HTTP/3!
Jun 9, 2020 21:30 · 3094 words · 7 minute read

鸡和蛋的问题
互联网上的标准创新在历史上一直很困难,因为有一个“先有鸡还是先有蛋”的问题:需要先由服务器支持(如各大云商)还是客户端支持(如浏览器、操作系统等)?连接的两端都需要支持新的通信协议,才能使其发挥作用。
在深入探讨 HTTP/3 之前,让我们快速浏览一下 HTTP 多年来的发展,以便更好地理解为什么互联网需要 HTTP/3。
这一切始于 1996 年 HTTP/1.0 规范的发布,该规范定义了我们今天所知道的基本 HTTP 文本连线格式(出于这篇文章的目的,我权当 HTTP/0.9 不存在)。在 HTTP/1.0 中,客户端和服务器之间的每次请求/响应交换都会创建一个新的 TCP 连接,这意味着在每个请求之前 TCP 和 TLS 都要完成握手,所有请求都会产生延迟。
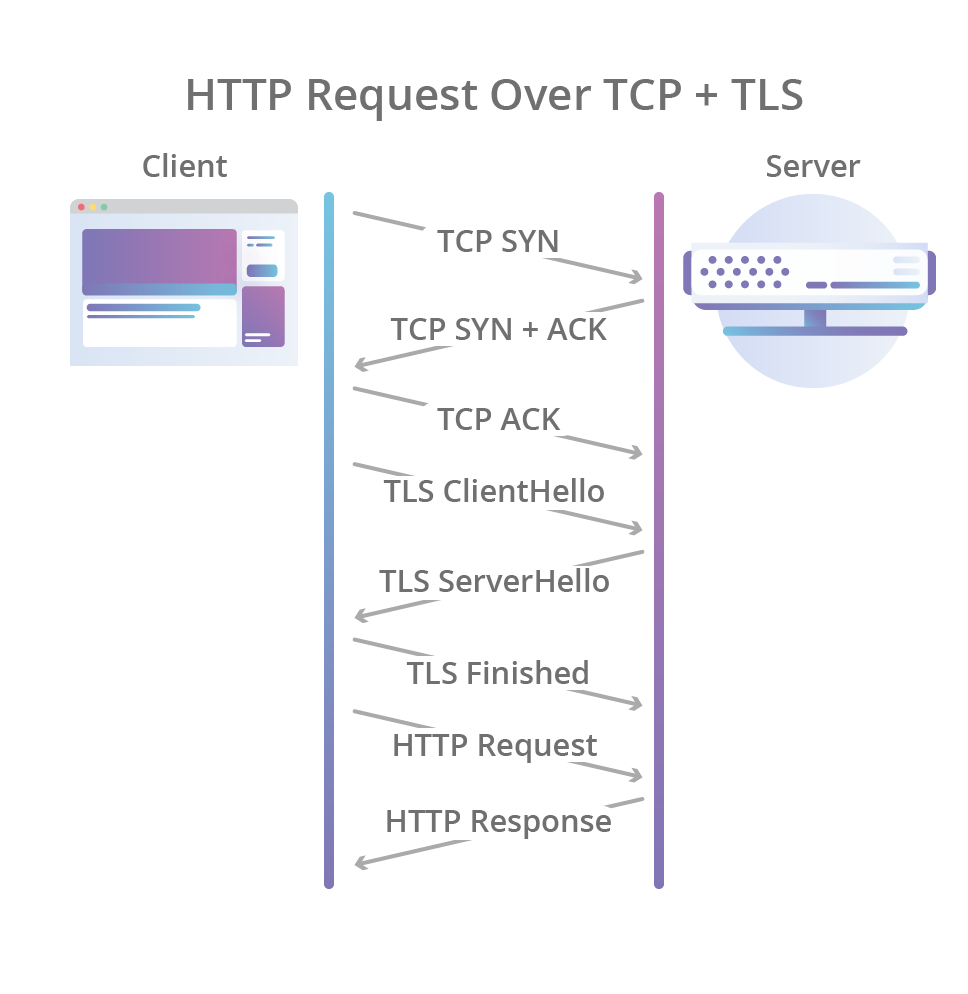
更糟糕的是,TCP 没有在建立连接后尽快发送所有未完成的数据,而是建立了名为“慢启动”的预热时间,从而使 TCP 拥塞控制算法可以在网络路径发生拥塞之前的任何给定时刻确定可传输的数据量,并避免将它无法处理的数据包泛洪到网络中。但是由于新连接必须经过缓慢的启动过程,所以它们无法立即利用上所有可用的网络带宽。
几年后,HTTP 规范的 HTTP/1.1 修订版试图通过引入“保持在线”连接的概念来解决这些问题,该概念允许客户端重用 TCP 连接,从而分摊建立初始连接的成本和跨多个请求的缓慢启动。但是,这并不是什么灵丹妙药:虽然多个请求可以共享同一个连接,但它们仍然必须一个接一个地序列化,因此客户端和服务器在任何给定时间都只能为每个连接执行一个请求/响应交换。
随着网络的发展,多年来每个网站所需资源(CSS,JavaScript,图像等)越来越多,浏览器在获取和呈现网页时对并发性的需要日趋突出。但是,由于 HTTP/1.1 只允许客户端一次进行一次 HTTP 请求/响应交换,因此在网络层上获得并发的唯一方法是并行使用多个 TCP 连接到同一源,从而丧失了保持连接的大部分好处。虽然连接在一定程度上(但程度更小)仍然可以被重用,但我们又回到了起点。
