Uber 如何支持万亿级索引
Jul 3, 2024 20:30 · 3287 words · 7 minute read

原文:https://www.uber.com/en-HK/blog/how-ledgerstore-supports-trillions-of-indexes
介绍
LedgerStore 是 Uber 的一种不可变存储解决方案,提供可验证的数据完整性和正确性保证,来确保交易数据的完整性。
考虑到账本是 Uber 所有财务事件或数据变更的真实来源,能够通过索引从各种访问模式查询账本非常重要。这带来了数万亿个索引来查找数千亿账本的需求。本文介绍了 LedgerStore 索引的架构,支持数万亿级的索引,具有 PB 级别的索引存储规模。
索引的类别
账本需要支持各种类型的索引。
强一致性索引
一个案例是处理乘客/用餐者使用 Uber 时的信用卡授权流程。在 Uber 行程开始时,乘客/用餐者的信用卡会被锁住。该锁定会根据行程是否已进行或取消,转换为收费或作废,如下图。
如果索引不是强一致性的,那么在读取时仍可以看到锁定的金额,后果是用户信用卡可能会被重复扣钱。
现在我们深入探讨如何构建强一致性索引,确保一旦写入完成,接下来任意读取都能看到与该记录对应的索引。
写路径
我们使用二阶段提交构建强一致性索引。插入操作先写入索引 intent 再写记录。当写记录成功,这些索引 intent 就提交,而且都是异步完成的,降低用户端的延迟。如果索引 intent 写入成功但记录写入失败,索引 intent 要被回滚,否则会导致无用的 intent 堆积,那会在读取时被处理。如果索引 intent 写入失败,整个插入操作都会失败,因为无法保证索引与记录的一致性。因此只有在不得不用时才考虑用强一致性索引。
