Linux 网络性能优化参考
Jun 19, 2020 14:00 · 2412 words · 5 minute read
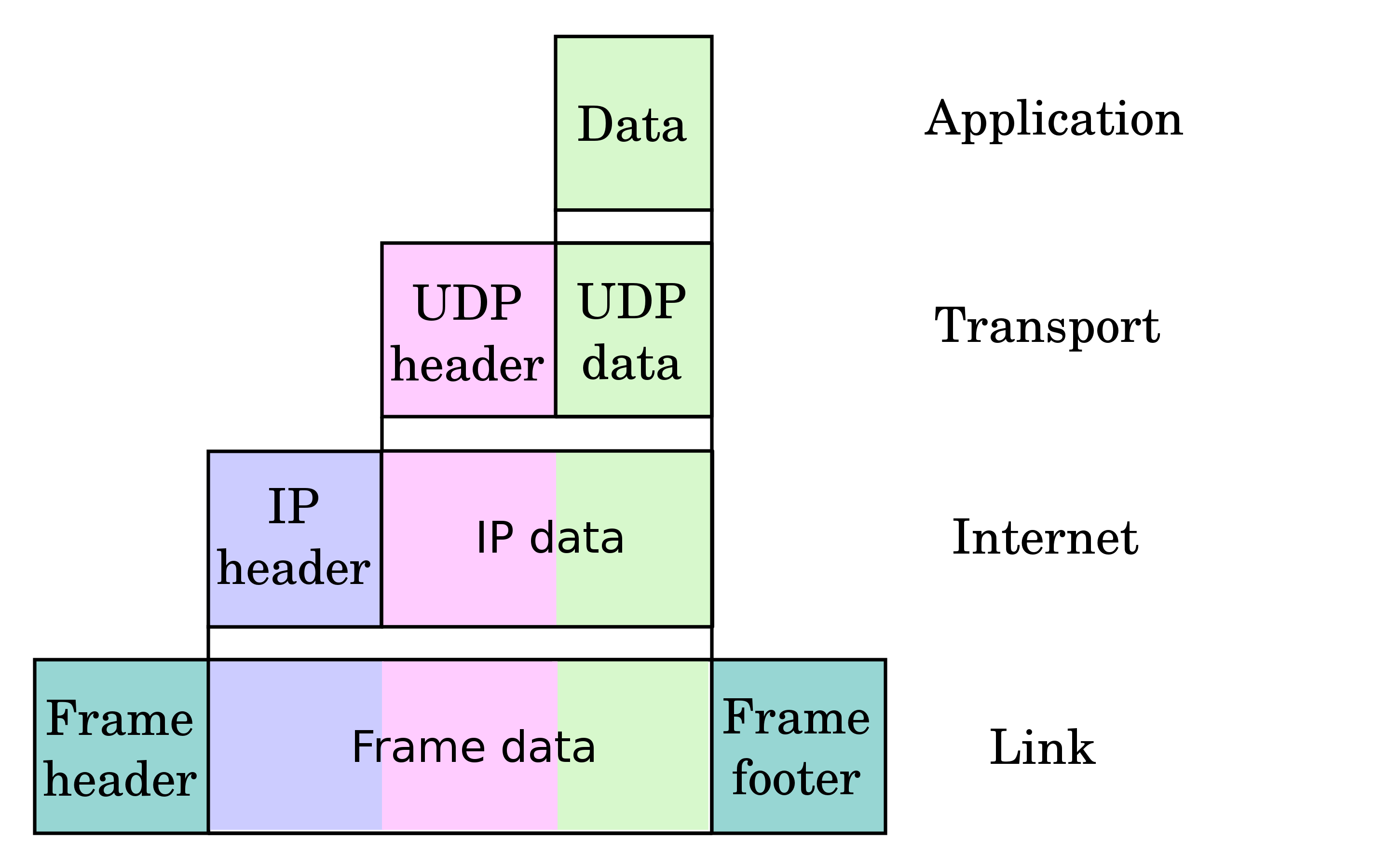
链路层
由于网卡收包后调用的中断处理程序(特别是软中断),需要消耗大量的 CPU。所以,将这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。
- 内核处理
- 为网卡硬中断配置 CPU 亲和性(smp_affinity),或者开启 irqbalance 服务。
- 开启 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),将应用程序和软中断的处理,调度到相同 CPU 上,这样就可以增加 CPU 缓存命中率,减少网络延迟。
- 网卡处理
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包。
- LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包。
- 网络接口
- 开启网络接口的多队列功能,每个队列用不同的中断号,调度到不同 CPU 上执行。
- 增大网络接口的缓冲区大小,以及队列长度。
网络层
- 路由和转发
- 调整数据包的生存周期 TTL,比如设置
net.ipv4.ip_default_ttl为 64。增大该值会降低系统性能。 - 开启数据包的反向地址校验,比如将
net.ipv4.conf.eth0.rp_filter置 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
- 调整数据包的生存周期 TTL,比如设置
- 分片
- VXLAN、GRE 等网络叠加技术会使原来的网络包变大,而以太网标准规定一个网络帧最大 1518 字节,增大交换机、路由器等的 MTU 或减小 VXLAN 封包前的 MTU。
- 支持“巨帧”的网络设备调大 MTU。
- ICMP
- 禁止 ICMP 协议,即将
net.ipv4.icmp_echo_ignore_all置 1 防止 ICMP 嗅探主机。 - 禁止广播 ICMP,即将
net.ipv4.icmp_echo_ignore_broadcasts置 1。
- 禁止 ICMP 协议,即将
传输层
TCP
- 流量比较大的场景下有大量处于 TIME_WAIT 状态的连接
- 增大处于 TIME_WAIT 状态的连接数量
net.ipv4.tcp_max_tw_buckets,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。 - 减小
net.ipv4.tcp_fin_timeout和net.netfilter.nf_conntrack_tcp_timeout_time_wait,让系统尽快释放它们所占用的资源。 - 开启端口复用
net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。 - 增大本地端口的范围
net.ipv4.ip_local_port_range。这样就可以支持更多连接,提高整体的并发能力。 - 增加最大文件描述符的数量,
fs.nr_open调大进程的最大文件描述符数,fs.file-max调大系统的最大文件描述符数。
- 增大处于 TIME_WAIT 状态的连接数量
- 缓解 SYN 洪水
- 增大 TCP 半连接的最大数量
net.ipv4.tcp_max_syn_backlog。 - 开启 TCP SYN Cookies
net.ipv4.tcp_syncookies(不能与上面同时使用)。 - 减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数
