Golang 栈和指针的工作原理
Jul 14, 2020 22:30 · 6382 words · 13 minute read

介绍
开门见山地说,指针是难以理解的,使用不当会产生非常恶心的 bug 和性能问题,在编写并发或多线程的软件时更是如此。难怪有那么多语言试图将指针在程序员们面前藏起来。但是如果你写 Go 程序,一定会与指针狭路相逢。如果不深入理解,很难写出简洁高效的代码。
帧边界
函数在各自单独的内存空间中执行,允许函数在自己的上下文中操作。函数可以直接访问帧内的内存,但是帧外部的内存只能间接访问。要访问帧外部的内存,这块内存必须与函数共享。首先要了解和学习帧边界的机制与限制。
当一个函数被调用,在两个帧间会发生转换。代码从调动函数的空间中转换到被调用函数的空间中。数据也是一样,必须从一个空间传送到另一个空间。在 Go 中,两个帧之间的数据是“按值”传递的。
值传递的好处是可读性好,实参与形参一样,所见即所得。都是为了让你能够写出显式转换两个函数之间过渡的代码。这还有助于让你运筹帷幄,清楚地知道每个函数调用对程序的影响。
下面的代码执行函数调用,按值传递整数:
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
// Pass the "value of" the count.
increment(count)
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc int) {
// Increment the "value of" inc.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
}
当 Go 程序启动,运行时创建一个主协程执行所有初始化代码,包括 main 函数。协程是操作系统线程上的一种执行路径,最终在某个 CPU 核心上运行。Go 1.8 版每个协程初始都有 2048 字节的连续内存块构成它的栈空间。如今这个初始栈大小已经发生了变化,未来还有可能更改。
栈之所以非常重要是因为它为每个单独函数的帧提供了物理内存空间。当主协程执行 main 函数时,协程的栈是这样的:
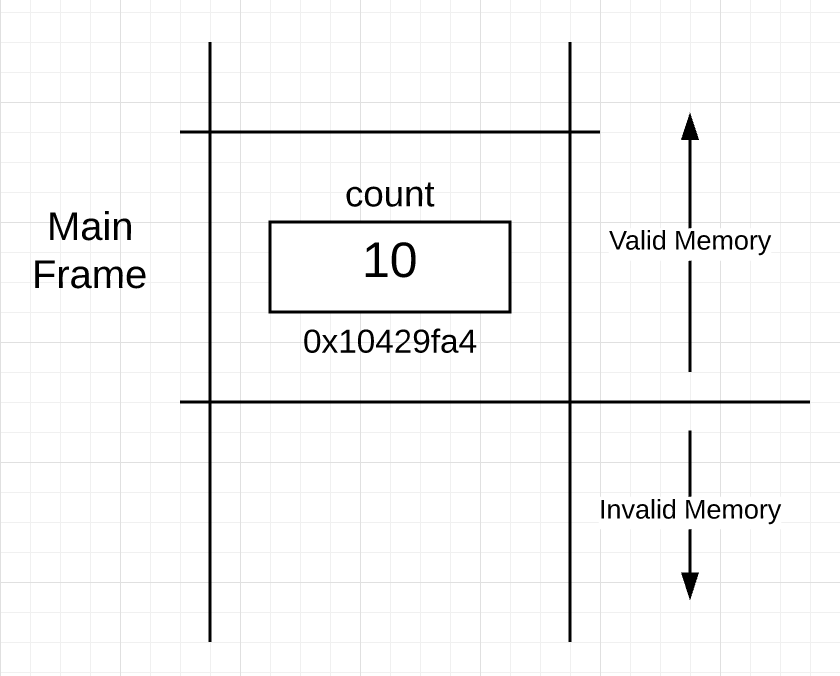
如图 1 所示,栈已经由 main 函数框出来了,这个部分叫做“栈帧”,划清了 main 函数在栈的边界。帧是作为调用函数时的某一步建立的。在 main 函数的帧中还能看到 count 变量被放在了地址为 0x10429fa4 的内存格子里。
图 1 清楚地阐述了另一个有趣的观点,所有激活的空间下面的内存是无效的,帧本身及上面的内存有效。要明确栈中有效和无效部分的边界。
