Golang 逃逸分析
Jul 20, 2020 21:00 · 5285 words · 11 minute read

介绍
在这个系列的第一篇中,我通过在协程的栈中共享某个值为例来说明指针的基础原理。但我并没有细说在堆栈中共享一个值时发生了什么。要理解这点,你要学习一下内存中用于存储值的另一个区域:“堆”,这样才可以进一步学习“逃逸分析”。
逃逸分析是编译器用来确定你程序所创建的值位置(栈/堆)。 具体来说编译器会做静态代码分析,决定是否可以将一个值放置在构建它的函数的栈空间中,还是该值必须“逃逸”到堆中。在 Go 中,并没有关键字和函数可以用来指导编译器,完全由你的代码习惯来决定。
堆
堆是除栈以外的第二块用于存放值的区域,不像栈那样可以自我清理,所以使用这块内存时的代价有点大。主要和垃圾收集器(GC)有关,必须要保持这块区域的整洁。当 GC 运行时,将占用 25% 的 CPU。另外它有可能造成微秒级的“时间静止”。GC 的好处是你无需担心堆内存的管理,因为以往这块很复杂而且易错。
堆中的值构成了 Go 中的内存分配。它们给 GC 带来压力,因为堆上每个不再被指针引用的值都要被移除。检查和移除的越多,GC 每次的任务就越重。所以回收算法一直在努力平衡堆的大小。
共享栈
在 Go 中,一个协程不允许有指向另一个协程的栈的指针。这是因为当栈需要伸缩时,栈内存可以转移到一块新的内存中。如果运行时需要追踪指向其他协程的栈的指针,那就太难管理了,而且在更新这些指针时,“时间静止”的延迟会吓死人。
这里有个例子因为栈的扩容要被转移数次。第 2 行和第 6 行的输出能够看出 main 函数栈中的字符串地址变化了两次。
https://play.golang.org/p/pxn5u4EBSI
