Kubernetes 调度器与节点筛选
Jun 22, 2022 22:30 · 3458 words · 7 minute read

在定义 Kubernetes Pod 时,可以选择设置每个容器所需的资源。最常见的资源无非就是 CPU 和 RAM。
---
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
当声明了 Pod 中容器的资源 request,kube-scheduler 会使用该信息来决策将 Pod 调度到集群中的哪个节点上。
而如果在 Pod 定义中声明 limit,kubelet 会利用 Linux cgroup 来限制容器的最大可使用资源,本文不做详解。
Kubernetes 调度器
Kubernetes 调度器(kube-scheduler)是将 Pod 分配至 Node 的控制面进程:从调度队列中取出 Pod,根据 Pod 定义中的限制声明以及集群中的可用资源找到 Pod 落点,并将 Pod 和节点绑定。
调度器基于的调度框架是插件化的。将各组插件添加至调度器中,并与调度器一起编译。这个架构使得大多数调度行为或功能以插件的形式实现,保持调度器内核的轻量化和可维护。
请自行阅读调度器框架的设计提案
一个 Pod 调度过程可以分为两个周期:
- 调度周期(scheduling cycle)
- PreFilter
- Filter
- PostFilter
- PreScore
- Score
- PostScore
- Normalize Score
- Reserve
- Permit
- 绑定周期(binding cycle)
- WaitOnPermit
- PreBind
- Bind
- PostBind
调度周期为 Pod 选择合适的节点;绑定周期将决策应用至集群。调度周期是串行化的;而绑定周期则是并发执行的。
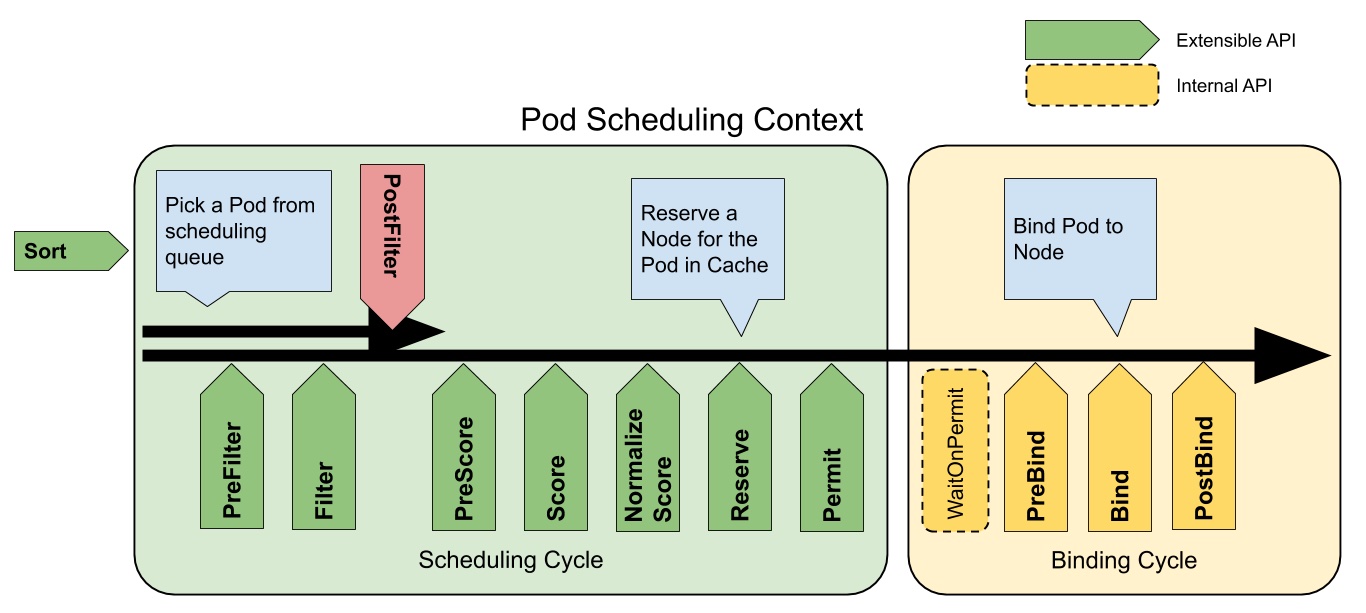
Pod 调度过程如图所示,在两个周期中都已经定义好各阶段的扩展点,随着调度的进行,各扩展点都会调用到注册过的插件。
调度器初始化
kube-scheduler 启动参数请参考 https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/。
选主:虽然 Kubernetes 集群中可能存在多个 kube-scheduler Pod,但只有一个调度器在真正地运作 https://github.com/kubernetes/kubernetes/blob/v1.23.6/cmd/kube-scheduler/app/server.go#L193-L221:
// If leader election is enabled, runCommand via LeaderElector until done and exit.