地址
变量的作用是为特定的内存位置指定一个名称以提高代码的可读性,并帮助你厘清正在处理的数据。你有一个变量那么内存里就有一个值,相应的它一定有个内存地址。在第 9 行,main 函数调用内置的 println 函数来显示 count 变量的值与所在内存地址。
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
& 取地址符用于获取变量所在的内存地址很常见,其他语言大都也是用的这个。如果你在像 playground 这样的 32 位架构上运行代码,第 9 行的代码应该有着和下面类似的输出:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
函数调用
接着 12 行,main 函数调用 increment 函数。
increment(count)
函数调用意味着协程要在栈上框出一段新的内存,但实际上要更复杂一点。要想成功调用函数,数据要穿过原来的帧边界并进入新的帧。具体来说要在调用过程中复制并传递整数值。看第 18 行的 increment 函数声明:
func increment(inc int) {
再看看第 12 行的 increment 函数调用,代码正在传递 count 变量的值。这个值将被复制,传递并放置入 increment 函数的帧中。记住 increment 函数只能在自己的帧中直接读写内存,所以要 inc 变量来接收、存储和访问被传递的 count 值的副本。
在 increment 函数内的代码开始执行前,协程的栈看上去是这样的:
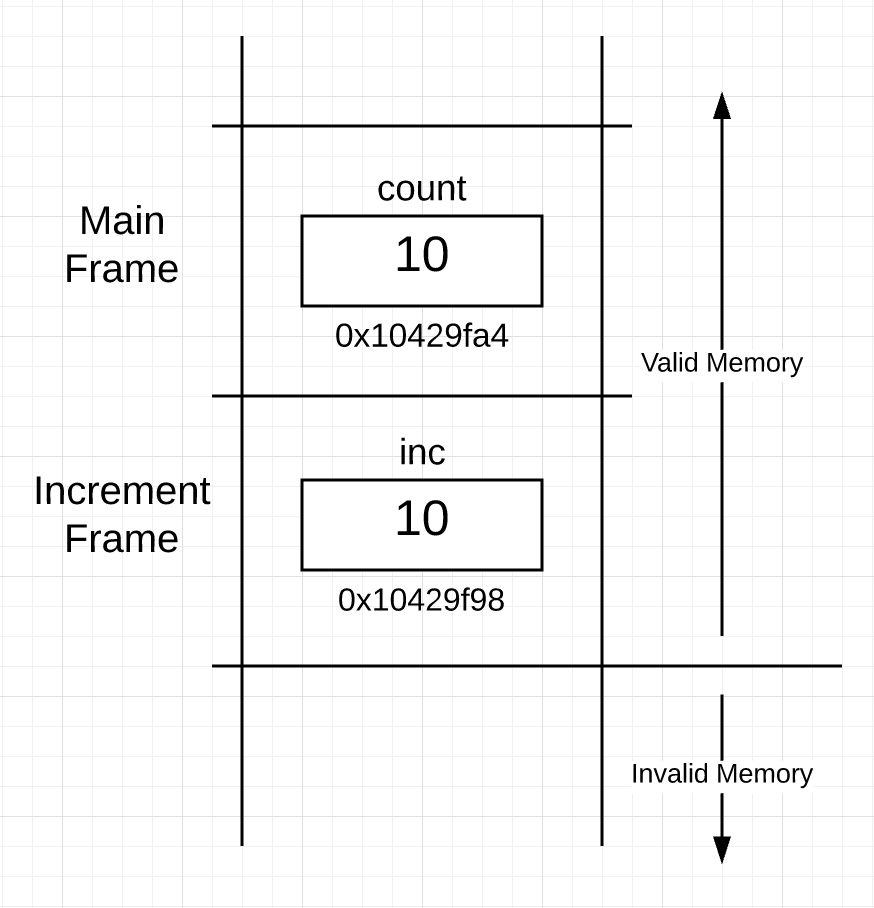
现在看到现在栈有两个帧了,一个给 main,下面的给 increment。在 increment 的帧内,能够看到 inc 变量,中间存着的在函数调用中复制并传过来的值 10。inc 变量的内存地址是 0x10429f98,协程从 main 的内存空间中获取了 count 的值,并利用 inc 变量在 increment 帧中存储此值的副本。
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
22 行的输出如下所示:
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
下面是执行代码后的栈:
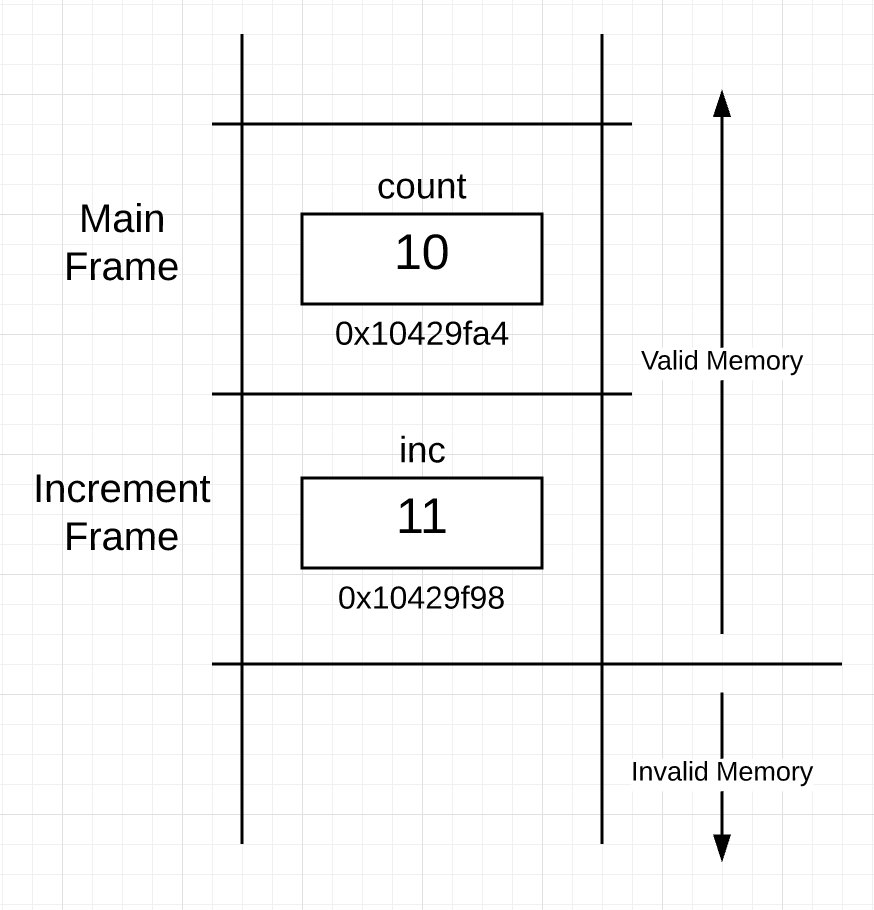
21 22 行执行后,increment 函数返回,控制权回到 main 函数手上。main 函数中 count 变量的值和所在的内存地址都和之前 14 行一样没发生改变。
println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")
程序的完整输出:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
main 所在帧中的 count 变量值在 increment 调用前后完全一致。
函数返回
当函数返回并将控制权交还给调用函数时栈上的内存又发生了什么?长话短说,啥也没变,下面就是 increment 函数返回后栈的样子:
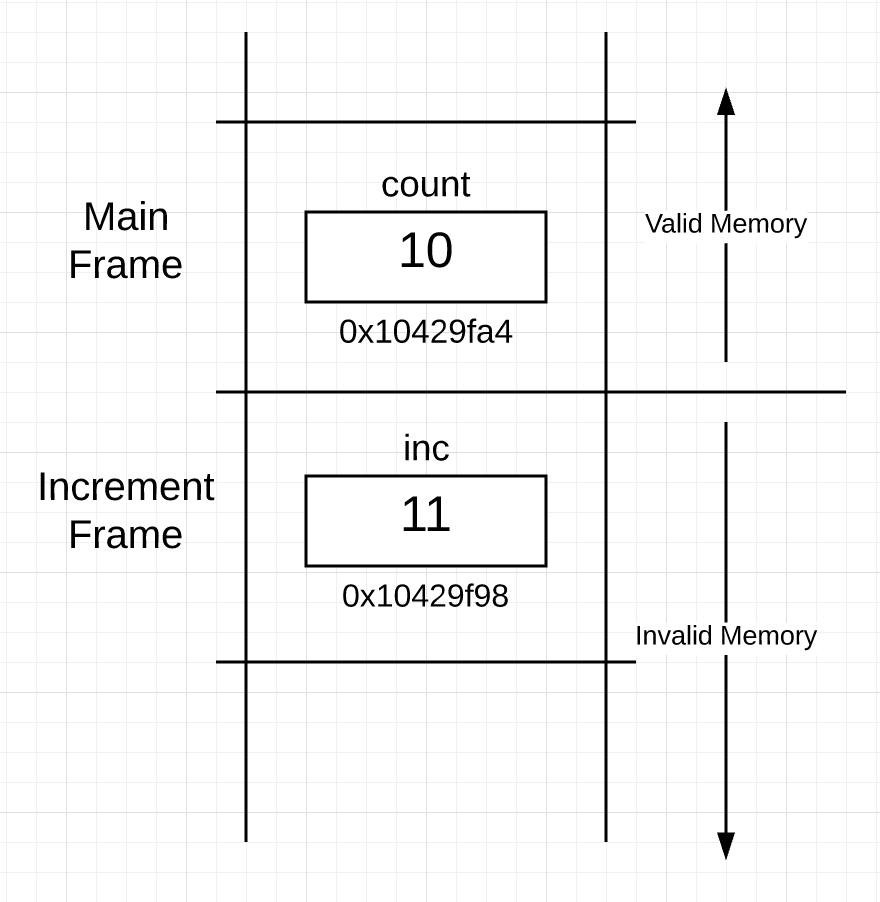
栈和图 3 看起来完全一样,除了与 increment 函数相关的帧现在已经是无效内存了,这是因为现在 main 才是激活的帧。之前 increment 函数帧用过的内存不能再碰了。
清理已返回函数的帧就是浪费时间,因为你不知道是否还要用那块内存。所以内存就保持原样咯,每次调用函数时,要利用这块内存时,才会清理干净,通过初始化要放置入帧中的值来完成。因为所有的变量起码有个“零值”,栈能够在每次函数调用时正确地清理自身。
共享值
如果 increment 函数要直接操作 main 帧内的 count 变量呢?指针来了。指针的作用只有一个,就是与函数共享值,即使它并没有直接存储在自己的帧内,函数也可以读写这个值。
如非必要,无需指针。在学习指针时,重要的是要用清晰的言语来表达而不是运算符或语法。所以记住,指针是用来分享的,在你阅读代码时,用“分享”这个词来代替 & 操作符。
指针类型
每一种可被声明的类型都有一个对应的指针类型用于共享,内置的 int 类型那就有对应的指针类型叫 *int。要是你搞出一个叫 User 的类型,反手送你一个 *User 指针类型。
所有指针类型都有两个共性,首先,开头是 *,其次它们都有相同的内存大小和表示方法,用 4 或 8 字节来表示地址。32 位架构中,指针要 4 字节内存而 64 位架构(你的电脑)要 8 字节。
间接内存访问
下面这段小程序演示了在调用函数时通过值来传递地址。increment 函数从 main 栈中的帧共享 count 变量。
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
// Pass the "address of" count.
increment(&count)
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc *int) {
// Increment the "value of" count that the "pointer points to". (dereferencing)
*inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
}
和原来的程序有三点不同,12 行:
increment(&count)
这回 12 行不再复制并传递 count 的值了取而代之的是 count 所在的内存地址。你现在可以说,我在和 increment 函数“共享” count 变量的值,说过的,& 操作符表示“共享”。
本质上还是“值传递”,不同的是你传东西是一个地址而不是一个整数。地址归根到底也是个值,这就是被复制并穿越函数调用的帧边界的东西。
既然用于表示地址的值被复制与传递,在 increment 帧内部也要一个变量来接收和存储基于整数的地址。这就是 18 行的整数指针变量声明:
func increment(inc *int) {
如果你传递的是 User 结构体实例所在的内存地址,对应的指针变量就要声明成 *User。尽管所有指针变量存储地址值,它们本身不可以被地址赋值,只能与地址关联。这是关键,之所以要共享一个值是因为接收函数要对它读写。你要知道类型信息才能对其读写。编译器确保只有与正确的指针类型相关联的值才能与函数共享。
下面是 increment 函数调用后的栈:
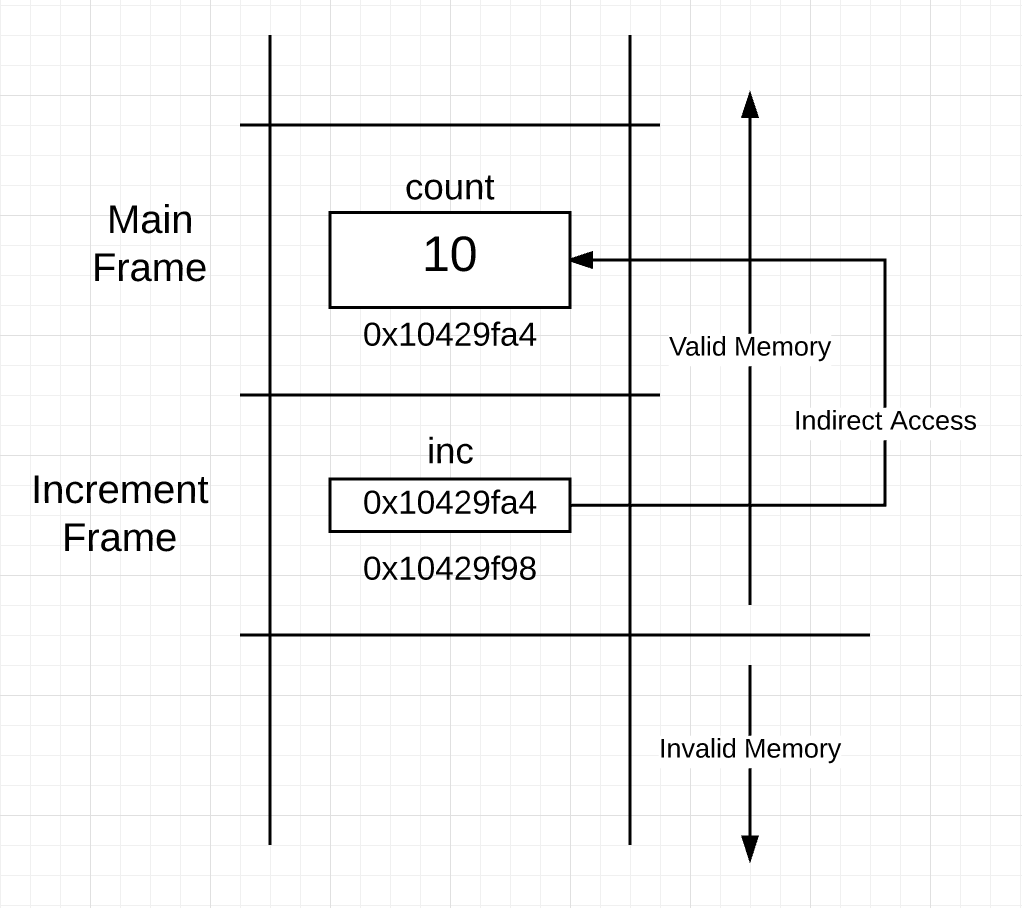
图 5 的栈中将地址作为值传递。increment 函数帧内的指针变量现在指向了 main 帧内的 count 变量所在的地址。现在利用指针变量,函数可以对 main 帧内的 count 变量进行间接读写操作。
*inc++
这回 * 字符作为适用于指针变量的操作符,意味着指针所指向的内存中的值。指针变量允许间接访问函数所在帧外的内存。increment 函数在它的帧内必须有一个可以直接读取的指针变量来执行间接访问(老工具人了)。
21 行执行后的栈:
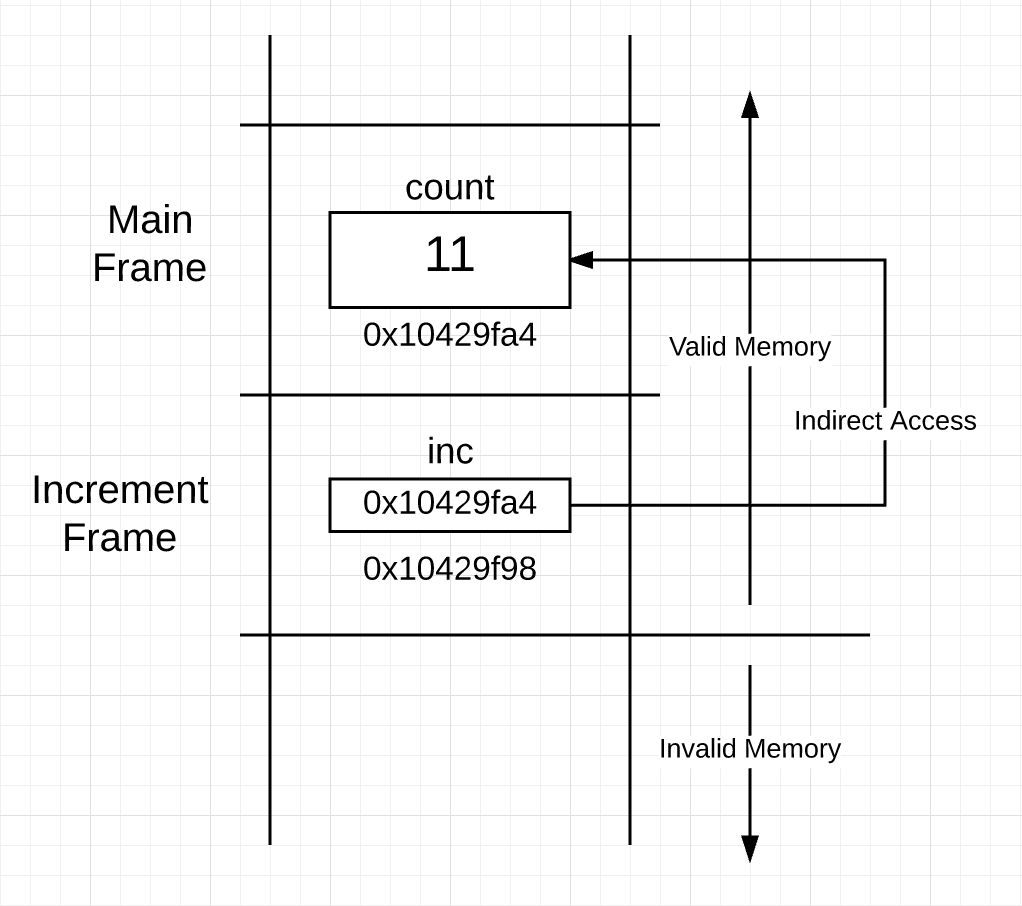
程序的最终输出:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ]
count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
你可以看到 inc 指针变量的“值”和 count 变量所在的内存地址相同,这就建立了共享关系,使帧外的间接内存访问成为可能。当 increment 函数通过指针进行写操作时,main 函数拿回控制权后就能看到更改。
指针变量不稀奇
指针变量和其他变量一样别无二致。它们被分配好内存它们存数据。所有指针变量,无论指向什么类型的值,它们本身的大小和表示方式总是一样的。倒是 * 符号在代码中充当运算符还有声明指针变量类型,可能会让人困惑。