// All material is licensed under the Apache License Version 2.0, January 2004
// http://www.apache.org/licenses/LICENSE-2.0
// Sample program to show how stacks grow/change.
package main
// Number of elements to grow each stack frame.
// Run with 10 and then with 1024
const size = 1024
// main is the entry point for the application.
func main() {
s := "HELLO"
stackCopy(&s, 0, [size]int{})
}
// stackCopy recursively runs increasing the size
// of the stack.
func stackCopy(s *string, c int, a [size]int) {
println(c, s, *s)
c++
if c == 10 {
return
}
stackCopy(s, c, a)
}
逃逸机制
任何时候当一个值在函数栈的帧范围外被共享时,将被分配到堆上。逃逸分析算法的工作就是发现这些情况并维持程序的完整性,确保对任何值的访问总是准确、精准和高效。
下面有个例子用来学习逃逸分析的基本原理。
package main
type user struct {
name string
email string
}
func main() {
u1 := createUserV1()
u2 := createUserV2()
println("u1", &u1, "u2", &u2)
}
//go:noinline
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
//go:noinline
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
现在使用 go:noinline 指令来防止编译器在 main 函数中直接内联这些函数函数的代码。内联会抹去函数调用,这样就把事情搞复杂了。下一篇中我会介绍内联的副作用。
在上面的代码片段中能看到两个版本的函数用于创建 user 值,它们都将值返回给调用者。函数 V1 在语义上返回值:
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
之所以我说函数在语义上返回值是因为函数创建的 user 值被复制并传递至调用栈,意味着调用函数接收值本身的副本。
第 17 - 20 行构建了一个 user 值,然后在 23 行 user 值的副本传递至调用栈并返回给调用者。在函数返回后,栈是这样的:
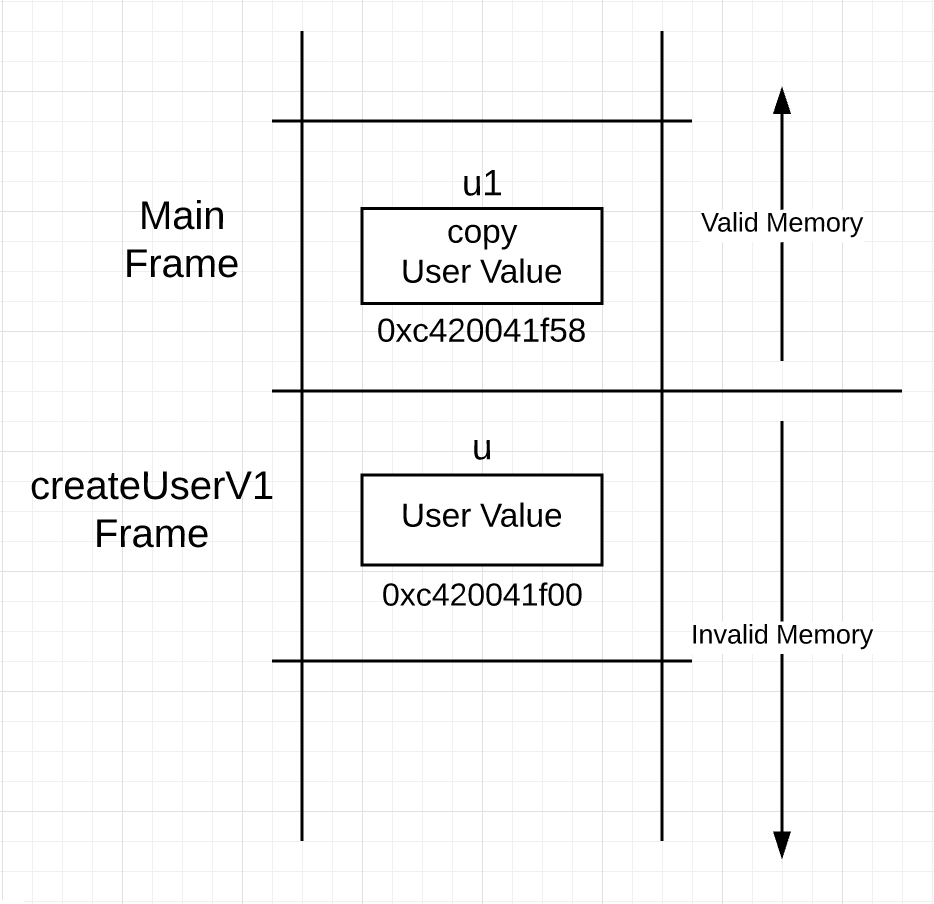
图 1 中 user 值在 createUserV1 调用后同时出现在两个帧中,V2 函数中,在语义上返回指针:
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
之所以我说函数在语义上返回指针是因为函数创建的 user 值通过调用栈分享,意味着调用函数会接收值所在地址的副本。
同上 28 - 31 行的代码构建了一个 user 值,但 34 行返回的东西不一样了。user 值所在地址的副本而不是值本身被传递至调用栈:
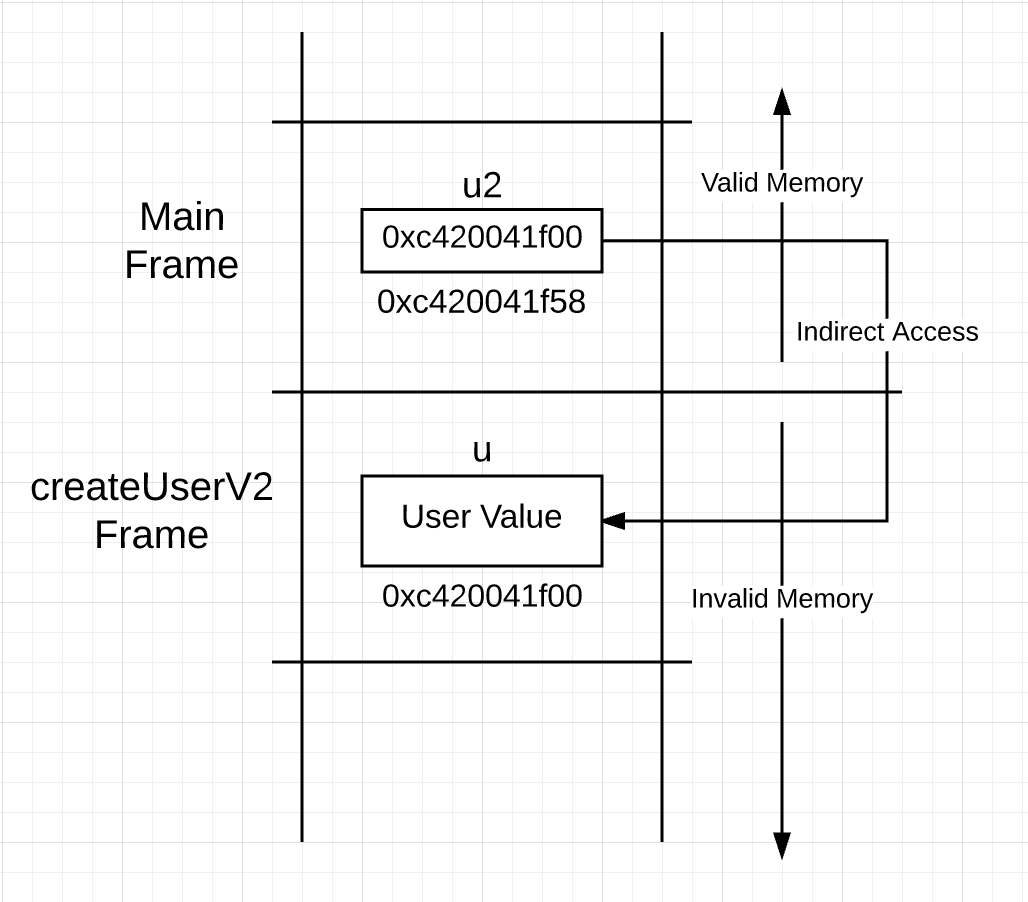
如果你在图 2 中看到的情况真的发生了,问题来了,当 main 下一次函数调用,这块内存会被重置,指针指向的内存就失效了。
逃逸分析大显神通的时候到了,在这个案例中,编译器发觉在 createUserV2 栈帧中构建 user 值是不安全,反手就它安排在堆上。这都是在 28 行实例化结构体时瞬间搞定的。
可读性
函数可以直接访问所在帧中的内存,要间接访问帧外的内存要通过帧内的指针。这就意味着访问逃逸到堆上的值也要通过指针来间接完成。
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
语法将代码背后的真相掩藏了起来。第 28 行变量 u 代表 user 类型的值。Go 中的构建并不告诉你一个值在内存中的哪个位置,直到 34 行看到 return 时你才发现这个值需要逃逸。尽管 u 代表 user 类型的值,必须通过背后的指针对其访问。
函数调用后栈的可视化:
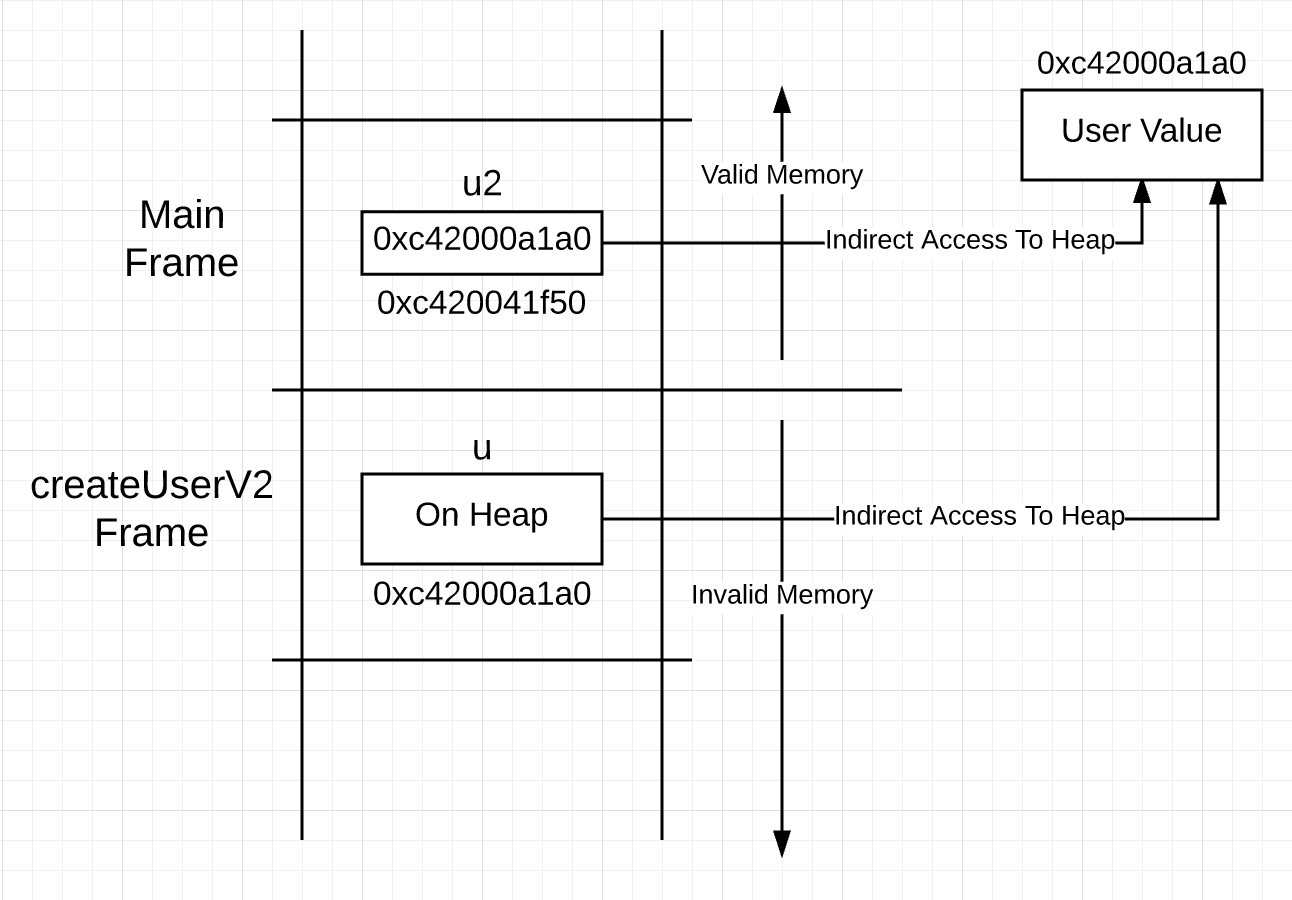
createUserV2 栈帧上的 u 变量,代表这个值在堆而不是栈上。这意味着使用 u 来访问这个值,需要通过指针访问而不是直接访问。你可能想为什么不把 u 搞成指针呢,反正访问它所代表的值都要用指针?
func createUserV2() *user {
u := &user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", u)
return u
}
如果你这么干了,代码就跟可读性不沾边了。姑且先看 return。
return u
}
这个 return 就只说了 u 的副本被传递到调用栈中,但如果你使用 & 操作符返回时呢?
return &u
}
多亏了 & 操作符,现在你知道了 u 被调用栈共享了因此逃逸到了堆。记住,指针用于共享,在你阅读代码时看到 & 操作符心中默念分享。这就是可读性的强大。
下面是另一个使用指针语法实例化值时损害可读性的例子。
var u *user
err := json.Unmarshal([]byte(r), &u)
return u, err
要使这段代码正常工作,必须在第 2 行与 json.Unmarshal 调用共享指针变量。json.Unmarshal 将创建 user 实例并将其地址分配给指针变量。https://play.golang.org/p/koI8EjpeIx
package main
import (
"encoding/json"
"fmt"
)
type user struct {
ID int
Name string
}
func main() {
u, err := retrieveUser(1234)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("%+v\n", *u)
}
func retrieveUser(id int) (*user, error) {
r, err := getUser(id)
if err != nil {
return nil, err
}
var u *user
err = json.Unmarshal([]byte(r), &u)
return u, err
}
func getUser(id int) (string, error) {
response := fmt.Sprintf(`{"id": %d, "name": "sally"}`, id)
return response, nil
}
这段代码表示:
- 创建一个
user类型的指针并将其初始化成零值 - 与
json.Unmarshal函数共享u - 将
u的副本返回给调用者
由 json.Unmarshal 函数创建的 user 值与调用者共享看上去不是很清晰。
当使用值语法来构建时,可读性又有怎样的变化呢?
var u user
err := json.Unmarshal([]byte(r), &u)
return &u, err
这段代码阐述了:
- 创建了一个
user类型的值实例并将其初始化成零值 - 与
json.Unmarshal函数共享u - 与调用者共享
u
一目了然,第 2 行将 user 值从调用栈中共享到 json.Unmarshal,第 3 行将 user 值从调用栈中共享回调用者。这把共享会导致 user 值逃逸。
在构建时使用值语法,并利用 & 操作符的可读性来明确值是如何被共享的。
编译器报告
要想知道编译器做了哪些决定,得看他的报告。你所要做的就是在 go build 时使用 -gcflags 切换至 -m 选项。
实际上 -m 有四级,但是超过两级信息量就太大了,我用两级 -m 就够了。
$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
现在能看到编译器在上报逃逸决策。编译器都说了些啥?首先看看 createUserV1 和 createUserV2 函数声明。
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
以此行开始:
./main.go:22: createUserV1 &u does not escape
createUserV1 函数内部的 println 调用并没有导致 user 值向堆逃逸,但也必须要检查一下,因为与 println 函数共享。
再看下面几行:
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
31 行分配的 user 类型的 u 变量,因为 34 行的 return 而逃逸。后两行和之前一样,33 行的 println 调用没有导致 user 值逃逸。
将 u 改为字面类型 *user,而不是之前的命名类型 user。
func createUserV2() *user {
u := &user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", u)
return u
}
再跑一把。
./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
现在 u 变量所引用的 user 值(字面类型为 user,在第 28 行赋值)因第 34 行的 return 而逃逸。
总结
值的构建并不能决定它的所在,只有值的共享方式才能确定编译器将如何安排它。每当你在调用栈中共享一个值时,它都会逃逸,还有其他原因,我将在下一篇文章中探讨。
就是在值与指针语义之间权衡得失,值语义将值保留在栈上从而减轻了 GC 的压力,但必须存储、追踪和维护任何给定的值的副本;而指针语义则将值放置在堆上,也对 GC 造成了压力,却因为只有一个值需要被存储、追踪、维护,所以效率很高。关键在于正确、一致、平衡地使用每种语义。
原文
Introduction
In the first post in this four part series, I taught the basics of pointer mechanics by using an example in which a value was shared down a goroutine’s stack. What I did not show you is what happens when you share a value up the stack. To understand this, you need to learn about another area of memory where values can live: the “heap”. With that knowledge, you can then begin to learn about “escape analysis”.
Escape analysis is the process that the compiler uses to determine the placement of values that are created by your program. Specifically, the compiler performs static code analysis to determine if a value can be placed on the stack frame for the function constructing it, or if the value must “escape” to the heap. In Go, there is no keyword or function you can use to direct the compiler in this decision. It’s only through the convention of how you write your code that dictates this decision.