net.ipv4.tcp_synack_retries。
- 增大 TCP 半连接的最大数量
- 优化与 Keepalive 相关的内核选项,对端连接断开后,可以自动回收
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间
net.ipv4.tcp_keepalive_time。 - 缩短发送 Keepalive 探测包的间隔时间
net.ipv4.tcp_keepalive_intvl。 - 减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数
net.ipv4.tcp_keepalive_probes。
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间
UDP
- 增大套接字缓冲区大小以及 UDP 缓冲区范围
- 增大本地端口号的范围
套接字
- 调整读/写缓冲区大小
- 增大每个套接字的缓冲区大小
net.core.optmem_max。 - 增大套接字接收缓冲区大小
net.core.rmem_max和发送缓冲区大小net.core.wmem_max。 - 增大 TCP 接收缓冲区大小
net.ipv4.tcp_rmem和发送缓冲区大小net.ipv4.tcp_wmem。 - 增大 UCP 接收缓冲区大小
net.ipv4.udp_rmem和发送缓冲区大小net.ipv4.udp_wmem。
- 增大每个套接字的缓冲区大小
- TCP 行为
- 开启 TCP_NODELAY,禁用 Nagle 算法。
- 开启 TCP_CORK,让小包聚合成大包后再发送。
Nagle 算法
Nagle 算法,以发明者 Nagle 命名,是一种通过减少小包发送数量来提高 TCP 带宽利用率的算法,防止如果应用程序将数据递交至套接字的速度缓慢而节点传输大量小包。如果某个进程导致传输很多小包,可能会造成不必要的网络拥塞。当有效数据量小于 TCP 包头的数据,就是典型的小包。
这有点像用大卡车穿越整个城市来运一把椅子。除非椅子需要立即到达,不妨等整辆车塞满再运。这就是 Nagle 算法的原理。Nagle 算法用于将多个小包的数据合并至单个 TCP 帧中来优化数据传输,从而使 TCP 的数据负载增大。当有效负载只有 1 字节,TCP 头和 IP 头各占 20 字节,整个包就 41 字节,大量应用程序都能弄出这种包。
延迟确认
TCP 的 Delayed ACK(延迟确认)与 Nagle 算法有异曲同工之妙,当 TCP 接收到数据时,并不会立即发送 ACK 给对方,相反,它会等待应用层产生数据,以便将 ACK 和数据一起发送(在 Linux 最多等待 40ms)。
Nagle 算法会增加 TCP 发送数据的延迟,在某些情况下,Delayed ACK 还会放大这种延迟。
TCP_CORK
如果在某个 TCP 套接字上开启了这个选项,那就相当于在这个套接字的出口堵上了塞子,往这个套接字写入的数据都会聚集起来。当
- 程序取消设置 TCP_CORK 这个选项
- 套接字聚集的数据大于一个 MSS 的大小
- 自从堵上塞子写入第一个字节开始,已经经过 200ms
- 套接字被关闭
TCP 就会将所有数据发送出去。
应用层
- 网络 I/O 技术
- epoll(Nodejs、Golang、Netty)
- AIO(Python asyncio)
- 进程工作模型
- master + N x worker,主进程负责管理网络连接,而子进程负责实际的业务处理。
- SO_REUSEPORT 将多个进程或者线程绑定到同一端口
- 网络协议优化
- 使用长连接降低 TCP 连接建立成本(WebSocket)。
- 使用 gRPC 相比 HTTP 可以大幅减小单次网络 I/O 数据量。
- DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟。