Leader | Follower | Candidate
Sep 7, 2021 21:30 · 2454 words · 5 minute read

问题
为了实现系统容错,数据需要被复制到多台服务器。
读写 Quorum 是不够的,在有些场景中客户端会看到不一致的数据。每台独立的服务器并不知道其他服务上的数据状态,从多台服务器读取(Quorum 读)能够在一定程度上解决数据不一致的问题,但在某些案例中这种一致性还是不够强。
解决方案
从集群中挑选一台服务器作为 Leader,代表整个集群做决策并将其传达至所有服务器。
每台服务器启动时会寻找已存在的 Leader,如果找不到,就会触发选举,当服务器成功晋身为 Leader 后服务器才接受客户端的请求。整个集群只有 Leader 处理客户端请求,如果请求发送到了 Follower 服务器,Follower 会将其转发到 Leader 服务器。
选举
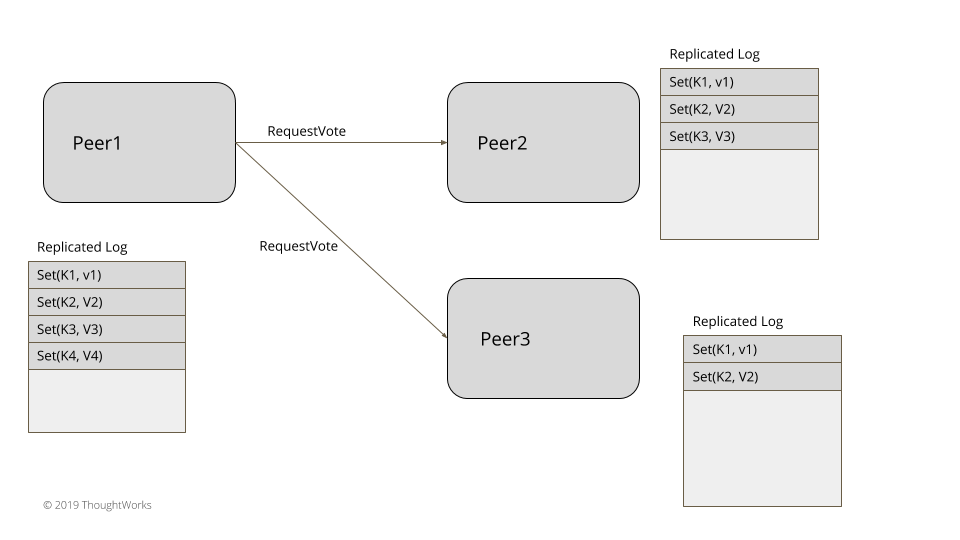
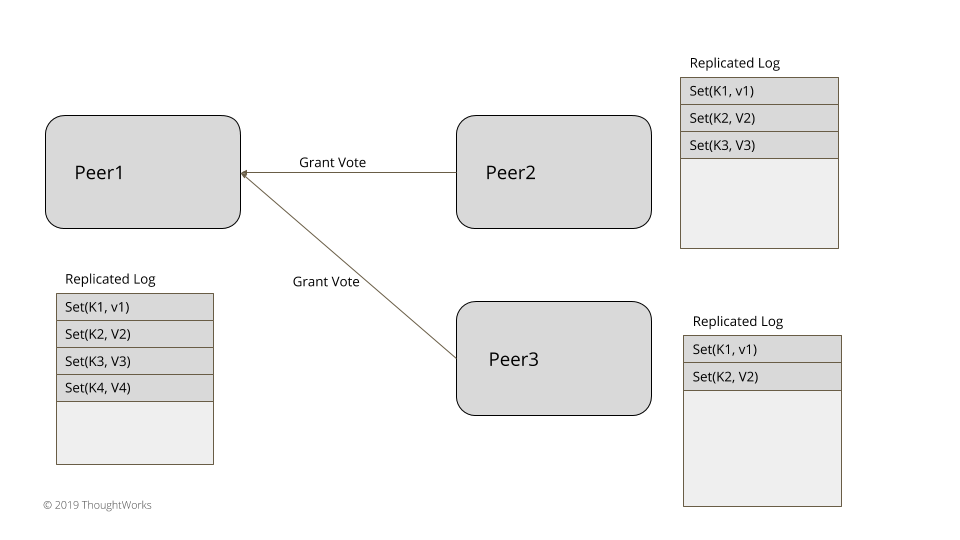
三到五个节点的小集群,比如那些通过共识算法实现一致性的系统,无需借助外部系统就可以在内部实现 Leader 选举。而在 etcd 的 Raft 算法实现中,除了 Leader 和 Follower 外,节点还有第三种状态叫做 Candidate(候选人):https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L35-L42
// Possible values for StateType.
