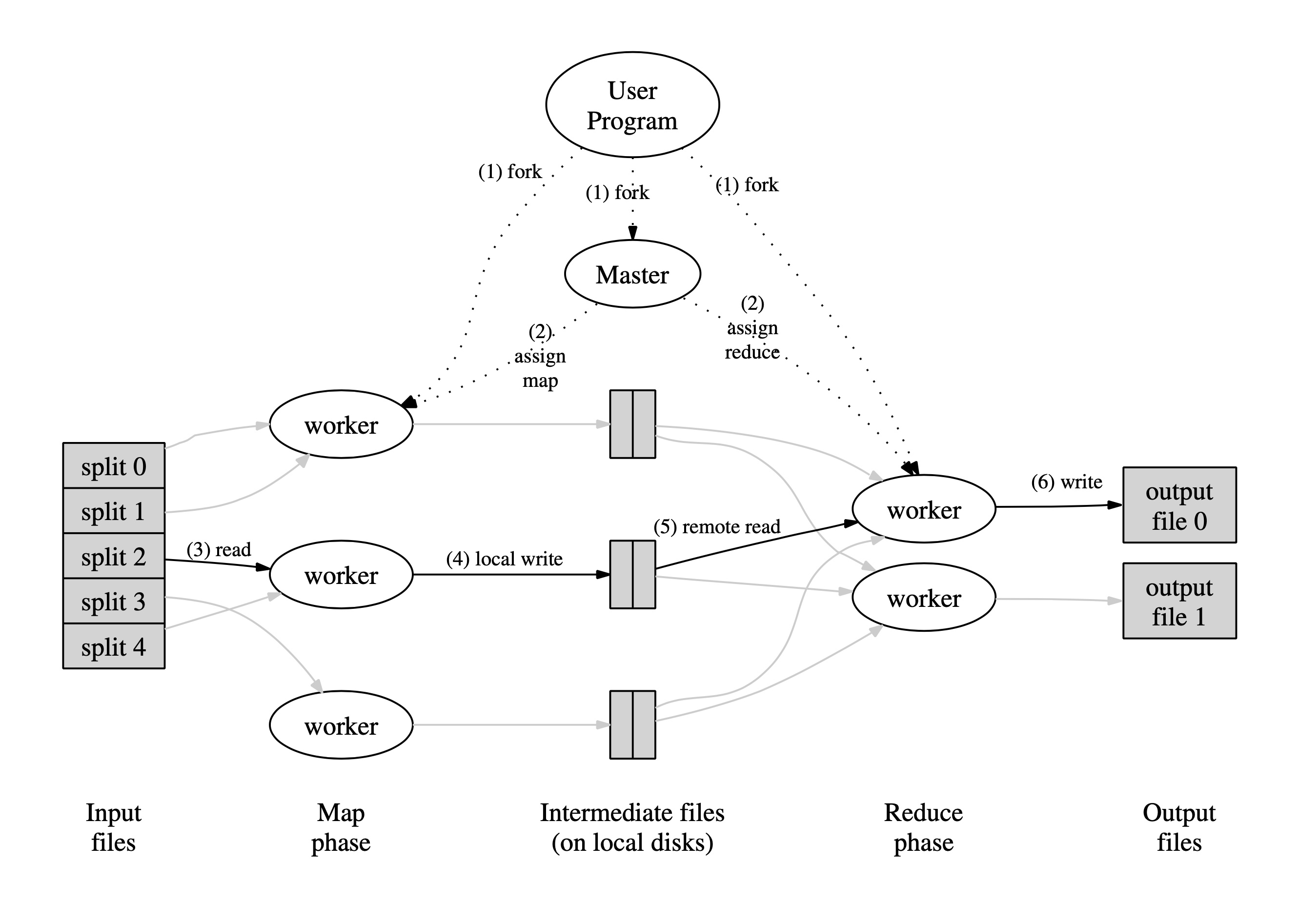
我们看一下当用户程序调用 MapReduce 时,会按下面的步骤顺序执行:
- MapReduce 库将输入文件分成 M 份,每份通常 16 - 64 MB(用户也可以通过选项来控制)。集群中的机器也会被拉起许多程序的副本。
04 年之前的机器内存并不像如今的服务器动辄数十 GB
- 副本中存在一个主进程(master),其余的 worker 进程都由 master 来分配工作。有 M 个 map 任务和 R 个 reduce 任务要分配。master 挑选空闲的 worker,给每个 worker 分配一个 map 任务或者 reduce 任务。
这里有个问题,单主是有可能会挂掉的,只要做到重要数据时刻落盘(不完全信任内存),进程挂掉后从磁盘上的数据恢复现场,那应该问题不大。
- 分配到 map 任务的 worker 进程读取属于它的那份输入,从输入数据中解析出键值对,并把每个键值对递交给用户定义的 Map 函数。Map 函数产生的中间态键值对缓存在内存中的缓冲区。
Input -> Split 在 Map 之前,都是由 MapReduce 框架来做的
- 缓冲区中的键值对由分片函数将其分片至 R 个区域,被周期性地写入磁盘,落盘的位置也要汇报给主进程,主进程负责将这些位置转发给运行 reduce 的 worker 进程。
Map 和 Reduce 过程之间还是需要通过磁盘来过渡中间态数据(因为数据量是在太大了,没有一个节点的内存可以容纳下这么多的数据),我有点好奇用如今的机器配置去计算当年的数据,他们还会不会选择中间态数据落盘,但即使在今天每个 MapReduce 计算几十 GB 的数据量对网络来说也是不小的开销。
- 当负责 reduce 的 worker 进程被主进程推送位置信息后,它会使用 RPC(remote procedure call)调用从负责 map 的 worker 进程所在节点的磁盘读取数据。但它读完中间态数据后,它会整理这些数据并将 key 相同的键值对归为一组(前文所说的 Shuffle 步骤)。如果中间态数据大到内存都放不下,还要用到外部排序。
MapReduce 的精髓所在,Map -> Shuffle -> Reduce,很多人初次接触 MapReduce 一头雾水就是因为 Map 的输出和 Reduce 的输入并不匹配,因为很少有文献着重讲它们中间的 Shuffle。Shuffle 起到了衔接二者的作用,但这是 MapReduce 框架提供的能力,并不需要用户自己来定义,而且 Google 的 MapReduce 库源码是不对外公开的,Shuffle 很容易被遗漏掉。
