Facebook 如何运维其大规模基础设施
Sep 3, 2023 22:00 · 1864 words · 4 minute read

Facebook 的服务依赖于遍布全球的数据中心里的服务器集群,这就是为什么我们需要保障服务器硬件可靠,以及尽可能减小这个规模下硬件故障对服务的影响。
硬件本身可能因为多种原因故障,包括材料老化(HDD 的机械组件)、设备过度使用超出其寿命(NAND 闪存设备)、环境影响(潮湿引起的腐蚀)和制造上的瑕疵。
通常,我们的数据中心有一定程度的硬件故障是在预期内的,这就是为什么我们实现了自己的集群管理系统来最小化服务中断。本文我们介绍四种重要的方法论,帮助我们维持硬件的高度可用性。我们已经打造了可以检测和修复问题的系统,监控并修复硬件,而不会对应用程序的性能产生负面影。我们主动对硬件进行维修,并使用预测的方法来补救。同时自动化地分析大规模硬件和系统故障的根本原因,快速找到问题所在。
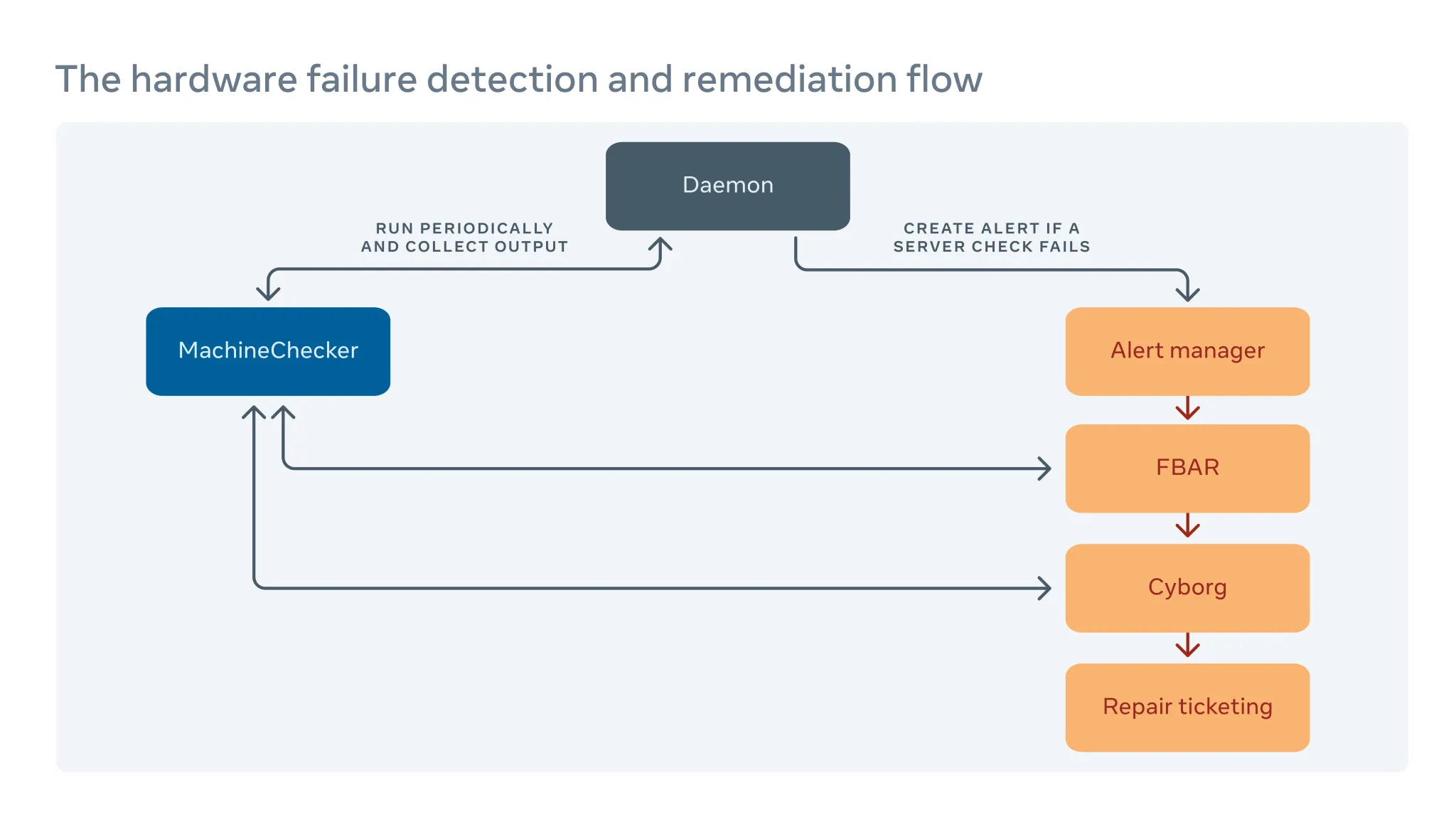
如何实施硬件补救