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
sched.Run(ctx)
},
OnStoppedLeading: func() {
select {
case <-ctx.Done():
// We were asked to terminate. Exit 0.
klog.InfoS("Requested to terminate, exiting")
os.Exit(0)
default:
// We lost the lock.
klog.ErrorS(nil, "Leaderelection lost")
os.Exit(1)
}
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
sched 就是调度器实例,当选的 kube-scheduler 进程将运行调度器 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/scheduler.go#L293-L298:
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
调度器的 sched.scheduleOne 方法包含了对 Pod 的整一个调度流程,将按图上所有扩展点的顺序往下执行 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/scheduler.go#L424-L638:
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
if sched.skipPodSchedule(fwk, pod) {
return
}
// a lot of code here
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, sched.Extenders, fwk, state, pod)
// a lot of code here
}
sched.Algorithm.Schedule 方法包含了 PreFilter、Filter、Score 和 Normalize Score 等步骤,本文只解析 Filter 相关。
我们再来看调度器实例的初始化 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/scheduler.go#L207-L279:
configurator := &Configurator{
componentConfigVersion: options.componentConfigVersion,
client: client,
kubeConfig: options.kubeConfig,
recorderFactory: recorderFactory,
informerFactory: informerFactory,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
percentageOfNodesToScore: options.percentageOfNodesToScore,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
profiles: append([]schedulerapi.KubeSchedulerProfile(nil), options.profiles...),
registry: registry,
nodeInfoSnapshot: snapshot,
extenders: options.extenders,
frameworkCapturer: options.frameworkCapturer,
parallellism: options.parallelism,
clusterEventMap: clusterEventMap,
}
metrics.Register()
// Create the config from component config
sched, err := configurator.create()
sched 对象是从一个 Configurator 对象实例化来的 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/factory.go#L86-L198:
func (c *Configurator) create() (*Scheduler, error) {
// a lot of code here
profiles, err := profile.NewMap(c.profiles, c.registry, c.recorderFactory,
frameworkruntime.WithComponentConfigVersion(c.componentConfigVersion),
frameworkruntime.WithClientSet(c.client),
frameworkruntime.WithKubeConfig(c.kubeConfig),
frameworkruntime.WithInformerFactory(c.informerFactory),
frameworkruntime.WithSnapshotSharedLister(c.nodeInfoSnapshot),
frameworkruntime.WithRunAllFilters(c.alwaysCheckAllPredicates),
frameworkruntime.WithPodNominator(nominator),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(c.frameworkCapturer)),
frameworkruntime.WithClusterEventMap(c.clusterEventMap),
frameworkruntime.WithParallelism(int(c.parallellism)),
frameworkruntime.WithExtenders(extenders),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
// a lot of code here
algo := NewGenericScheduler(
c.schedulerCache,
c.nodeInfoSnapshot,
c.percentageOfNodesToScore,
)
return &Scheduler{
SchedulerCache: c.schedulerCache,
Algorithm: algo,
Extenders: extenders,
Profiles: profiles,
NextPod: internalqueue.MakeNextPodFunc(podQueue),
Error: MakeDefaultErrorFunc(c.client, c.informerFactory.Core().V1().Pods().Lister(), podQueue, c.schedulerCache),
StopEverything: c.StopEverything,
SchedulingQueue: podQueue,
}, nil
}
在这里看到了 sched.Algorithm 和 sched.Profiles 是如何被初始化的:NewGenericScheduler 函数返回了一个通用调度器 genericScheduler 对象。
再来挖一下定义了调度行为的插件是如何被注册到调度框架中的。
上面的 Configurator 结构中的 registry 对象由 frameworkplugins.NewInTreeRegistry 函数实例化 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/scheduler.go#L236:
// https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/scheduler.go
registry := frameworkplugins.NewInTreeRegistry()
// https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/framework/plugins/registry.go
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnablePodAffinityNamespaceSelector: feature.DefaultFeatureGate.Enabled(features.PodAffinityNamespaceSelector),
EnablePodDisruptionBudget: feature.DefaultFeatureGate.Enabled(features.PodDisruptionBudget),
EnablePodOverhead: feature.DefaultFeatureGate.Enabled(features.PodOverhead),
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableCSIStorageCapacity: feature.DefaultFeatureGate.Enabled(features.CSIStorageCapacity),
}
return runtime.Registry{
selectorspread.Name: selectorspread.New,
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: podtopologyspread.New,
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.FitName: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: runtime.FactoryAdapter(fts, interpodaffinity.New),
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
}
}
runtime.Registry 对象是一个插件表,各插件都在此初始化和注册。
根据 request 过滤节点
Fit 插件已被注册到调度框架中,实现了两个扩展点:
- PreFilter
- Filter
PreFilter
当调度器来到 PreFilter 扩展点将调用插件的 PreFilter 方法 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/framework/plugins/noderesources/fit.go#181-L185:
func (f *Fit) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) *framework.Status {
cycleState.Write(preFilterStateKey, computePodResourceRequest(pod, f.enablePodOverhead))
return nil
}
通过 computePodResourceRequest 函数计算当前 Pod 所需要的资源 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/framework/plugins/noderesources/fit.go#135-L179:
func computePodResourceRequest(pod *v1.Pod, enablePodOverhead bool) *preFilterState {
result := &preFilterState{}
for _, container := range pod.Spec.Containers {
result.Add(container.Resources.Requests)
}
// take max_resource(sum_pod, any_init_container)
for _, container := range pod.Spec.InitContainers {
result.SetMaxResource(container.Resources.Requests)
}
// If Overhead is being utilized, add to the total requests for the pod
if pod.Spec.Overhead != nil && enablePodOverhead {
result.Add(pod.Spec.Overhead)
}
return result
}
- 累加 Pod 对象中所有容器 request 资源(CPU、内存和存储)
- 遍历 Pod 所有 init 容器,只要有 init 容器 request 资源超过上一步计算出的资源和,则使该值覆盖
- 如果 Pod 定义了
spec.overhead,就一起加上
将计算好的 Pod 所需资源写入调度器缓存中 cycleState.Write(preFilterStateKey, computePodResourceRequest(pod, f.enablePodOverhead))。
Filter
当调度器来到 Filter 扩展点将调用其 Filter 方法 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/framework/plugins/noderesources/fit.go#L218-L238:
func (f *Fit) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
s, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
insufficientResources := fitsRequest(s, nodeInfo, f.ignoredResources, f.ignoredResourceGroups)
// a lot of code here
}
真正判断某个节点的资源是否足够的是 fitsRequest 函数 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/framework/plugins/noderesources/fit.go#L256-L329:
func fitsRequest(podRequest *preFilterState, nodeInfo *framework.NodeInfo, ignoredExtendedResources, ignoredResourceGroups sets.String) []InsufficientResource {
insufficientResources := make([]InsufficientResource, 0, 4)
allowedPodNumber := nodeInfo.Allocatable.AllowedPodNumber
if len(nodeInfo.Pods)+1 > allowedPodNumber {
insufficientResources = append(insufficientResources, InsufficientResource{
v1.ResourcePods,
"Too many pods",
1,
int64(len(nodeInfo.Pods)),
int64(allowedPodNumber),
})
}
if podRequest.MilliCPU == 0 &&
podRequest.Memory == 0 &&
podRequest.EphemeralStorage == 0 &&
len(podRequest.ScalarResources) == 0 {
return insufficientResources
}
if podRequest.MilliCPU > (nodeInfo.Allocatable.MilliCPU - nodeInfo.Requested.MilliCPU) {
insufficientResources = append(insufficientResources, InsufficientResource{
v1.ResourceCPU,
"Insufficient cpu",
podRequest.MilliCPU,
nodeInfo.Requested.MilliCPU,
nodeInfo.Allocatable.MilliCPU,
})
}
if podRequest.Memory > (nodeInfo.Allocatable.Memory - nodeInfo.Requested.Memory) {
insufficientResources = append(insufficientResources, InsufficientResource{
v1.ResourceMemory,
"Insufficient memory",
podRequest.Memory,
nodeInfo.Requested.Memory,
nodeInfo.Allocatable.Memory,
})
}
if podRequest.EphemeralStorage > (nodeInfo.Allocatable.EphemeralStorage - nodeInfo.Requested.EphemeralStorage) {
insufficientResources = append(insufficientResources, InsufficientResource{
v1.ResourceEphemeralStorage,
"Insufficient ephemeral-storage",
podRequest.EphemeralStorage,
nodeInfo.Requested.EphemeralStorage,
nodeInfo.Allocatable.EphemeralStorage,
})
}
for rName, rQuant := range podRequest.ScalarResources {
if v1helper.IsExtendedResourceName(rName) {
// If this resource is one of the extended resources that should be ignored, we will skip checking it.