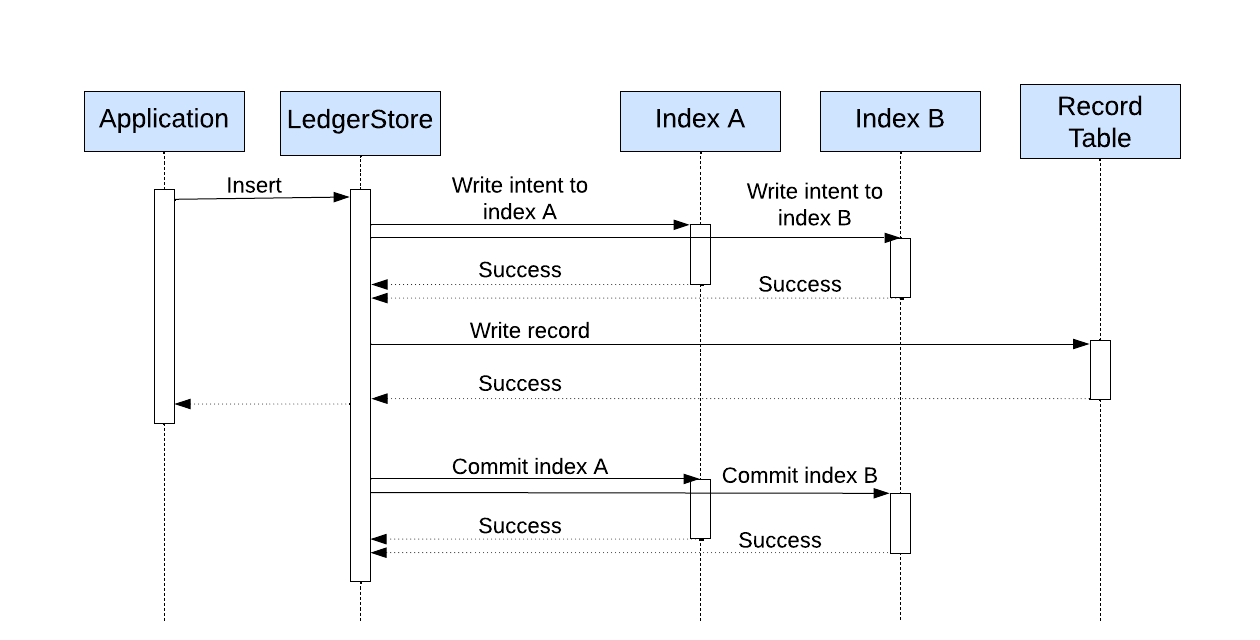
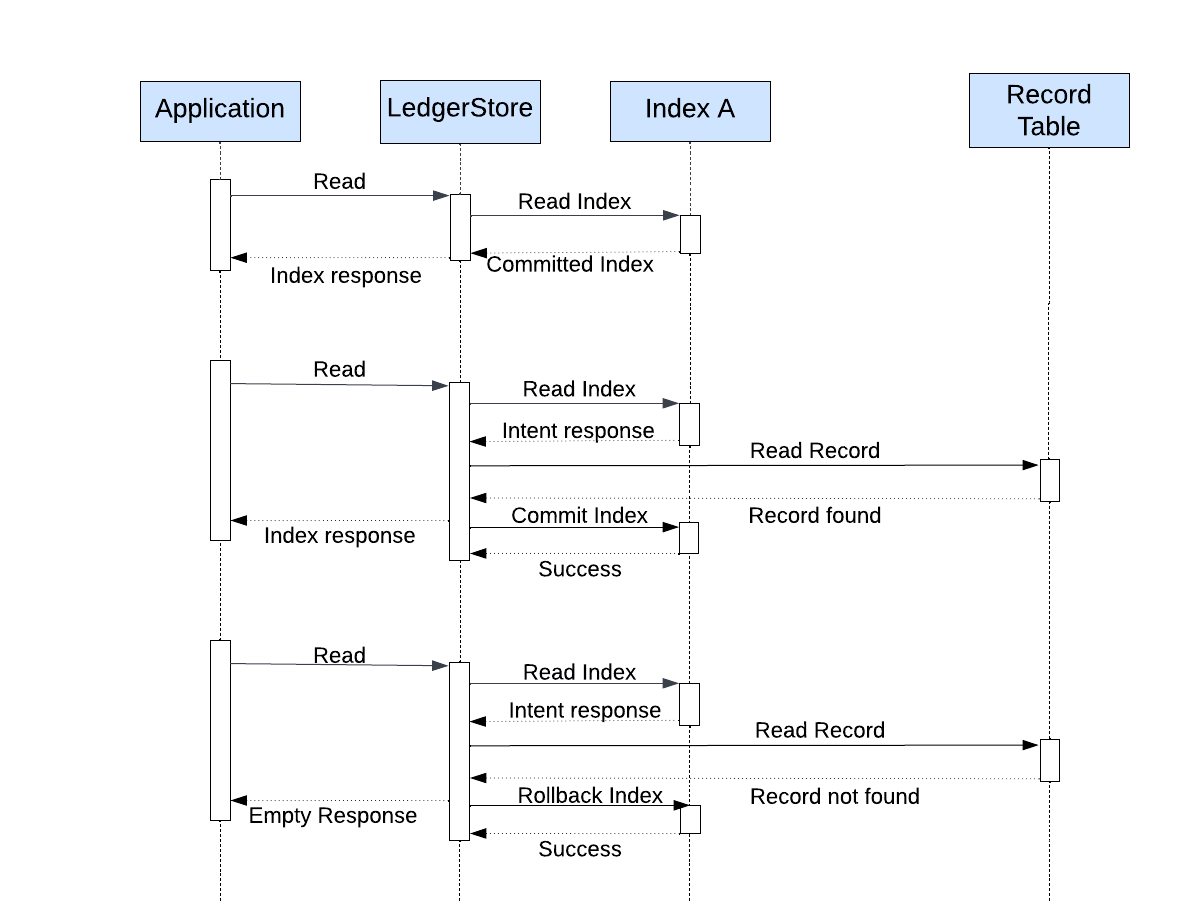
读路径
在插入后,有两种场景:
- 索引提交操作失败
- 写记录失败
这些 intent 在读取路径上通过提交或删除来处理。当读取这些索引时,如果索引没问题,相应的记录会被读取。如果记录存在,索引会被提交,否则回滚。这些操作都是异步的,以免延迟影响用户读取。最终只有极少数索引处于 intent 状态。
最终一致性索引
并非所有索引都需要强读写保证,比如支付历史页面,只要付款出现在页面上,几秒钟的延迟是可以接受的。强一致性索引在某些场景下并不适用,需要权衡以下:
-
高写入延迟
由于写索引 intent 和相应记录必须是串行的,来实现强一致性保证。
-
低可用性
任意索引 intent 写入失败意味着整个写入会失败,否则索引将与记录不一致。
最终一致性索引相反,因为它们是由一个完全独立于在线写路径的后台进程构建的。因此它们的写入延迟不会更高或导致 LedgerStore 服务潜在的可用性降低。
时间范围索引
由于账本的不可变性,它们的体积随时间不断膨胀,从而增加存储成本。因此在 Uber,我们将较旧的账本按时间范围批量转移到更便宜的冷存储中。
每个账本都与一个时间戳相关联。我们需要一类索引来查询时间范围内的数据批次。这个索引的不同之处在于数据是按确定的时间范围批次读取的,其数量级比上面两种索引大得多。