最终,在十几年后,SPDY 和 HTTP/2 出现了,它首次引入了 HTTP “流”的概念:这是一种抽象的概念,允许 HTTP 实现在同一个 TCP 连接上并发地复用不同的 HTTP 交换,允许浏览器更有效地重用 TCP 连接。
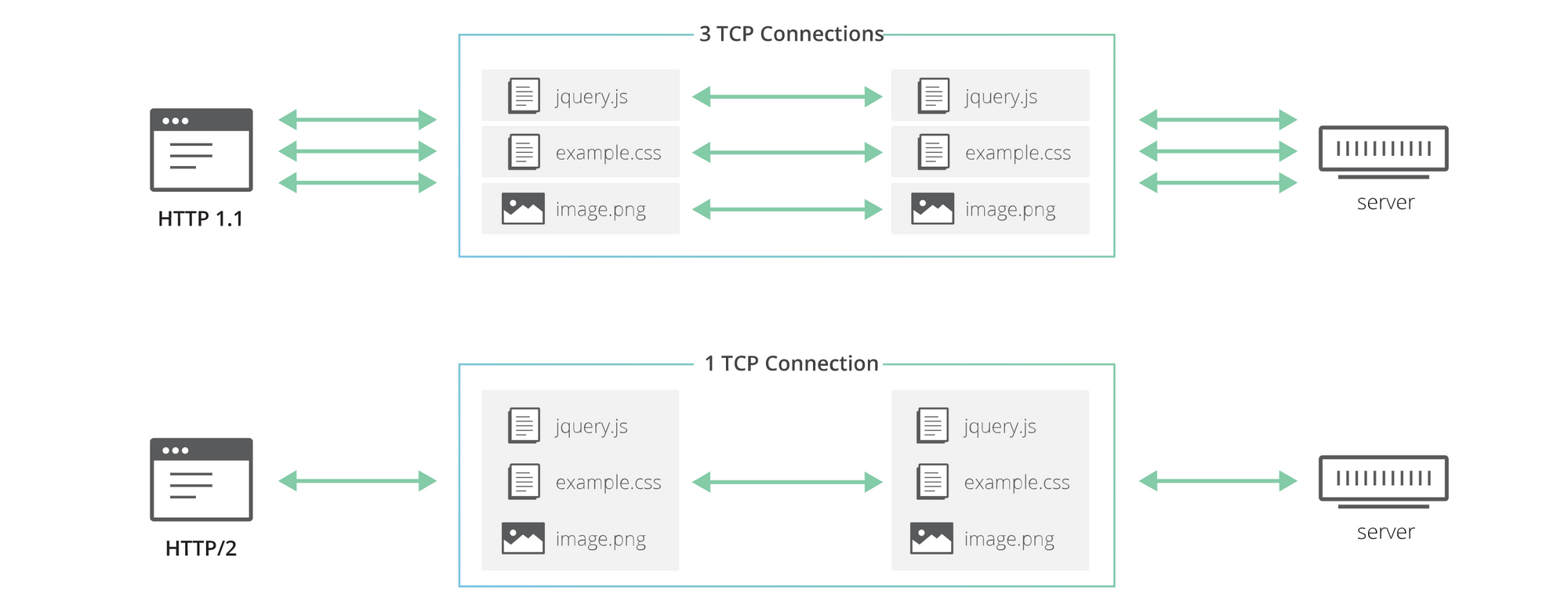
但是这并不是什么灵丹妙药,HTTP/2 只解决了最初的问题——对单个 TCP 连接的使用低效——因为现在可以在同一连接上同时传输多个请求/响应。然而,所有的请求和响应都会受到包丢失的影响(例如,由于网络拥塞),即使丢失的数据只涉及单个请求。这是因为虽然 HTTP/2 层可以在单独的流上隔离不同的 HTTP 交换,但是 TCP 不了解这种抽象,它看到的只是一个没有特定含义的字节流。
TCP 的作用是将整个字节流按正确的顺序从一个端点传递到另一个端点。当一个携带这些字节的 TCP 包在网络路径上丢失时,它会在流中产生一个缺口,当检测到丢失时,TCP 需要重新发送受影响的包来填补这个缺口。这样做时,在丢失的字节之后成功交付的字节无一可被交付给应用程序,即使它们本身没有丢失,并且属于完全独立的 HTTP 请求。因此,它们最终会带来不必要的延迟,因为 TCP 无法知道应用程序是否能够在不丢失比特的情况下处理它们。这个问题被称为“前端阻塞”。
走进 HTTP/3
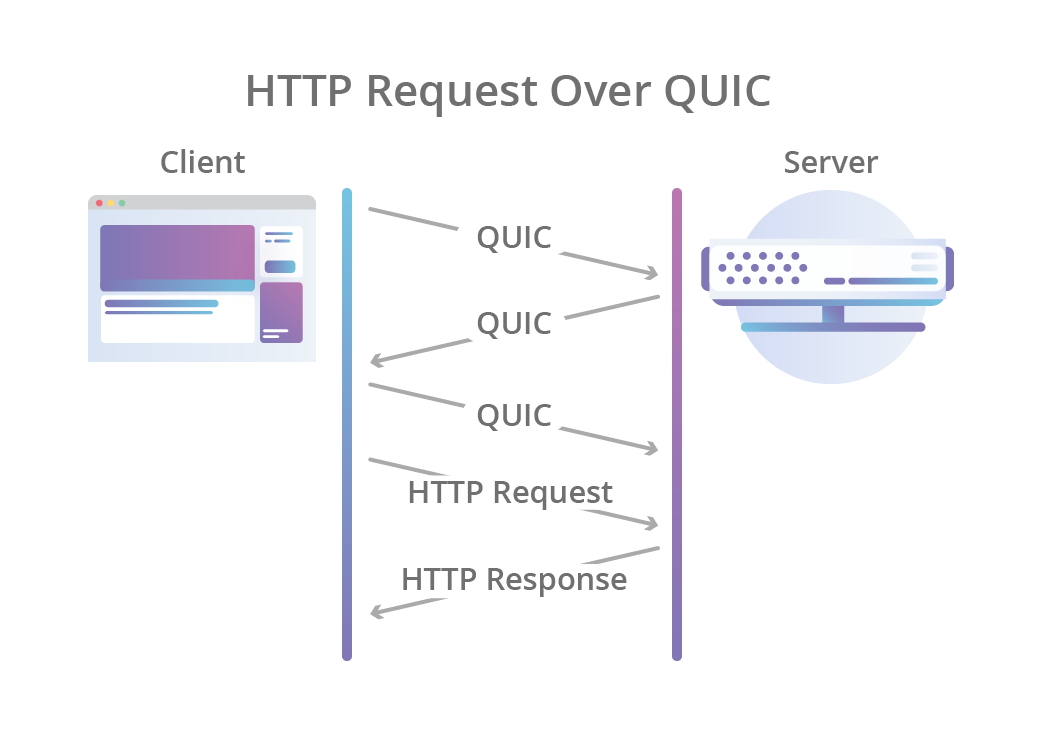
这就是 HTTP/3 的用武之处:它不使用 TCP 作为会话的传输层,而是使用 QUIC(一种新的 Internet 传输协议),该协议将流作为传输层的一级公民引入。QUIC 流共享相同的 QUIC 连接,因此不需要额外的握手和慢启动来创建新的 QUIC 流,但 QUIC 流是独立交付的,因此在大多数情况下,包丢失只影响一个流而不影响其他流。这是可能的,因为 QUIC 数据包被封装在 UDP 数据报头的顶部。
与 TCP 相比,使用 UDP 可以提供更大的灵活性,并且可以使 QUIC 完全于用户空间中实现——对协议实现的更新不像 TCP 那样需要绑定到操作系统更新。使用 QUIC,可以简单地将 HTTP 级别的流映射到 QUIC 流的顶部,从而获得 HTTP/2 的所有好处,而不会产生前端阻塞。