// rName is guaranteed to have a slash due to API validation.
var rNamePrefix string
if ignoredResourceGroups.Len() > 0 {
rNamePrefix = strings.Split(string(rName), "/")[0]
}
if ignoredExtendedResources.Has(string(rName)) || ignoredResourceGroups.Has(rNamePrefix) {
continue
}
}
if rQuant > (nodeInfo.Allocatable.ScalarResources[rName] - nodeInfo.Requested.ScalarResources[rName]) {
insufficientResources = append(insufficientResources, InsufficientResource{
rName,
fmt.Sprintf("Insufficient %v", rName),
podRequest.ScalarResources[rName],
nodeInfo.Requested.ScalarResources[rName],
nodeInfo.Allocatable.ScalarResources[rName],
})
}
}
return insufficientResources
}
- 判断是否已经达到节点允许的最大 Pod 数量
- 判断 Pod 所需资源(CPU、内存和存储)是否超过节点可分配的资源
- 判断其他扩展资源(比如 GPU),不能超过该节点上可分配的数量
通用调度器会对的一个给定的节点列表进行筛选,挑选出一个或多个合适的节点 https://github.com/kubernetes/kubernetes/blob/v1.23.6/pkg/scheduler/generic_scheduler.go#L256-L338:
func (g *genericScheduler) findNodesThatPassFilters(
ctx context.Context,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
diagnosis framework.Diagnosis,
nodes []*framework.NodeInfo) ([]*v1.Node, error) {
numNodesToFind := g.numFeasibleNodesToFind(int32(len(nodes)))
feasibleNodes := make([]*v1.Node, numNodesToFind)
if !fwk.HasFilterPlugins() {
length := len(nodes)
for i := range feasibleNodes {
feasibleNodes[i] = nodes[(g.nextStartNodeIndex+i)%length].Node()
}
g.nextStartNodeIndex = (g.nextStartNodeIndex + len(feasibleNodes)) % length
return feasibleNodes, nil
}
checkNode := func(i int) {
// We check the nodes starting from where we left off in the previous scheduling cycle,
// this is to make sure all nodes have the same chance of being examined across pods.
nodeInfo := nodes[(g.nextStartNodeIndex+i)%len(nodes)]
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.Code() == framework.Error {
errCh.SendErrorWithCancel(status.AsError(), cancel)
return
}
if status.IsSuccess() {
length := atomic.AddInt32(&feasibleNodesLen, 1)
if length > numNodesToFind {
cancel()
atomic.AddInt32(&feasibleNodesLen, -1)
} else {
feasibleNodes[length-1] = nodeInfo.Node()
}
} else {
statusesLock.Lock()
diagnosis.NodeToStatusMap[nodeInfo.Node().Name] = status
diagnosis.UnschedulablePlugins.Insert(status.FailedPlugin())
statusesLock.Unlock()
}
}
// a lot of code here
}
为了避免候选节点过多导致效率低下,调度器只会对一部分节点筛选。先通过 numFeasibleNodesToFind 方法算出将被筛选的节点数量:
const minFeasibleNodesToFind = 100
func (g *genericScheduler) numFeasibleNodesToFind(numAllNodes int32) (numNodes int32) {
if numAllNodes < minFeasibleNodesToFind || g.percentageOfNodesToScore >= 100 {
return numAllNodes
}
adaptivePercentage := g.percentageOfNodesToScore
if adaptivePercentage <= 0 {
basePercentageOfNodesToScore := int32(50)
adaptivePercentage = basePercentageOfNodesToScore - numAllNodes/125
if adaptivePercentage < minFeasibleNodesPercentageToFind {
adaptivePercentage = minFeasibleNodesPercentageToFind
}
}
numNodes = numAllNodes * adaptivePercentage / 100
if numNodes < minFeasibleNodesToFind {
return minFeasibleNodesToFind
}
return numNodes
}
如果经过筛选只有一个节点符合资源要求,那没得选就是它了,调度器会将 Pod 与该节点绑定;反之筛选后有多个节点满足条件,那就要进入打分(Score)环节,将在打分篇中详细阐述。