const (
StateFollower StateType = iota
StateCandidate
StateLeader
StatePreCandidate
numStates
)
其实 etcd 还引入了全新的 PreCandidate 状态,本文不做详细讨论。
所有节点都会以 Follower 状态启动 https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L290-L357:
func newRaft(c *Config) *raft {
// a lot of code here
r := &raft{
id: c.ID,
lead: None,
isLearner: false,
raftLog: raftlog,
maxMsgSize: c.MaxSizePerMsg,
maxInflight: c.MaxInflightMsgs,
prs: make(map[uint64]*Progress),
learnerPrs: make(map[uint64]*Progress),
electionTimeout: c.ElectionTick,
heartbeatTimeout: c.HeartbeatTick,
logger: c.Logger,
checkQuorum: c.CheckQuorum,
preVote: c.PreVote,
readOnly: newReadOnly(c.ReadOnlyOption),
disableProposalForwarding: c.DisableProposalForwarding,
}
// a lot of code here
r.becomeFollower(r.Term, None)
// a lot of code here
}
https://github.com/etcd-io/etcd/blob/v3.3.24/raft/node.go#L175-L212
// StartNode returns a new Node given configuration and a list of raft peers.
// It appends a ConfChangeAddNode entry for each given peer to the initial log.
func StartNode(c *Config, peers []Peer) Node {
r := newRaft(c)
// become the follower at term 1 and apply initial configuration
// entries of term 1
r.becomeFollower(1, None)
// a lot of code here
}
Follower 通过被动心跳机制来检测 Leader 是否存活,一旦心跳超时,节点就会从 Follower 转换为 Candidate 状态,开始竞选:Cadidate 会向其他节点发送 RPC 消息请求投票(vote)给它 https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L642-L653。
func (r *raft) becomeCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> candidate]")
}
r.step = stepCandidate
r.reset(r.Term + 1)
r.tick = r.tickElection
r.Vote = r.id
r.state = StateCandidate
r.logger.Infof("%x became candidate at term %d", r.id, r.Term)
}
请求投票的 Candidate 首先会递增自己的任期编号,再给自己投上一票。 我们来看一下 etcd RAFT 算法实现的“候选人竞选”方法 https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L698-L734:
func (r *raft) campaign(t CampaignType) {
var term uint64
var voteMsg pb.MessageType
if t == campaignPreElection {
r.becomePreCandidate()
voteMsg = pb.MsgPreVote
// PreVote RPCs are sent for the next term before we've incremented r.Term.
term = r.Term + 1
} else {
r.becomeCandidate()
voteMsg = pb.MsgVote // vote msg
term = r.Term
}
if r.quorum() == r.poll(r.id, voteRespMsgType(voteMsg), true) {
// We won the election after voting for ourselves (which must mean that
// this is a single-node cluster). Advance to the next state.
if t == campaignPreElection {
r.campaign(campaignElection)
} else {
r.becomeLeader()
}
return
}
for id := range r.prs {
if id == r.id {
continue
}
r.logger.Infof("%x [logterm: %d, index: %d] sent %s request to %x at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), voteMsg, id, r.Term)
var ctx []byte
if t == campaignTransfer {
ctx = []byte(t)
}
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}
Candidate 会向所有对等节点发送 voteMsg 类型的消息请求大家投票给自己。如果 Candidate 在选举超时时间内获得了半数以上的选票(遵循 Quorum 机制),那么它就会晋身为本届任期内的 Leader https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L371:
func (r *raft) quorum() int { return len(r.prs)/2 + 1 }
当 Candidate 成为新的 Leader 后 https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L671-L696:
func (r *raft) becomeLeader() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateFollower {
panic("invalid transition [follower -> leader]")
}
r.step = stepLeader
r.reset(r.Term)
r.tick = r.tickHeartbeat
r.lead = r.id
r.state = StateLeader
// a lot of code here
}
就会给所有 Follower 广播心跳包,防止 Follower 被动心跳超时篡位发生竞选 https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L876-L1076:
func stepLeader(r *raft, m pb.Message) {
// These message types do not require any progress for m.From.