我们定期地在每台服务器上运行一个名叫 MachineChecker 的工具,以检测硬件和连接故障。一旦 MachineChecker 在中心警报系统中创建了告警,一个名为 Facebook Auto-Remediation(FBAR)的工具会收到这个告警,并执行可定制的补救措施来修复错误。为了确保 Facebook 的服务仍有足够的容量,我们也可以设置速率限制,来限制任意时间正在进行维修的服务器数量。
如果 FBAR 无法将服务器恢复至健康状态,那么故障就会被传递给一个名为 Cyborg 的工具。Cyborg 可以执行较底层的修复操作,例如升级固件和内核以及重做镜像。如果问题需要技术人员手动修理,将在我们的维修工单系统中开一个工单。
在论文 Hardware remediation at scale 中我们深入探讨了这个过程。
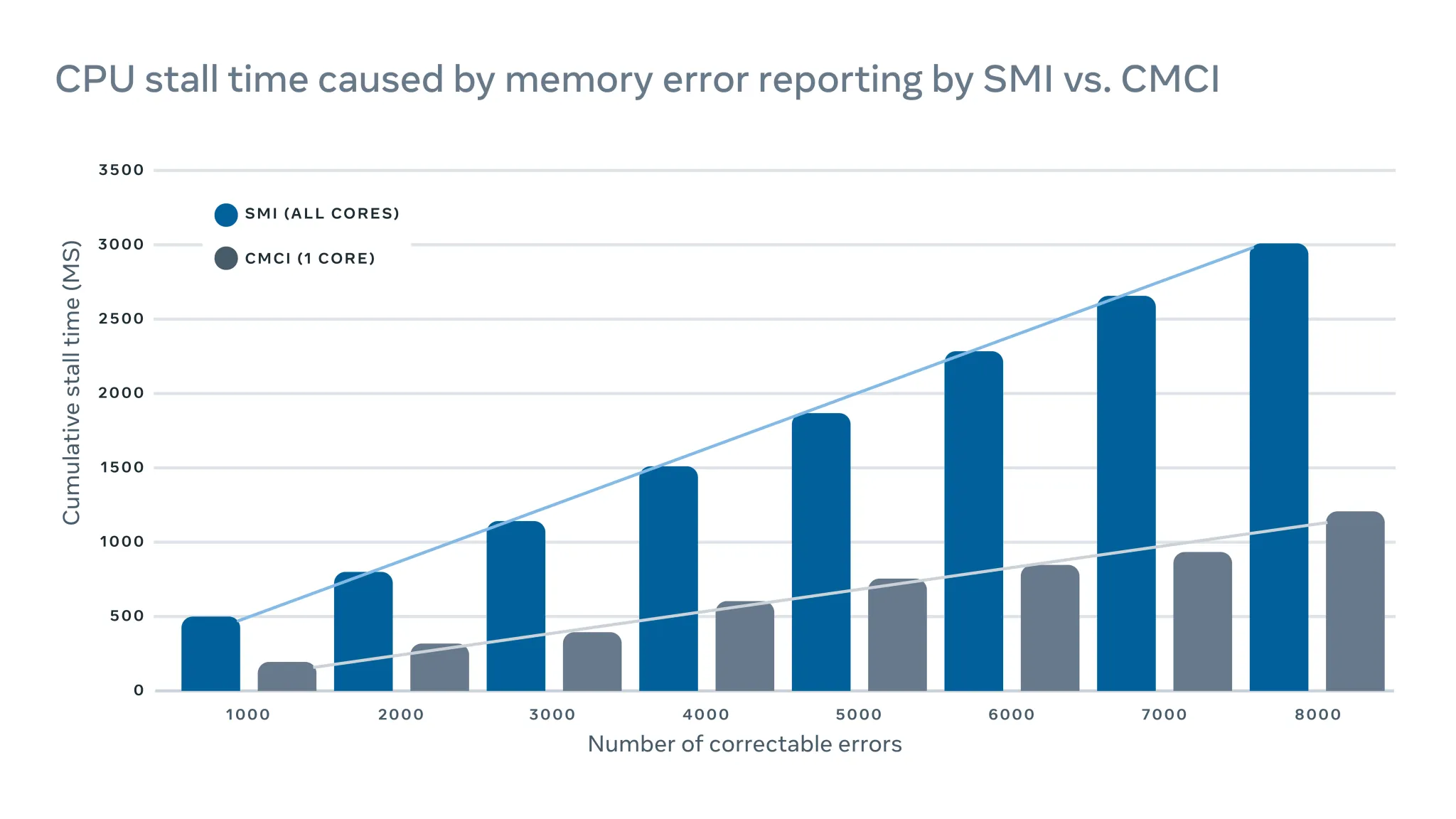
如何最小化错误报告对服务器性能的影响