总结
这篇博客描述了 Go 语言栈与指针的原理。这是理解设计哲学的第一步,也是编写高质量代码的指北。
- 函数所在的帧为其提供了独立的内存空间。
- 当函数被调用时,两帧之间有转换发生。
- “按值”传递数据的好处是可读性。
- 堆栈之所以重要,是因为它为每个单独函数的帧提供了物理内存空间。
- 当前激活的帧下面所有的栈内存都是无效的,反之则有效。
- 函数调用意味着协程要在栈上框出一段内存。
- 每当有函数调用,都会事先清扫帧所在的栈内存。
- 指针只有作用,就是与函数共享某个值,即使这个值不直接存在自己的帧内,也可以对其读写。
- 每一种类型都有对应的指针类型。
- 指针变量允许帧外间接访问内存。
- 指针变量和其他变量别无二致,同样分配内存并且存了一个值。
原味
Introduction
I’m not going to sugar coat it, pointers are difficult to comprehend. When used incorrectly, pointers can produce nasty bugs and even performance issues. This is especially true when writing concurrent or multi-threaded software. It’s no wonder so many languages attempt to hide pointers away from programmers. However, if you are writing software in Go, there is no way for you to avoid them. Without a strong understanding of pointers, you will struggle to write clean, simple and efficient code.
Frame Boundaries
Functions execute within the scope of frame boundaries that provide an individual memory space for each respective function. Each frame allows a function to operate within their own context and also provides flow control. A function has direct access to the memory inside its frame, through the frame pointer, but access to memory outside its frame requires indirect access. For a function to access memory outside of its frame, that memory must be shared with the function. The mechanics and restrictions established by these frame boundaries need to be understood and learned first.
When a function is called, there is a transition that takes place between two frames. The code transitions out of the calling function’s frame and into the called function’s frame. If data is required to make the function call, then that data must be transferred from one frame to the other. The passing of data between two frames is done “by value” in Go.
The benefit of passing data “by value” is readability. The value you see in the function call is what is copied and received on the other side. It’s why I relate “pass by value” with WYSIWYG, because what you see is what you get. All of this allows you to write code that does not hide the cost of the transition between the two functions. This helps to maintain a good mental model of how each function call is going to impact the program when the transition take place.