switch m.Type {
case pb.MsgBeat:
r.bcastHeartbeat()
return
// a lot of code here
}
// a lot of code here
}
// bcastHeartbeat sends RPC, without entries to all the peers.
func (r *raft) bcastHeartbeat() {
lastCtx := r.readOnly.lastPendingRequestCtx()
if len(lastCtx) == 0 {
r.bcastHeartbeatWithCtx(nil)
} else {
r.bcastHeartbeatWithCtx([]byte(lastCtx))
}
}
func (r *raft) bcastHeartbeatWithCtx(ctx []byte) {
r.forEachProgress(func(id uint64, _ *Progress) {
if id == r.id {
return
}
r.sendHeartbeat(id, ctx)
})
}
在 Leader 选举时有两点要考虑:
- 由于这些系统主要用于数据复制,有一个隐藏的条件/限制:那就是数据最新的节点才适合成为 Leader。在典型的基于一致性的系统中,最新可以定义为:
- 最新的全局时钟
- WAL 日志最新的 index
- 如果所有节点都是最新的,又有以下两种常用的标准来选举:
- 打分机制,排名最靠前的服务器获选(Zab)
- 确保每次只有一个节点竞选(Raft)
Raft 创新地提出了随机超时时间这一解决方案,每个节点的选举超时时间都是不一样的 https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L560-L583。
type raft struct {
id uint64
Term uint64
Vote uint64
// a lot of code here
// number of ticks since it reached last electionTimeout when it is leader
// or candidate.
// number of ticks since it reached last electionTimeout or received a
// valid message from current leader when it is a follower.
electionElapsed int
// number of ticks since it reached last heartbeatTimeout.
// only leader keeps heartbeatElapsed.
heartbeatElapsed int
heartbeatTimeout int
electionTimeout int
// randomizedElectionTimeout is a random number between
// [electiontimeout, 2 * electiontimeout - 1]. It gets reset
// when raft changes its state to follower or candidate.
randomizedElectionTimeout int
}
func (r *raft) reset(term uint64) {
if r.Term != term {
r.Term = term
r.Vote = None
}
r.lead = None
r.electionElapsed = 0
r.heartbeatElapsed = 0
r.resetRandomizedElectionTimeout()
// a lot of code here
}
每当 Follower 接收到 Leader 心跳包后将归零选举计时,这就大大降低了两个节点同时竞选的概率 https://github.com/etcd-io/etcd/blob/v3.3.24/raft/raft.go#L1122-L1177:
func stepFollower(r *raft, m pb.Message) {
switch m.Type {
case pb.MsgHeartbeat:
r.electionElapsed = 0
r.lead = m.From
r.handleHeartbeat(m)
// a lot of code here
}
思考
为什么 Quorum 读/写不足以保证强一致性?
看上去 Cassandra 那样类 Dynamo 的数据库利用 Quorum 读/写足以在服务器故障时提供足够的一致性。但事实并非如此,举个栗子,假设我们的集群有三个服务器节点,变量 x 被存储在所有节点上,一开始为 1。
- 第一个客户端写入 x = 2,写请求会被发送到所有节点上,假设节点 1 写入成功;节点 2 和 3 失败了。
- 客户端 c1 从节点 1 和 节点 2 读取 x 的值,它从节点 1 获取到 x 的值为 2 因为节点 1 的版本是最新的。
- 客户端 c2 也读取 x 的值,但这时节点 1 挂了,所以 c2 会从 节点 2 和 3 读取,但是它们都还是上一个版本的值 x = 1。虽然 c2 在 c1 之后读取但得到了过期的值。
一旦节点 1 重新上线,又能够读取到最新的值了。但是集群没有提供任何保证客户端读取到的值是最新的。