MachineChecker 通过检查各种服务区日志中的错误来检测硬件故障。通常,当硬件出问题时,会被系统检测到,并向 CPU 发送中断信号来处理和记录该错误。
由于这些中断信号优先级高,CPU 将暂停其手上的活并专注于处理错误。但是这会对服务器性能产生负面影响。例如在记录可纠正的内存错误时,传统的中断管理系统中断(SMI)会停滞所有 CPU,而可纠正的机器检查中断(CMCI)只会停滞其中一个 CPU 核心,其他核心可以正常运行。
尽管 CPU 通常只会停滞几百毫秒,但仍会干扰到对延迟敏感的服务。当规模很大时,这意味着少数机器上的中断可能会对服务级别的性能产生连锁的负面影响。
论文 Optimizing interrupt handling performance for memory failures in large scale data centers 详细讨论了这个问题。
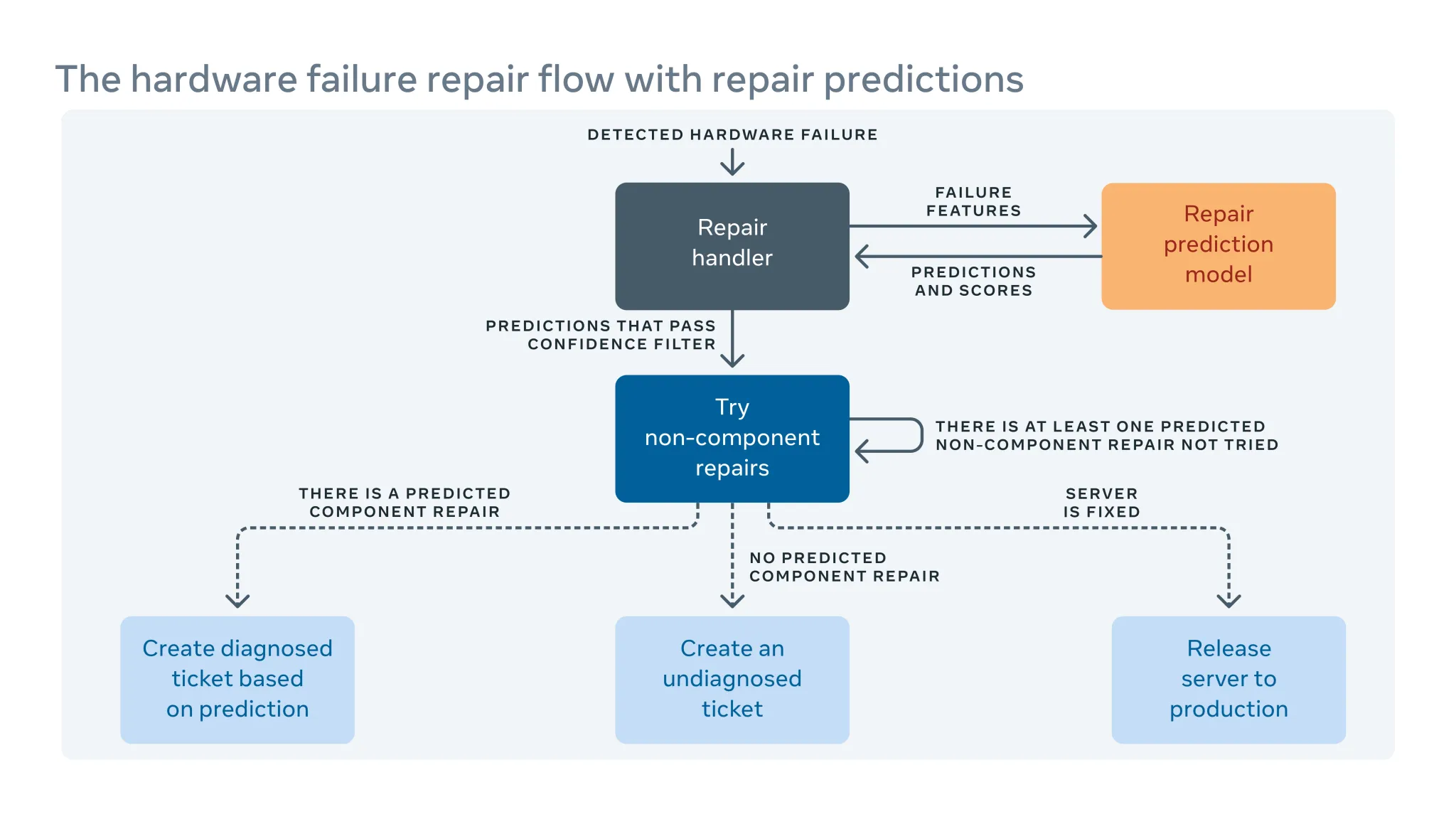
如何利用机器学习来预测维修
由于我们经常在数据中心引入新的硬件和软件配置,因此我们也需要为自动修复系统创建新的规则。