- 负责 reduce 的 worker 进程迭代经过“整理”的中间态数据,迭代所有唯一的 key,将 key 和与之关联的所有 value 集合递交给用户的 Reduce 函数,输出的数据被追加至这个 reduce 分片的输出文件中。
- 所有 map 和 reduce 任务都完成后,主进程唤醒用户进程,MapReduce 调用向用户代码返回结果。
上述 MapReduce 过程会输出 R 个文件,MapReduce 的通用性在于,用户并不需要自行去合并这些文件,只要把这些文件作为另一个 MapReduce 调用的输入,将 R 设置成 1,就能再次利用 MapReduce 来计算出最终结果。
3.1 master 数据结构
既然 master 进程调度整个计算过程,那就要清楚地知道 M 个 map 任务 和 R 个 reduce 任务都被调度到哪个节点去了,还有它们当前的生命周期。master 还是中间态数据磁盘落点信息的中转站。因此,master 要存储 R 个中间态数据所在区域的位置和文件大小。随着 map 任务的完成,会收到对该区域的更新信息,这些信息会被增量化的推送给正在进行 reduce 任务作业的 worker 进程。
为了缩短计算时间,并不需要等到 M 个 map 任务全部完成再启动 R 个 reduce 任务,只要有一个 map 任务完成并输出中间态文件,就可以逐渐开始 reduce 任务了。
3.2 容错
多节点、多副本会导致硬件、软件出错的概率被急剧放大,MapReduce 希望整个计算的错误处理由框架来完成而不是用户自己来写代码。容错向来是分布式系统的一个关键点。
worker 故障
master 进程定期向 worker 发送心跳包。如果应答超时,master 会将 worker 标记故障。那个 worker 已完成的 map 任务会被重置成 idle(空闲)状态,可被调度至其他 worker;同理,处于进行中状态的 map 和 reduce 也会被重置为 idle。
实际上 worker 挂掉不一定代表所在节点也宕机,worker 挂掉就重跑 map/reduce 任务会导致重复作业,增加计算时间。
Completed map tasks are re-executed on a failure because their output is stored on the local disk(s) of the failed machine and is therefore inaccessible. Completed reduce tasks do not need to be re-executed since their output is stored in a global file system.