QUIC 还结合了典型的 3 次 TCP 握手和 TLS 1.3 的握手。结合了这些步骤意味着 QUIC 在默认情况下提供了加密和身份验证,并且可以更快地建立连接。换句话说,即使 HTTP 会话中的初始请求需要一个新的 QUIC 连接,在数据开始流动之前产生的延迟也低于使用 TLS 的 TCP 时的情况。
但是,何不直接在 QUIC 上使用 HTTP/2,而非创建一个全新的 HTTP 修订。毕竟,HTTP/2 还提供了流多路复用特性。事实证明情况要复杂得多。
虽然一些 HTTP/2 特性可以很容易地映射到 QUIC 上,但并不是所有特性都这样。特别是 HTTP/2 的请求头压缩方案 HPACK,它在很大程度上取决于将不同的 HTTP 请求和响应发送到端点的顺序。QUIC 在单个流中强制字节的传递顺序,但不保证不同流之间的顺序。
这种行为需要创建一个新的 HTTP 请求头压缩方案,称为 QPACK,它修复了这个问题,但是需要更改 HTTP 映射。此外,QUIC 本身已经提供了 HTTP/2 提供的某些功能(例如每流流控制),因此就从 HTTP/3 中删除了这些功能,以消除协议中不必要的复杂性。
HTTP/3: the past, the present, and the future
The Chicken and the Egg
Standards innovation on the Internet has historically been difficult because of a chicken and egg problem: which needs to come first, server support (like Cloudflare, or other large sources of response data) or client support (like browsers, operating systems, etc)? Both sides of a connection need to support a new communications protocol for it to be any use at all.
Before we dive deeper into HTTP/3, let’s have a quick look at the evolution of HTTP over the years in order to better understand why HTTP/3 is needed.
It all started back in 1996 with the publication of the HTTP/1.0 specification which defined the basic HTTP textual wire format as we know it today (for the purposes of this post I’m pretending HTTP/0.9 never existed). In HTTP/1.0 a new TCP connection is created for each request/response exchange between clients and servers, meaning that all requests incur a latency penalty as the TCP and TLS handshakes are completed before each request.
Worse still, rather than sending all outstanding data as fast as possible once the connection is established, TCP enforces a warm-up period called “slow start”, which allows the TCP congestion control algorithm to determine the amount of data that can be in flight at any given moment before congestion on the network path occurs, and avoid flooding the network with packets it can’t handle. But because new connections have to go through the slow start process, they can’t use all of the network bandwidth available immediately.
