Go 内存“压舱物”
Sep 18, 2022 14:00 · 4905 words · 10 minute read

前情介绍
Twitch 有个服务叫 Visage,作为 API 前端。Visage 是所有外来 API 流量的中央网关。它有一堆功能,从授权到请求路由,到最近的服务端 GraphQL。因此,它必须扩展以处理用户流量模式,在某种程度上我们是无法控制的。
举个栗子,有一种我们常见的流量模式叫“刷新风暴”。当互联网出现突发事件时就会发生这种情况,用户不停地刷新页面,瞬间要处理大量 API 流量。
Visage 是运行在 AWS EC2 上的 Go 应用程序(使用 Go1.11 构建),前面有负载均衡器。EC2 在大多数情况下提供了很好的水平扩展能力。
但即使依赖 EC2 的自动扩展,我们在处理流量高峰时仍有问题。在刷新风暴期间,经常在几秒内涌现数百万个请求,是正常负载的 20 多倍。除此之外,当前端服务器处于重负载时,会看到明显的 API 延迟。
一种处理方法是让你的“舰队”长期保持超规模,但这样既浪费又昂贵。为了减少这种不断增加的成本,我们决定花些时间找办法提高单机的吞吐量,并在主机处于高负载状态时提供更可靠的服务。
发现问题
幸运的是我们可以在生产环境运行 pprof,所以很容易就可以获得生产环境的流量侧写。如果你还没用过 pprof,那我极力推荐。采样器大部分时候的 CPU 开销非常低。执行体追踪器的开销也不大,我们可以放心大胆地在生产环境每几小时运行个几秒。
我们查看了 Go 应用程序的侧写,观察到下述现象:
- 在稳定状态,我们的应用程序每秒触发 8 到 10 次垃圾回收(GC),每分钟 400 - 600 次
- 30% 的 CPU 时钟被用于 GC 相关的函数调用
- 在流量高峰期间 GC 次数会增加
- 堆的平均尺寸相当小(< 450Mib)
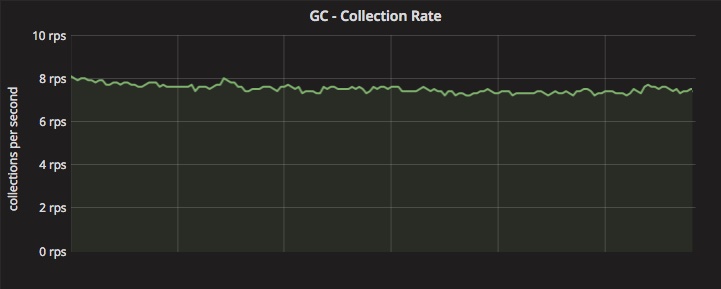
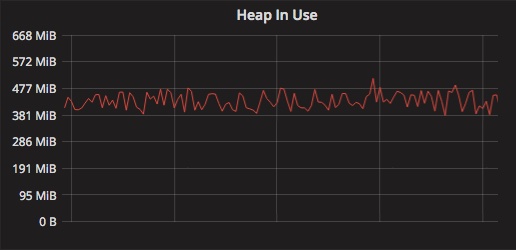
如果你还没猜到我们所做的改进与应用程序中垃圾收集的性能有关。在我进入正题前,下面是 GC 相关的快速回顾。如果你很熟悉了,随意跳过。
什么是垃圾收集(GC)
在现代应用程序中,通常用两种方法分配内存:栈和堆。大多数程序员更熟悉栈是因为编写递归的程序会引发栈溢出(stack overflow)。而堆则是一种被用于动态分配的内存池。
栈分配只存活于他们所属的函数的生命周期中。但堆分配,在它们跳出作用域时不会自动自动释放。为了防止堆不受约束地增长,我们必须显式地释放,或在有内存管理的编程语言(Go 就是)中,依靠垃圾收集器来寻找和删除不再被引用的对象。
一般来说在有 GC 的语言中,在栈中存储的越多越好,因为 GC 永远看不到这些分配。编译器使用一种叫做逃逸分析的技术来决定在栈上分配还是必须放到堆上。
在实践中,编写强迫编译器只在栈上分配的程序会有很大的局限性,因此在 Go 中,我们利用其出色的 GC 来保持堆的清洁。
Go GC
GC 是相当复杂的软件工程。