但是 map 任务产生的中间态数据是存在 worker 进程所在节点的本地磁盘上的,worker 进程挂掉也就无法通过它来访问中间态数据了。已完成的 reduce 任务就没必要重跑了因为输出文件被存储到了外置的文件系统中。
这里也是 MapReduce 的一个关键设计:
- map 任务生成的中间态数据存储在 worker 进程所在节点的本地磁盘(坏了就坏了,大不了找个节点再算一遍,存储性能比高可用文件系统强得多)
- reduce 任务生成的最终输出文件存储在全局的外置文件系统中(一般都有三副本,对性能有影响)
一个 map 任务首先由 A worker 进程执行,后来由 B worker 进程又执行一次(因为 A 挂了),所有正在执行的 reduce 任务都会被通知到,它们将从 B worker 进程读取数据。
这样的设计使得 MapReduce 能够从容面对大规模的 worker 故障。比如在一次计算中,对集群的网络维护导致 80 个节点在数分钟内无法访问。MapReduce master 进程只需重新执行失联节点的任务,继续未完成的任务,最终完成整个 MapReduce 计算。
master 故障
在分布式系统中,进程在某个时刻的数据结构快照被称作 checkpoint。如我在上文提出的疑问,master 进程会周期性地将当前 checkpoint 落盘。master 节点挂掉,新的副本会从最近的 checkpoint 恢复现场。因为就一个 master,故障的可能性是很小的(副本越多故障的概率越大)。Google 发表论文时选择在 master 进程挂掉时直接终止整个计算,由客户端来选择是否重新执行。
将重试交给客户端而不是系统自己实现重试逻辑也是降低分布式系统复杂度的一种方法。
单 master 在早年的分布式系统中是一个很棒的设计(Google 很多分布式系统都采用了这个方案,比如 GFS)。我们假设单节点故障的概率为 1%,如果使用三副本,系统出现故障的概率会提升至 2.97%,而且在当时多副本选主、一致性也是难以解决的问题,会极大地提升系统复杂度。但是现代分布式系统已经有足够的理论基础和算法(Raft 协议)来保证一致性,这个时候三副本的优势就体现出来了,因为系统不可用(三副本全挂)的概率只有 0.0001%。
3.3 本地化
在当时的环境中网络带宽算是一种相对稀缺的资源。Google 会在 MapReduce 集群上同时部署一套 GFS 来管理节点本地磁盘上的输入数据从而节约网络带宽。GFS 将每个文件分成 64MB 的块,并将三副本存储在不同的机器上。MapReduce master 在调度 map 任务时会就近安排,尽量在有输入数据副本的节点上分配。实在不行,它甚至会尝试将 map 任务分配到副本附近(与副本所在机器连接同一个交换机)。集群中相当一部分 worker 在跑 MapReduce 操作时,只要从本地读取输入数据,不消耗网络带宽。