Look at this small program that performs a function call passing integer data “by value”:
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
// Pass the "value of" the count.
increment(count)
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc int) {
// Increment the "value of" inc.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
}
When your Go program starts up, the runtime creates the main goroutine to start executing all the initialization code including the code inside the main function. A goroutine is a path of execution that is placed on an operating system thread that eventually executes on some core. As of version 1.8, every goroutine is given an initial 2,048 byte block of contiguous memory which forms its stack space. This initial stack size has changed over the years and could change again in the future.
The stack is important because it provides the physical memory space for the frame boundaries that are given to each individual function. By the time the main goroutine is executing the main function in Listing 1, the goroutine’s stack (at a very high level) would look like this:
You can see in Figure 1, a section of the stack has been “framed” out for the main function. This section is called a “stack frame” and it’s this frame that denotes the main function’s boundary on the stack. The frame is established as part of the code that is executed when the function is called. You can also see the memory for the count variable has been placed at address 0x10429fa4 inside the frame for main.
There is another interesting point made clear by Figure 1. All stack memory below the active frame is invalid but memory from the active frame and above is valid. I need to be clear about the boundary between the valid and invalid parts of the stack.
Addresses
Variables serve the purpose of assigning a name to a specific memory location for better code readability and to help you reason about the data you are working with. If you have a variable then you have a value in memory, and if you have a value in memory then it must have an address. On line 09, the main function calls the built-in function println to display the “value of” and “address of” the count variable.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
The use of the ampersand & operator to get the address of a variable’s location is not novel, other languages use this operator as well. The output of line 09 should be similar to the output below if you run the code on a 32bit architecture like the playground:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
Function Calls
Next on line 12, the main function makes a call into the increment function.
increment(count)
Making a function call means the goroutine needs to frame a new section of memory on the stack. However, things are a bit more complicated. To successfully make this function call, data is expected to be passed across the frame boundary and placed into the new frame during the transition. Specifically an integer value is expected to be copied and passed during the call. You can see this requirement by looking at the declaration of the increment function on line 18.
func increment(inc int) {
If you look at the function call to increment again on line 12, you can see the code is passing the “value of” the count variable. This value will be copied, passed and placed into the new frame for the increment function. Remember the increment function can only directly read and write to memory within its own frame, so it needs the inc variable to receive, store and access its own copy of the count value being passed.
Just before the code inside the increment function starts executing, the goroutine’s stack (at a very high level) would look like this:
You can see the stack now has two frames, one for main and below that, one for increment. Inside the frame for increment, you see the inc variable and it contains the value of 10 that was copied and passed during the function call. The address of the inc variable is 0x10429f98 and is lower in memory because frames are taken down the stack, which is just an implementation detail that doesn’t mean anything. What’s important is that the goroutine took the value of count from within the frame for main and placed a copy of that value within the frame for increment using the inc variable.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
The output of line 22 on the playground should look something like this:
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
This is what the stack looks like after the execution of those same lines of code:
After lines 21 and 22 are executed, the increment function returns and control goes back to the main function. Then the main function displays the “value of” and “address of” the local count variable again on line 14.
println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")
The full output of the program on the playground should look something like this:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
The value of count in the frame for main is the same before and after the call to increment.
Function Returns
What actually happens to the memory on the stack when a function returns and control goes back up to the calling function? The short answer is nothing. This is what the stack looks like after the return of the increment function:
The stack looks exactly the same as Figure 3 except the frame associated with the increment function is now considered to be invalid memory. This is because the frame for main is now the active frame. The memory that was framed for the increment function is left untouched.
It would be a waste of time to clean up the memory of the returning function’s frame because you don’t know if that memory will ever be needed again. So the memory is left the way it is. It’s during each function call, when the frame is taken, that the stack memory for that frame is wiped clean. This is done through the initialization of any values that are placed in the frame. Because all values are initialized to at least their “zero value”, stacks clean themselves properly on every function call.
Sharing Values
What if it was important for the increment function to operate directly on the count variable that exists inside the frame for main? This is where pointers come in. Pointers serve one purpose, to share a value with a function so the function can read and write to that value even though the value does not exist directly inside its own frame.
If the word “share” doesn’t come out of your mouth, you don’t need to use a pointer. When learning about pointers, it’s important to think using a clear vocabulary and not operators or syntax. So remember, pointers are for sharing and replace the & operator for the word “sharing” as you read code.