The HTTP/1.1 revision of the HTTP specification tried to solve these problems a few years later by introducing the concept of “keep-alive” connections, that allow clients to reuse TCP connections, and thus amortize the cost of the initial connection establishment and slow start across multiple requests. But this was no silver bullet: while multiple requests could share the same connection, they still had to be serialized one after the other, so a client and server could only execute a single request/response exchange at any given time for each connection.
As the web evolved, browsers found themselves needing more and more concurrency when fetching and rendering web pages as the number of resources (CSS, JavaScript, images, …) required by each web site increased over the years. But since HTTP/1.1 only allowed clients to do one HTTP request/response exchange at a time, the only way to gain concurrency at the network layer was to use multiple TCP connections to the same origin in parallel, thus losing most of the benefits of keep-alive connections. While connections would still be reused to a certain (but lesser) extent, we were back at square one.
Finally, more than a decade later, came SPDY and then HTTP/2, which, among other things, introduced the concept of HTTP “streams”: an abstraction that allows HTTP implementations to concurrently multiplex different HTTP exchanges onto the same TCP connection, allowing browsers to more efficiently reuse TCP connections.
But, yet again, this was no silver bullet! HTTP/2 solves the original problem — inefficient use of a single TCP connection — since multiple requests/responses can now be transmitted over the same connection at the same time. However, all requests and responses are equally affected by packet loss (e.g. due to network congestion), even if the data that is lost only concerns a single request. This is because while the HTTP/2 layer can segregate different HTTP exchanges on separate streams, TCP has no knowledge of this abstraction, and all it sees is a stream of bytes with no particular meaning.
The role of TCP is to deliver the entire stream of bytes, in the correct order, from one endpoint to the other. When a TCP packet carrying some of those bytes is lost on the network path, it creates a gap in the stream and TCP needs to fill it by resending the affected packet when the loss is detected. While doing so, none of the successfully delivered bytes that follow the lost ones can be delivered to the application, even if they were not themselves lost and belong to a completely independent HTTP request. So they end up getting unnecessarily delayed as TCP cannot know whether the application would be able to process them without the missing bits. This problem is known as “head-of-line blocking”.
Enter HTTP/3
This is where HTTP/3 comes into play: instead of using TCP as the transport layer for the session, it uses QUIC, a new Internet transport protocol, which, among other things, introduces streams as first-class citizens at the transport layer. QUIC streams share the same QUIC connection, so no additional handshakes and slow starts are required to create new ones, but QUIC streams are delivered independently such that in most cases packet loss affecting one stream doesn’t affect others. This is possible because QUIC packets are encapsulated on top of UDP datagrams.
Using UDP allows much more flexibility compared to TCP, and enables QUIC implementations to live fully in user-space — updates to the protocol’s implementations are not tied to operating systems updates as is the case with TCP. With QUIC, HTTP-level streams can be simply mapped on top of QUIC streams to get all the benefits of HTTP/2 without the head-of-line blocking.
QUIC also combines the typical 3-way TCP handshake with TLS 1.3’s handshake. Combining these steps means that encryption and authentication are provided by default, and also enables faster connection establishment. In other words, even when a new QUIC connection is required for the initial request in an HTTP session, the latency incurred before data starts flowing is lower than that of TCP with TLS.
But why not just use HTTP/2 on top of QUIC, instead of creating a whole new HTTP revision? After all, HTTP/2 also offers the stream multiplexing feature. As it turns out, it’s somewhat more complicated than that.
While it’s true that some of the HTTP/2 features can be mapped on top of QUIC very easily, that’s not true for all of them. One in particular, HTTP/2’s header compression scheme called HPACK, heavily depends on the order in which different HTTP requests and responses are delivered to the endpoints. QUIC enforces delivery order of bytes within single streams, but does not guarantee ordering among different streams.
This behavior required the creation of a new HTTP header compression scheme, called QPACK, which fixes the problem but requires changes to the HTTP mapping. In addition, some of the features offered by HTTP/2 (like per-stream flow control) are already offered by QUIC itself, so they were dropped from HTTP/3 in order to remove unnecessary complexity from the protocol.