Heaps
The heap is a second area of memory, in addition to the stack, used for storing values. The heap is not self cleaning like stacks, so there is a bigger cost to using this memory. Primarily, the costs are associated with the garbage collector (GC), which must get involved to keep this area clean. When the GC runs, it will use 25% of your available CPU capacity. Plus, it can potentially create microseconds of “stop the world” latency. The benefit of having the GC is that you don’t need to worry about managing heap memory, which historically has been complicated and error prone.
Values on the heap constitute memory allocations in Go. These allocations put pressure on the GC because every value on the heap that is no longer referenced by a pointer, needs to be removed. The more values that need to be checked and removed, the more work the GC must perform on every run. So, the pacing algorithm is constantly working to balance the size of the heap with the pace it runs at.
Sharing Stacks
In Go, no goroutine is allowed to have a pointer that points to memory on another goroutine’s stack. This is because the stack memory for a goroutine can be replaced with a new block of memory when the stack has to grow or shrink. If the runtime had to track pointers to other goroutine stacks, it would be too much to manage and the “stop the world” latency in updating pointers on those stacks would be overwhelming.
Here is an example of a stack that is replaced several times because of growth. Look at the output for lines 2 and 6. You will see the address of the string value inside the stack frame of main changes twice.
https://play.golang.org/p/pxn5u4EBSI
Escape Mechanics
Anytime a value is shared outside the scope of a function’s stack frame, it will be placed (or allocated) on the heap. It’s the job of the escape analysis algorithms to find these situations and maintain a level of integrity in the program. The integrity is in making sure that access to any value is always accurate, consistent and efficient.
Look at this example to learn the basic mechanics behind escape analysis.
https://play.golang.org/p/Y_VZxYteKO
package main
type user struct {
name string
email string
}
func main() {
u1 := createUserV1()
u2 := createUserV2()
println("u1", &u1, "u2", &u2)
}
//go:noinline
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
//go:noinline
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
I am using the go:noinline directive to prevent the compiler from inlining the code for these functions directly in main. Inlining would erase the function calls and complicate this example. I will introduce the side effects of inlining in the next post.
In Listing 1, you see a program with two different functions that create a user value and return the value back to the caller. Version 1 of the function is using value semantics on the return.
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
I said the function is using value semantics on the return because the user value created by this function is being copied and passed up the call stack. This means the calling function is receiving a copy of the value itself.
You can see the construction of a user value being performed on lines 17 through 20. Then on line 23, a copy of the user value is passed up the call stack and back to the caller. After the function returns, the stack looks like this.
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
I said the function is using pointer semantics on the return because the user value created by this function is being shared up the call stack. This means the calling function is receiving a copy of the address for the value.
You can see the same struct literal being used on lines 28 through 31 to construct a user value, but on line 34 the return is different. Instead of passing a copy of the user value back up the call stack, a copy of the address for the user value is passed up. Based on this, you might think that the stack looks like this after the call.
If what you see in Figure 2 was really happening, you would have an integrity issue. The pointer is pointing down the call stack into memory that is no longer valid. On the next function call by main, that memory being pointed to is going to be re-framed and re-initialized.
This is where escape analysis begins to maintain integrity. In this case, the compiler will determine it’s not safe to construct the user value inside the stack frame of createUserV2, so instead it will construct the value on the heap. This will happen immediately during construction on line 28.
Readability
As you learned in the last post, a function has direct access to the memory inside its frame, through the frame pointer, but access to memory outside its frame requires indirect access. This means access to values that escape to the heap must be done indirectly through a pointer as well.
Remember what the code looks like for createUserV2.
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
The syntax is hiding what is really happening in this code. The variable u declared on line 28 represents a value of type user. Construction in Go doesn’t tell you where a value lives in memory, so it’s not until the return statement on line 34, do you know the value will need to escape. This means, even though u represents a value of type user, access to this user value must be happening through a pointer underneath the covers.
You could visualize the stack looking like this after the function call.
The u variable on the stack frame for createUserV2, represents a value that is on the heap, not the stack. This means using u to access the value, requires pointer access and not the direct access the syntax is suggesting. You might think, why not make u a pointer then, since access to the value it represents requires the use of a pointer anyway?
func createUserV2() *user {
u := &user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", u)
return u
}
If you do this, you are walking away from an important readability gain you can have in your code. Step away from the entire function for a second and just focus on the return.
return u
}
What does this return tell you? All that it says is that a copy of u is being passed up the call stack. However, what does the return tell you when you use the & operator?
return &u
}
Thanks to the & operator, the return now tells you that u is being shared up the call stack and therefore escaping to the heap. Remember, pointers are for sharing and replace the & operator for the word “sharing” as you read code. This is very powerful in terms of readability, something you don’t want to lose.
Here is another example where constructing values using pointer semantics hurts readability.
var u *user
err := json.Unmarshal([]byte(r), &u)
return u, err
You must share the pointer variable with the json.Unmarshal call on line 02 for this code to work. The json.Unmarshal call will create the user value and assign its address to the pointer variable. https://play.golang.org/p/koI8EjpeIx
What does this code say:
- Create a pointer of type
userset to its zero value. - Share
uwith the json.Unmarshal function. - Return a copy of
uwith the caller.
It is not obviously clear that a user value, which was created by the json.Unmarshal function, is being shared with the caller.
How does readability change when using value semantics during construction?
var u user
err := json.Unmarshal([]byte(r), &u)
return &u, err
What does this code say:
- Create a value of type
userset to its zero value. - Share
uwith thejson.Unmarshalfunction. - Share
uwith the caller.
Everything is very clear. Line 02 is sharing the user value down the call stack into json.Unmarshal and line 03 is sharing the user value up the call stack back to the caller. This share will cause the user value to escape.
Use value semantics when constructing a value and leverage the readability of the & operator to make it clear how values are being shared.
Compiler Reporting
To see the decisions the compiler is making, you can ask the compiler to provide a report. All you need to do is use the -gcflags switch with the -m option on the go build call.
There are actually 4 levels of -m you can use, but beyond 2 levels the information is overwhelming. I will be using the 2 levels of -m.
$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
You can see the compiler is reporting the escape decisions. What is the compiler saying? First look at the createUserV1 and createUserV2 functions again for reference.
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
Start with this line in the report.
./main.go:22: createUserV1 &u does not escape
This is saying that the function call to println inside of the createUserV1 function is not causing the user value to escape to the heap. This must be checked because it is being shared with the println function.
Next look at these lines in the report.
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
These lines are saying, the user value associated with the u variable, which is of the named type user and assigned on line 31, is escaping because of the return on line 34. The last line is saying the same thing as before, the println call on line 33 is not causing the user value to escape.
Reading these reports can be confusing and can slightly change depending on whether the type of variable in question is based on a named or literal type.
Change u to be of the literal type *user instead of the named type user that it was before.
func createUserV2() *user {
u := &user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", u)
return u
}
Run the report again.
./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
Now the report is saying the user value referenced by the u variable, which is of the literal type *user and assigned on line 28, is escaping because of the return on line 34.
Conclusion
The construction of a value doesn’t determine where it lives. Only how a value is shared will determine what the compiler will do with that value. Anytime you share a value up the call stack, it is going to escape. There are other reasons for a value to escape which you will explore in the next post.
What these posts are trying to lead you to is guidelines for choosing value or pointer semantics for any given type. Each semantic comes with a benefit and cost. Value semantics keep values on the stack which reduces pressure on the GC. However, there are different copies of any given value that must be stored, tracked and maintained. Pointer semantics place values on the heap which can put pressure on the GC. However, they are efficient because there is only one value that needs to be stored, tracked and maintained. The key is using each semantic correctly, consistently and in balance.