网络带宽并不是无穷无尽的,大型集群的网络很可能是性能瓶颈。比如在 Kubernetes 集群中,我们甚至可以优化调度器,将 Pod 调度至镜像已存在的节点上从而节省网络带宽。
3.4 任务粒度
如上所述 MapReduce 将 map 阶段拆分成 M 块,将 reduce 阶段拆分成 R 块。理想情况下,M 和 R 应该比节点数据大得多。尽量让每个 worker 执行不同类型的任务能够提升动态负载均衡。
Google 的实现对 M 和 R 是有限制的。master 调度决策的时间复杂度为 O(M + R) 并且要在内存中保存 O(M * R) 空间复杂度的状态(然而内存占用的系数很小,每个 map/reduce 任务大约一字节)。而且 R 通常由用户限定,因为 reduce 任务的输出文件是散装的。在实践中,Google 趋向于通过调整 M 将输入数据切分成 16MB 到 64MB 左右,在当时效率最高;将 R 设置为想要使用的机器数量的一个较小倍数。他们经常在 2000 台节点上 M = 200000 R = 5000 跑 MapReduce 计算。
3.4 备份
有时一个异常节点可能会拖慢整个计算。有的是因为磁盘坏了,或是在跑其他东西导致 CPU 竞争。Google 也设计了一套机制来缓解这种情况:当 MapReduce 操作接近完成时,master 会备份剩余正在进行中的任务。只要备份操作完成,任务也会被标记为已完成。备份操作带来的额外开销也不大,但是大大减少了巨型 MapReduce 计算的时间。
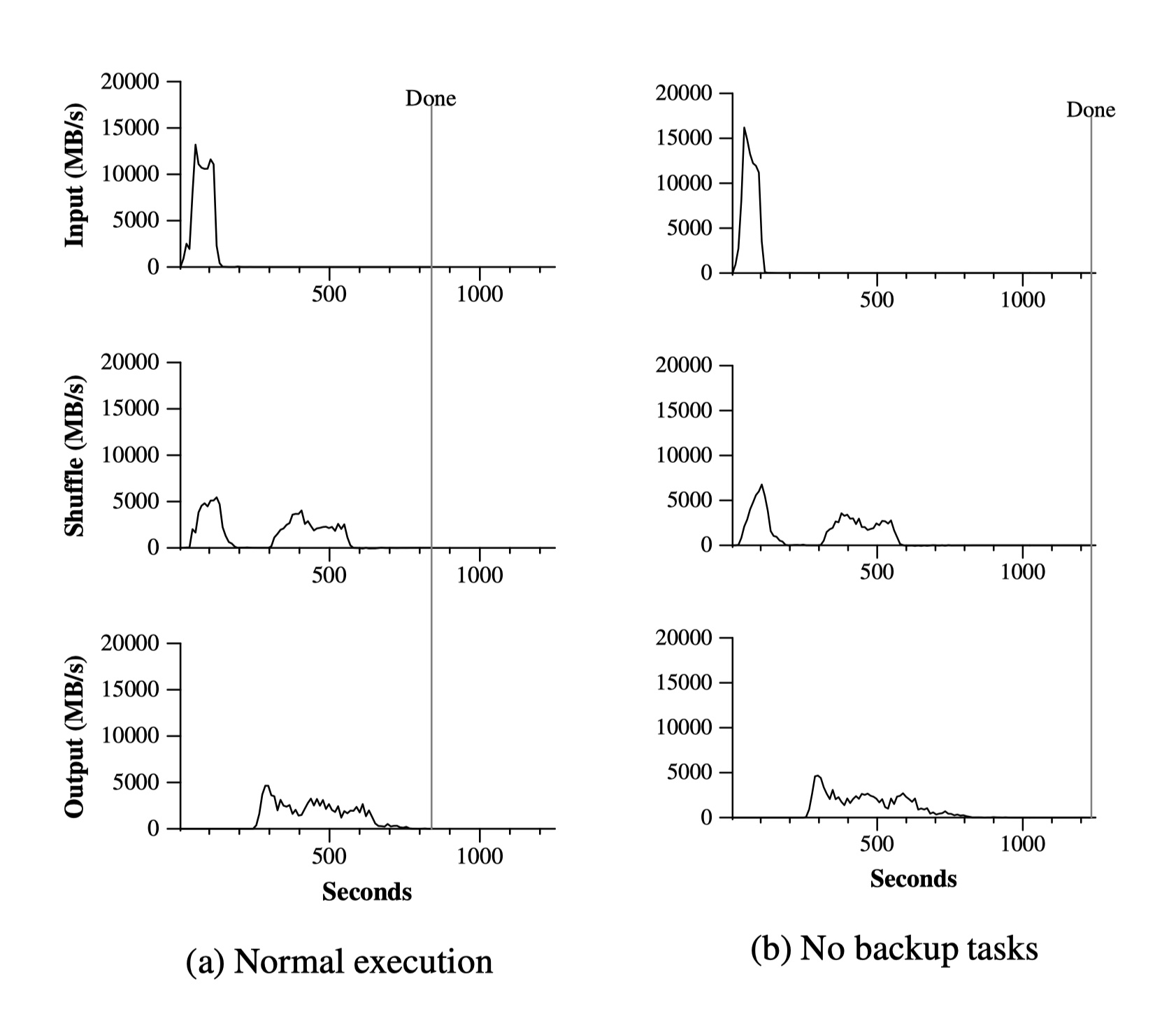
上图数据来自于排序程序,对 10^10 个 100 字节的记录排序,Map 函数从文本行中截取一个十字节的排序 key,并将原文本作为中间态键值对的值。而 Reduce 操作使用内置的 Identity 函数,该函数将中间态键值对原封不动输出。最终输出文件被写入到一组 GFS 文件中(程序输出 2TB 文件)。输入数据被切分成 64MB 的块(M = 15000),而输出分割成 4000 份(R = 4000)。
图 a 展示了正常的排序程序执行状况:
- 左上图展示了输入数据的读取速率:速度峰值能达到 13 GB/s,200s 后急速衰减是因为所有 map 任务都完成了。
- 左中图展示了数据通过网络从 map 任何发送至 reduce 任务的速率。只要有一个 map 任务完成 shuffle 就开始了。第一批 reduce 任务大概 1700 个因为整个 MapReduce 集群有 1700 个节点,每台机器同时至多执行一个 reduce 任务。300 多秒后第一批 reduce 任务中有些已经完成了,开始为剩余的 reduce 任务 shuffle。600s 后所有 shuffle 完成。
- 左下图展示了 reduce 任务将排序后的数据写入输出文件的速率。在首个 shuffle 阶段末期和写数据阶段初期中间有延迟因为机器正在忙着处理中间态数据。过一会写入速率来到 2-4 GB/s。850s 后所有写入完成。包括启动开销,整个计算过程持续 892s。
input 速度比 shuffle 和 output 速度更高是因为 Google 做了本地优化——绝大部分数据都从本地磁盘读取从而绕过了网络带宽。shuffle 比 output 快是因为将文件写入 GFS 是有副本存在的。
图 b 展示了关掉备份后的排序程序。执行过程和图 a 相仿,除了尾部拖得贼长,期间并没有什么写盘活动。960s 后,除 5 个 reduce 任务外其他都完成了,这些掉队的知道 300s 后才结束。整个计算持续了 1283 秒,比正常的多了 44%。
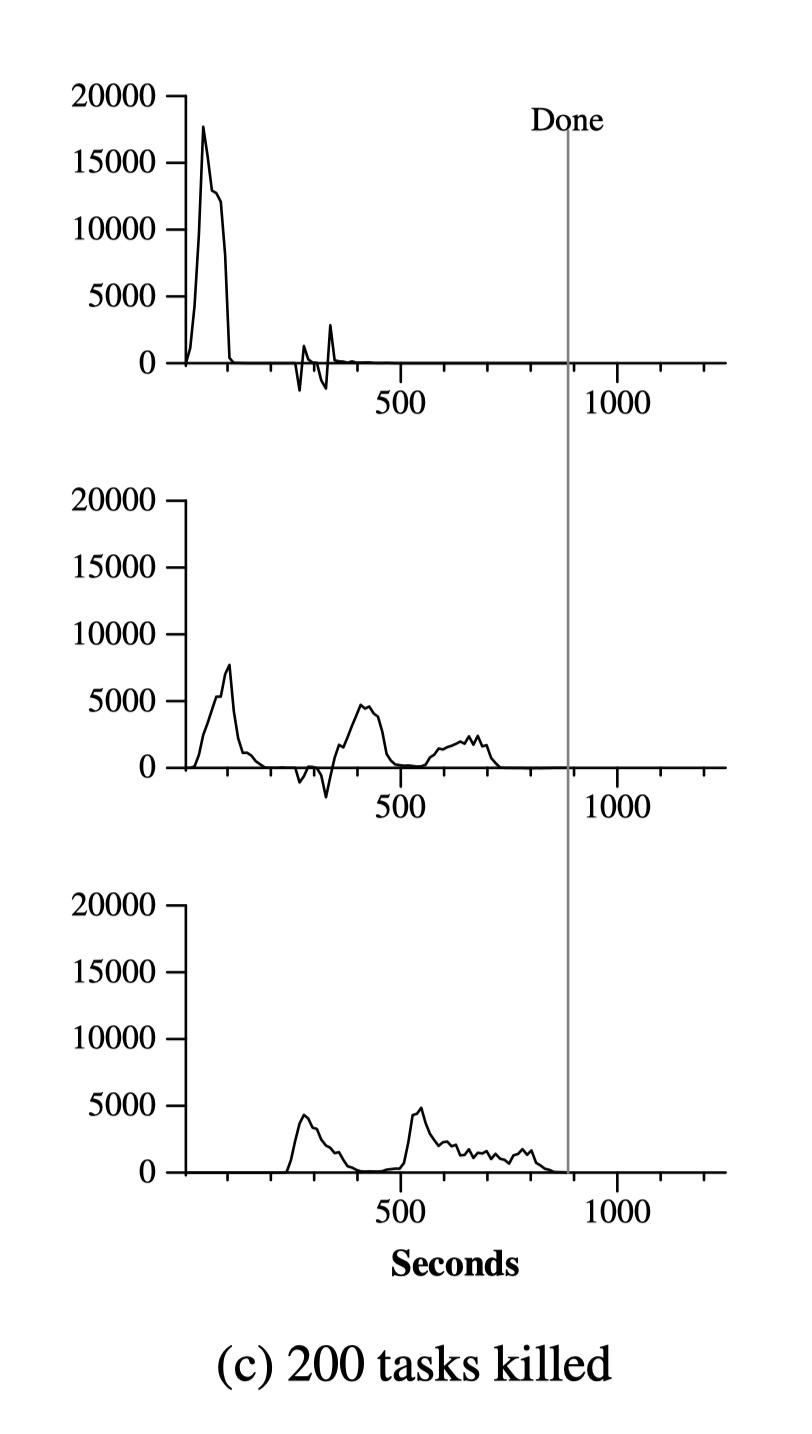
图 c 展示了故意杀掉 1746 个 worker 进程中的两百个后,底层的集群调度器会立即在这些机器上重新拉起新的 worker 进程。worker 进程之死在图中变成了负的 input 速率因为之前已经完成的 map 工作被重置了,要重新执行。整个计算在 933s 内完成,只比正常的多了 5%。
5. 经验、总结与思考
2003 年 Google 就完成了第一版 MapReduce 库,广泛应用于:
- 大规模机器学习
- 分析 Google News 产品的集群问题
- 分析近期流行的查询
- 大规模图计算
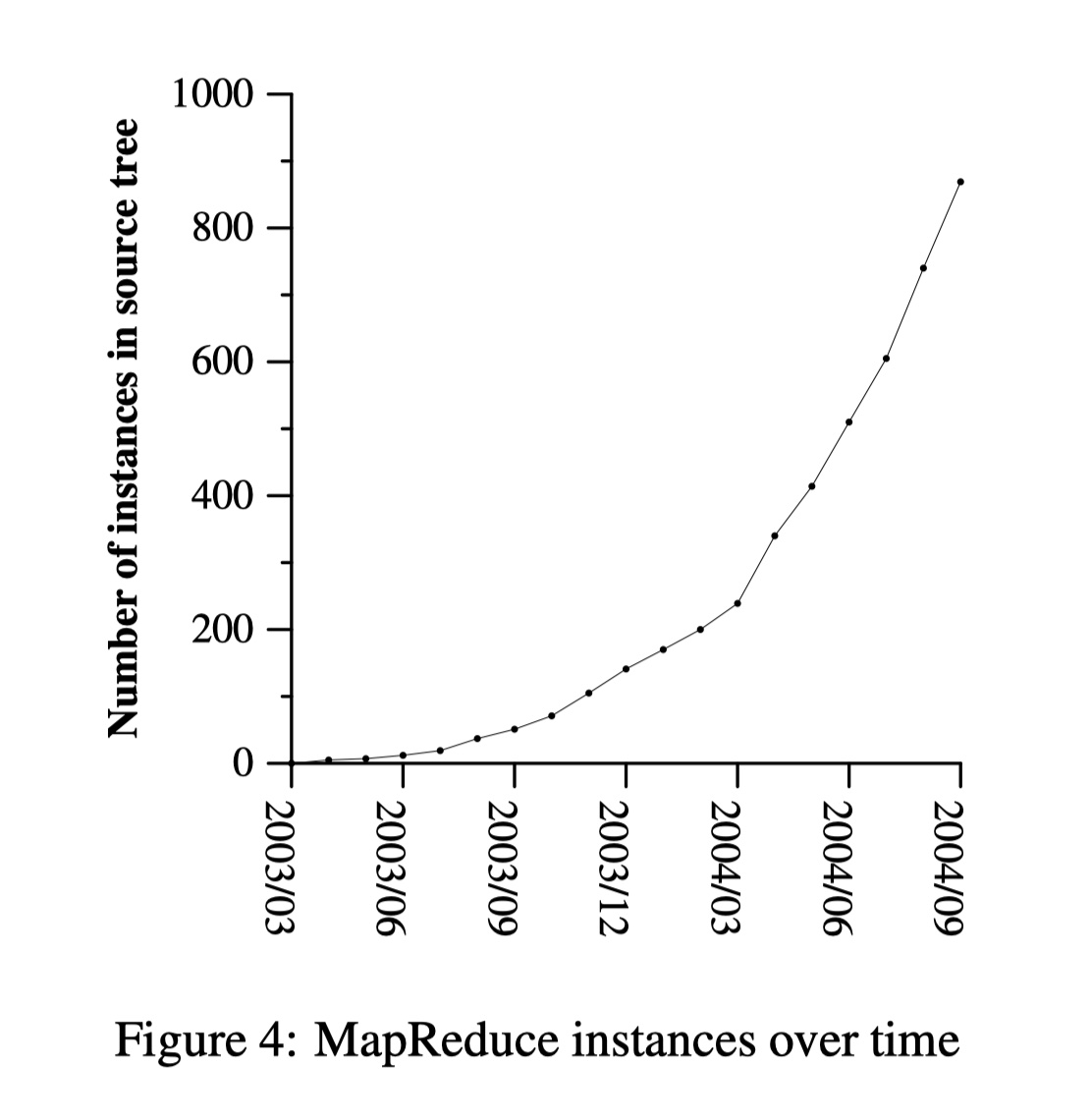
图 4 展示了从 2003 年到 2004 年 MapReduce 程序的爆炸式增长。它不仅极大地加速了开发,更重要的是,MapReduce 使得从来没有分布式开发经验的程序员也可以轻松地用上一整个集群爆炸性的算力。
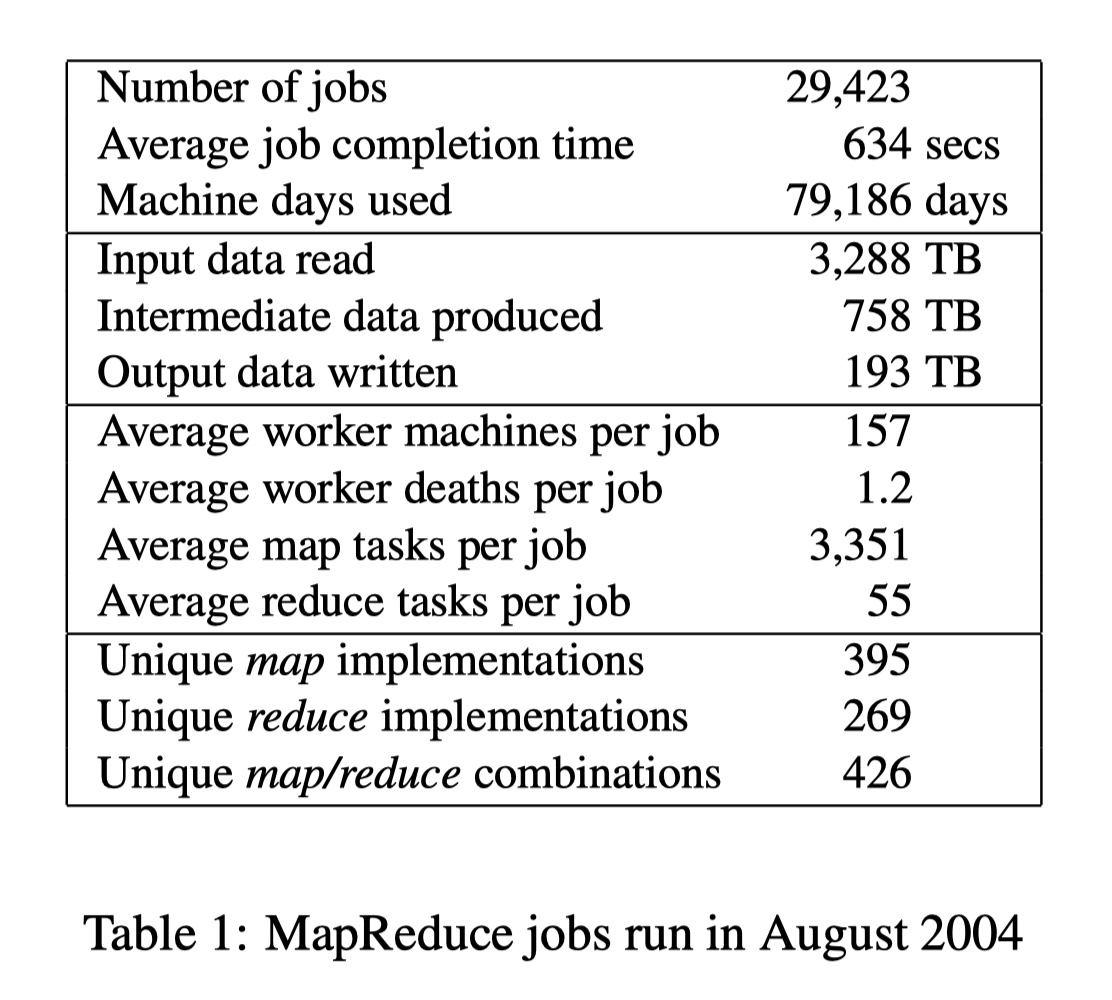
MapReduce 如此成功,归功于:
- 限制编程模型能够使得并行化的分布式计算更容易,并且赋予其容错能力
- 网络带宽也是珍贵的资源,要省着用
- 冗余在一定程度上能够削弱异常机器的影响
但是 MapReduce 也不完美,局限于当时差劲的硬件性能;master 进程也有挂掉的风险,在接近结束时 master 退出导致整个计算功亏一篑也是我们非常不想看到的。利用如今的机器硬件和分布式基础设施(Raft 协议)对其加以改造应该能够极大地强化其稳定性和成功率。
从 Google 三驾马车开始,我将做一个论文深度解析系列,下篇 Bigtable。