以下示例在账本上进行时间范围查询 SELECT * FROM LEDGER_TABLE WHERE LedgerTime BETWEEN 1701252000000 AND 1701253800000
| 帐 | 事件时间 |
|---|---|
| {trip started} | 10:01 am |
| {trip completed and fare adjusted} | 10:15 am |
| {post trip corrections} | 12:01 pm |
在分布式数据库中有几种办法可以对此建模。我们将深入讨论 Amazon DynamoDB 和 Docstore 数据库上开发时间范围索引的关键差异。DynamoDB 和 Docstore 两种分布式数据库都提供了数据建模结构,如分区键和排序键。前者用于根据值均匀地将数据分配到各分区,后者则用于控制数据的顺序。
用 DynamoDB 设计
DynamoDB 提供两种管理表读/写容量的方式,我们使用 provisioned 模式因为流量不怎么迸发,设置为自动扩展,根据流量模式调整容量。
我们从上面的写入模式中注意到,账本时间通常和当前的时钟相关,因此这些值往往集中在当前时间附近。如果我们基于 G 时间单位粒度来划分数据,那么所有在 G 时间单位内的写入都会落在同一个物理分区,导致热点。DynamoDB 对热分区的吞吐量有限制,导致写请求吞吐量被限制,这是在线写路径中不可接受的。假设每秒 1K 次高峰 Uber 行程,即便 G = 1 秒也不是什么好值,因为这对应了 1K WCU(写容量单元),这是限流前允许的最大 QPS。