Pointer Types
For every type that is declared, either by you or the language itself, you get for free a complement pointer type you can use for sharing. There already exists a built-in type named int so there is a complement pointer type called *int. If you declare a type named User, you get for free a pointer type called *User.
All pointer types have the same two characteristics. First, they start with the character *. Second, they all have the same memory size and representation, which is a 4 or 8 bytes that represent an address. On 32bit architectures (like the playground), pointers require 4 bytes of memory and on 64bit architectures (like your machine), they require 8 bytes of memory.
Indirect Memory Access
Look at this small program that performs a function call passing an address “by value”. This will share the count variable from the main stack frame with the increment function:
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
// Pass the "address of" count.
increment(&count)
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc *int) {
// Increment the "value of" count that the "pointer points to". (dereferencing)
*inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
}
There are three interesting changes that were made to this program from the original. Here is the first change on line 12:
increment(&count)
This time on line 12, the code is not copying and passing the “value of” count but instead the “address of” count. You can now say, I am “sharing” the count variable with the increment function. This is what the & operator says, “sharing”.
Understand this is still a “pass by value”, the only difference is the value you are passing is an address instead of an integer. Addresses are values too; this is what is being copied and passed across the frame boundary for the function call.
Since the value of an address is being copied and passed, you need a variable inside the frame of increment to receive and store this integer based address. This is where the declaration of the integer pointer variable comes in on line 18.
func increment(inc *int) {
If you were passing the address of a User value, then the variable would have needed to be declared as a *User. Even though all pointer variables store address values, they can’t be passed any address, only addresses associated with the pointer type. This is the key, the reason to share a value is because the receiving function needs to perform a read or write to that value. You need the type information of any value in order to read and write to it. The compiler will make sure that only values associated with the correct pointer type are shared with that function.
This is what the stack looks like after the function call to increment:
You can see in figure 5 what the stack looks like when a “pass by value” is performed using an address as the value. The pointer variable inside the frame for the increment function is now pointing to the count variable, which is located inside the frame for main.
Now using the pointer variable, the function can perform an indirect read modify write operation to the count variable located inside the frame for main.
*inc++
This time the * character is acting as an operator and being applied against the pointer variable. Using the * as an operator means, “the value that the pointer points to”. The pointer variable allows indirect memory access outside of the function’s frame that is using it. Sometimes this indirect read or write is called dereferencing the pointer. The increment function still must have a pointer variable within its frame it can directly read to perform the indirect access.
Now in figure 6 you see what the stack looks like after the execution of line 21.
Here is the final output of this program:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ]
count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
You can see the “value of” the inc pointer variable is the same as the “address of” the count variable. This sets up the sharing relationship that allowed the indirect access to the memory outside of the frame to take place. Once the write is performed by the increment function through the pointer, the change is seen by the main function when control is returned.
Pointer Variables Are Not Special
Pointer variables are not special because they are variables like any other variable. They have a memory allocation and they hold a value. It just so happens that all pointer variables, regardless of the type of value they can point to, are always the same size and representation. What can be confusing is the * character is acting as an operator inside the code and is used to declare the pointer type. If you can distinguish the type declaration from the pointer operation, this can help alleviate some confusion.
Conclusion
This post has described the purpose behind pointers and how stack and pointer mechanics work in Go. This is the first step in understanding the mechanics, design philosophies and guidelines needed for writing consistent and readable code.
In summary this is what you learned:
- Functions execute within the scope of frame boundaries that provide an individual memory space for each respective function.
- When a function is called, there is a transition that takes place between two frames.
- The benefit of passing data “by value” is readability.
- The stack is important because it provides the physical memory space for the frame boundaries that are given to each individual function.
- All stack memory below the active frame is invalid but memory from the active frame and above is valid.
- Making a function call means the goroutine needs to frame a new section of memory on the stack.
- It’s during each function call, when the frame is taken, that the stack memory for that frame is wiped clean.
- Pointers serve one purpose, to share a value with a function so the function can read and write to that value even though the value does not exist directly inside its own frame.
- For every type that is declared, either by you or the language itself, you get for free a compliment pointer type you can use for sharing.
- The pointer variable allows indirect memory access outside of the function’s frame that is using it.
- Pointer variables are not special because they are variables like any other variable. They have a memory allocation and they hold a value.