当自动化系统无法修复硬件故障时,问题会被分配一个手动修复的工单。新的硬件和软件意味着必须解决新的潜在故障。但是在实施新的软硬件和我们能够纳入新的补救规则之间可能存在一段时间差。在这期间,一些维修工单可能被归类为“未诊断”,表示系统尚未建议维修,或“误诊”,表示维修并不奏效。这意味着技术人员需要自行诊断问题,从而导致更多的人力和系统停机时间。
为了弥补这个时间差,我们构建了一个机器学习框架,从过去故障修复中学习,并试图预测当前未诊断和误诊的维修单需要如何修复。基于错误和正确预测所带来的开销和收益,我们对每个维修动作的预测信心设定一个阈值,并优化维修动作的顺序。例如在某些情况下,我们更愿意先尝试重启或固件升级,因为这类维修不需要维修任何物理硬件并且完成时间较短,所以算法应该首先推荐此类操作。简而言之,机器学习不仅是我们能够预测如何解决未诊断或误诊的问题,还可以优先处理最重要的问题。
你可以阅读论文 Predicting remediations for hardware failures in large-scale datacenters
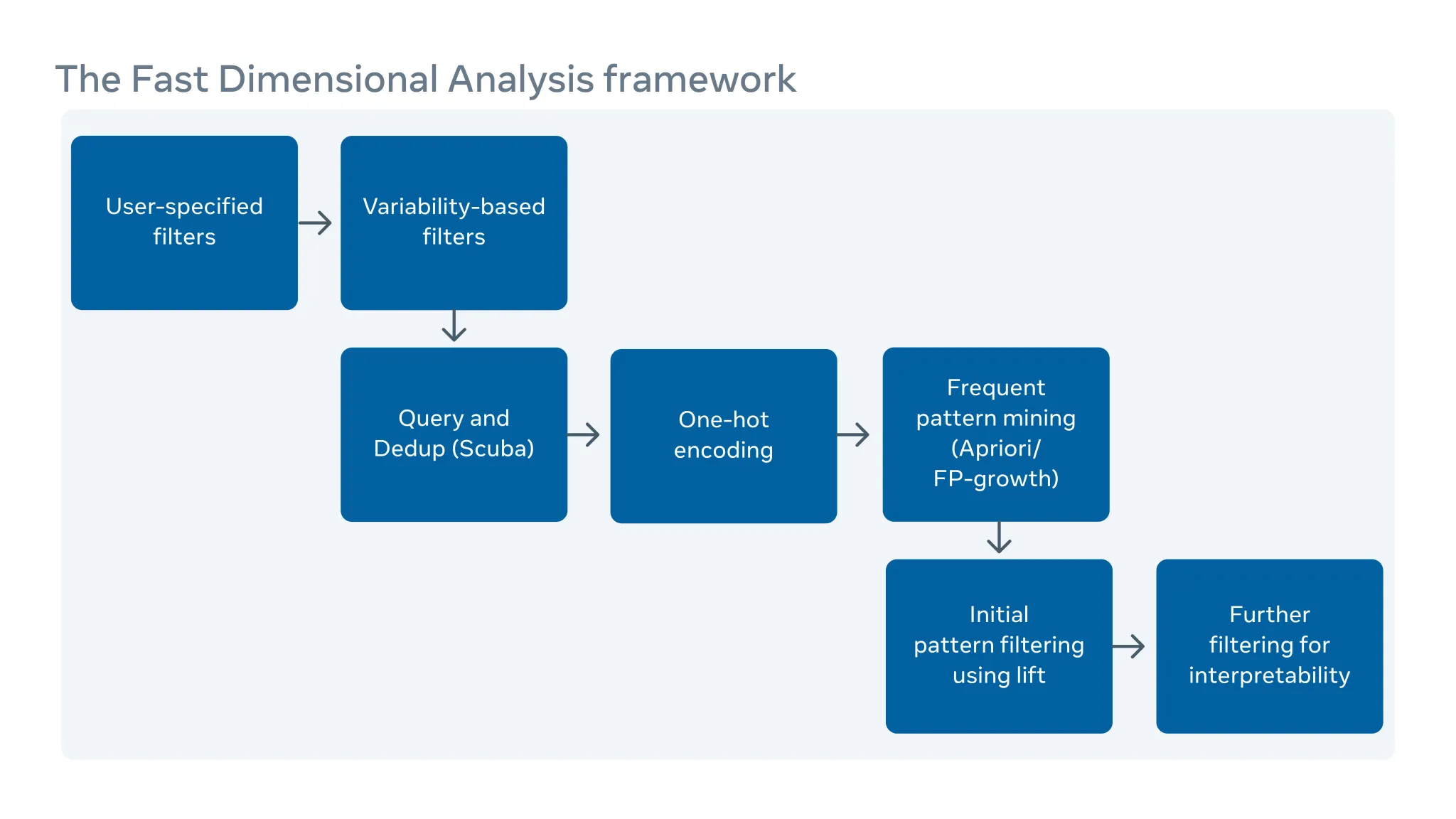
如何自动化地分析集群级别的根因
除了记录重启、内核恐慌、内存不足等服务器日志外,我们的生产系统中还有软件和工具日志。但是规模和复杂度使得我们很难联合检查所有日志以找到它们之间的相关性。
我们实现了一个可扩展的根因分析(RCA)工具,可以筛查数百万条日志条目(每个可能有几百列描述)来找到易于理解和可操作的相关性。
通过使用 Scuba 这种实时内存数据库进行数据预聚合,我们显著地传统模式挖掘算法 FP-Growth 的扩展性,在这套 RCA 框架中来找到相关性。我们添加了一组过滤器以提高结果的可解释性。我们已经广泛地将此分析器部署在 Facebook 内部,用于硬件故障、意外的服务器重启和软件故障的根因分析。
你可以在论文 Fast Dimensional Analysis for Root Cause Investigation in a Large-Scale Service Environment 中阅读更多内容。