随着时间的推移,流量增加可能会导致不稳定。因此我们在 DynamoDB 中的做法是这样:
写优化:临时索引表(称为缓冲索引)
所有在线时间索引写入都进入缓冲索引表。插入的索引项根据相应记录的哈希模数分成 M 个单独的桶,在缓冲区索引表的各分区之间均匀分配负载,从而提升写入效率。M 值也得选择得当,确保每个分区的负载量避免过度拆分;限制读取期间的抓取量。
读优化:永久索引表
由于要对缓冲索引表进行散布-聚集读取,如此读取效率不高。这就带来了读取效率高的永久索引表的需求。
一个永久的时间范围索引表按对齐到某个时间段 N(比如十分钟)的时间戳进行分区。来自缓冲表的索引会定期批量写入到永久索引表中。由于写入是在后台完成的,这里的写入瓶颈不会影响在线流量。批处理的另一个优点是可以将写入流量分布到各分区,减少热分区。将索引卸载到永久索引表后,缓存索引表被删除因为不需要了。在永久索引表上的读取在 N 分钟时间间隔内完成,没有任何散布聚集,使得这个表的读取效率很高。
以下是 DynamoDB 中时间范围索引流的描述,双表设计带来了状态管理和协调的需求,确保读取操作也能访问正确的索引表。
Docstore
DynamoDB 的案例中双表设计运行良好并且可以处理高吞吐量,但也有挑战。如果临时缓冲表未及时创建,会导致写入失败,导致可用性问题。我们将索引存储后端从 DynamoDB 换成 Uber 的 Docstore 数据库来降本增效。作为本次重构的一部分,还改进了时间范围索引设计,利用两个 Docstore 的能力来克服维护双表的缺点:
- Docstore 是在 MySQL 之上构建的分布式数据库,固定数量的分片分配到可变数量的物理分区。物理分区数量随着数据规模增长增加,一些现有的分片被重新分配到新分区。
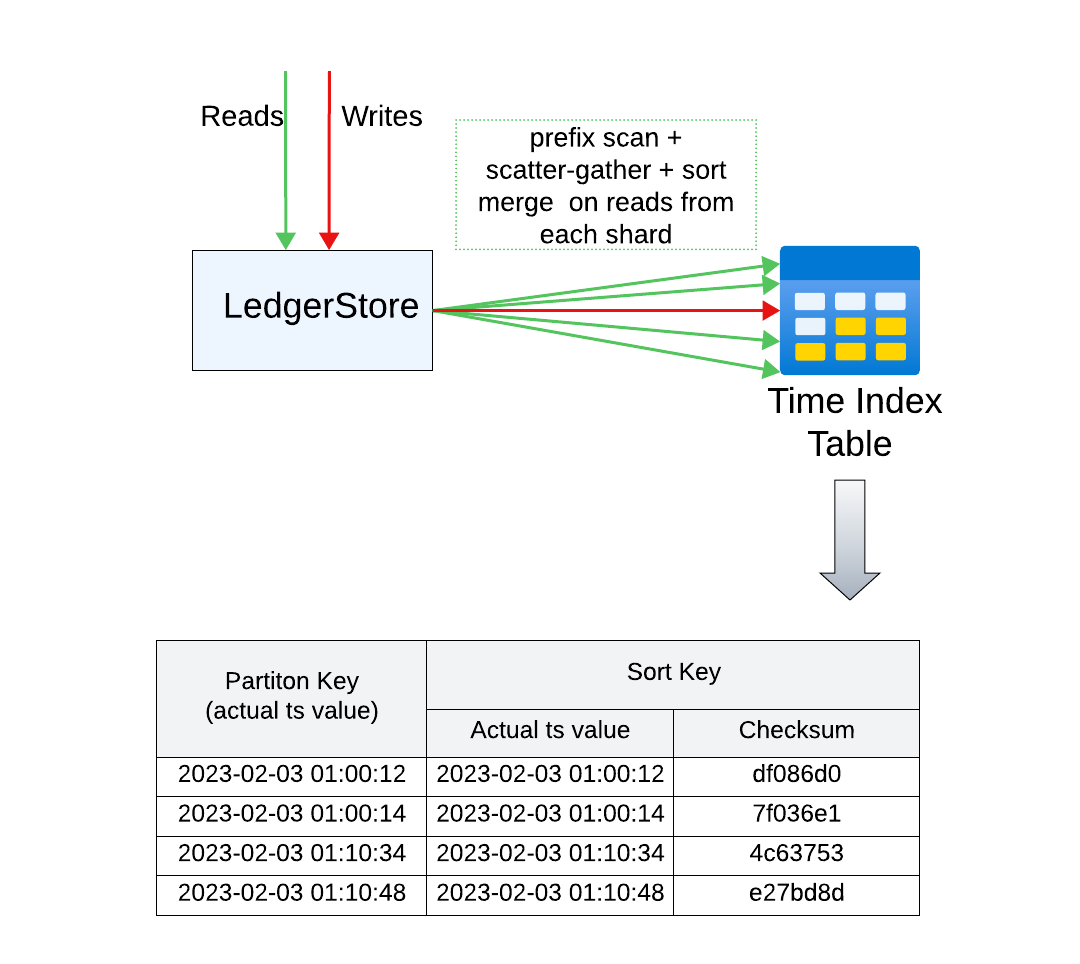
- Docstore 中的数据按主键排序(分区键 + 排序键)
我们只维护一个时间范围索引表,其中索引条目按完整的时间戳分区。由于时间戳非常具体,因此没有热点分区,大部分写入均匀分布在各分区中。
读取操作涉及对每个分片进行前缀扫描,直到某个确定时间。前缀扫描和常规的表扫描非常相似,只是每次扫描的边界由应用程序控制。因此在下面的例子中,要读取 30 分钟的数据,可以从 2023-02-03 01:00:00 到 2023-02-03 01:10:00 以十分钟间隔进行读取,接下来的两个十分钟重复。由于数据按主键排序,这种给定边界的前缀扫描确保只读取这些时间戳内的数据。
在给定的窗口中,首先进行散布-聚集,然后跨分片排序合并,来获得所有时间范围索引条目。由于 Docstore 的分片数量是固定的,我们可以精确地确定需要执行的读取请求数量。在 DynamoDB 的案例中,由于表大小增加,分区数量不断增加,相同的技术不适用。这大大简化了时间索引的设计,并降低了运维成本。
索引生命周期管理
新的索引辉不断定义,有些索引也可能被修改以适应新需求,我们需要一种机制来管理索引生命周期。
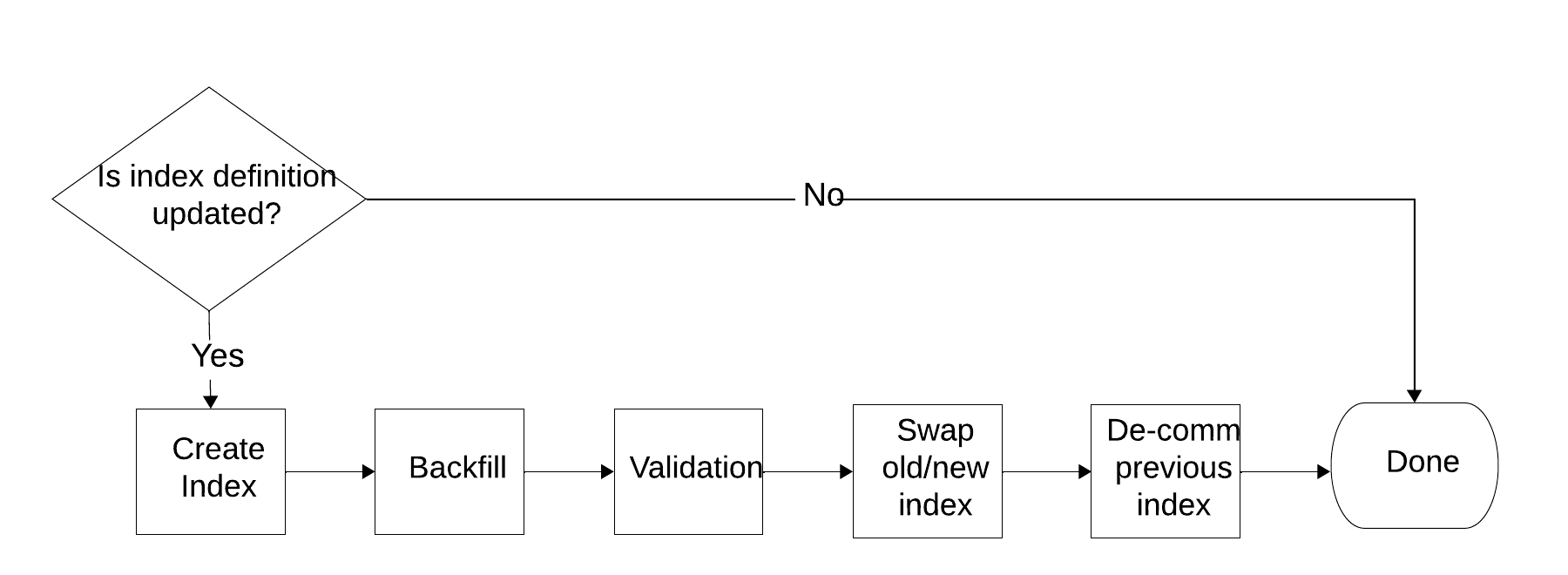
索引生命周期状态机
该组件编排索引的生命周期,包括创建索引表、用历史索引条目回填、验证其完整性、交换新旧索引以及“退役”旧索引。
历史索引数据回填
根据业务用例,需要定义新的索引,必须回填历史索引条目以确保其完整。该组件从卸载到冷数据存储的历史数据构建索引,并以可扩展的方式将它们回填到存储层。考虑到数据下载速度高于数据处理速度,该组件以可重用的方式构建可配置的速率限制和批处理,因为我们可以将实际处理逻辑作为批处理插件加入。
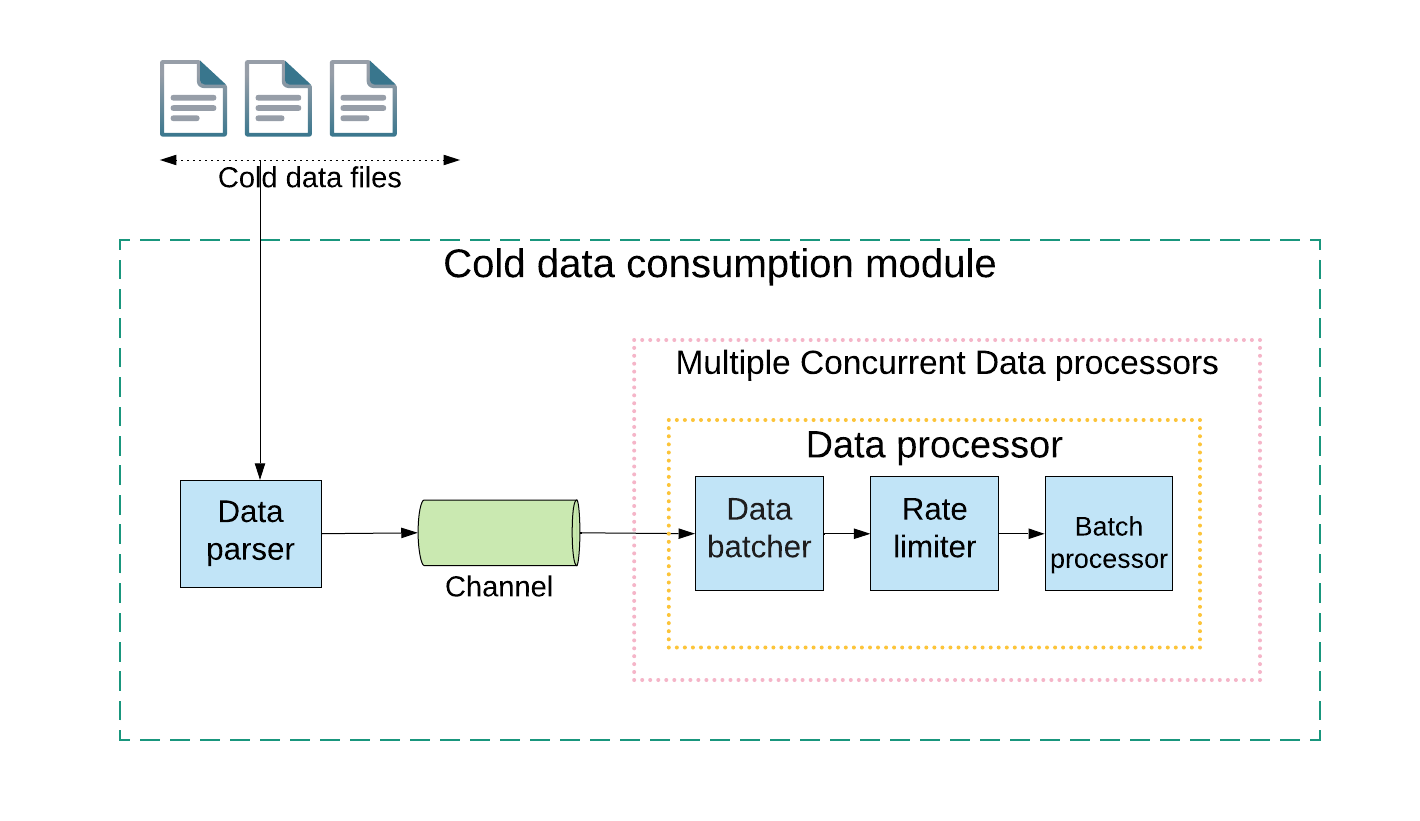
索引校验
在索引回填后,需要验证其完整度。这通过一个离线作业来完成,以一个一定的时间窗口粒度计算顺序无关的校验和,并与真实数据源和索引表比较。此步骤可以识别回填过程中的错误,即使漏掉一个条目,校验和也会不匹配。
亮点
- 我们建立了超过 2 万亿个索引,并在新架构投产后的半年以来,尚未检测到任何数据不一致。
- 在回填期间没有发生任何生产事故,资金流动对 Uber 是非常重要的。
- 我们将所有索引从 DynamoDB 迁移到了 Docstore,因此该项目也减少了外部依赖。
从业务角度来看,由于减少了在 DynamoDB 上的支出,每年节省超过 600 万美元。
总结
在 OLTP 系统中维护 PB 级别的索引有很大的挑战,例如分区不均衡、高读写放大、邻居噪声问题等等。因此在设计这些系统时,数据建模和隔离是需要着重考虑的。此外根据底层数据库的不同,设计可能会差异显著,正如我们从在两个不同的分布式数据库上设计时间范围索引对比中看到的。