自 v1.5,Go 采用一种并发的标记-清扫 GC。这种类型的 GC,如其名有两个阶段:标记和清扫。“并发”只是意味着在 GC 期间它不会 STW(Stop The World),而是同应用程序代码一起运行。在标记期间,运行时会遍历堆上应用程序引用的所有对象并将它们标记为仍在使用中。这些对象被称为实时内存。下一个节点,堆上所有未标记的都会被垃圾回收掉,由清扫器释放。
解释一下术语:
- 堆尺寸(heap size)——包括了堆上的所有分配,有的有用,有的是垃圾。
- 实时内存(live memory)——指向所有正在被运行中的应用程序引用的分配,不是垃圾。
标记涉及到遍历应用程序当前指向的所有对象,所以时间与系统中的实时内存数量成正比,而与堆的总大小无关。换句话说,堆上有垃圾不会增加标记的时间,因此也不会显著地增加 GC 周期的计算时间。
综上所述,较低频的 GC 意味着更少的标记,也意味着花费更少的 CPU,这看起来合理,但牺牲了什么?嗯,是内存。运行时在 GC 前等待的时间越久,系统内存中积累的垃圾就越多。
正如我们之前指出的,Visage 运行在 64GB 内存的虚机上,但 GC 非常频繁,只使用了约 400 MiB 物理内存。为了理解为什么会导致这种情况,我们需要深入了解 Go 是如何权衡 GC 频率和内存使用的。
节拍器(Pacer)
Go GC 使用一种节拍器来决定何时触发下一次 GC。节拍被建模为一个控制问题,试图找到正确的时间来触发 GC 来达到期望的堆尺寸目标。Go 默认的节拍器会每次在堆大小翻倍时尝试着出发一次 GC。它通过在当前 GC 周期的标记结束阶段设置下一个堆的触发大小来实现。因此在标记完所有实时内存后,当堆的总大小是当前实时集的两倍时,做决策触发下一次 GC。2x 这个值来自变量 GOGC,运行时用来设置触发频率。
在我们的案例中,节拍器做得非常好,将堆上的垃圾保持在最小,但以不必要的工作为代价,因为我们只用了 0.6% 的系统内存。
介绍压舱物
压舱物——航海时装在船上提供所需吃水深度和稳定性的重物。
在我们的应用程序中,压舱物是一块大内存分配,为堆提供稳定性。
我们通过在应用程序启动时分配一个相当大的数组来实现:
func main() {
// Create a large heap allocation of 10 GiB
ballast := make([]byte, 10<<30)
// Application execution continues
}
阅读完上面代码你可能有两个问题:
- 为什么要这样做?
- 这样不会占用掉 10GiB 宝贵的内存吗?
如前所述,每次堆大小翻倍都会触发 GC。堆大小是堆上分配的总大小。因此,如果分配了 10GiB 的压舱物,那么只有当堆大小增长到 20GiB 时才会触发下一次 GC,大约 10GiB 的压舱物 + 10GiB 的其他分配。
当 GC 运行时,由于 main 函数中仍然持有对压舱物的引用,因此被认为是实时内存的一部分,不会被当作垃圾清扫。由于在我们的应用程序中大多数分配只存在于 API 请求的短暂生命周期中,10Gi 分配中的大部分将被扫除,再次将堆缩减到将将超过 10GiB。现在下一次 GC 将在堆大小(目前只比 10GiB 大一点)再次翻倍时发生。
综上所述,压舱物增加了堆的基础大小,这样 GC 就会延迟触发,GC 周期的数量也会减少。
使用字节数组来作为压舱物,是为了确保我们在标记阶段只增加一个额外的对象。由于字节数组没有任何指针,GC 可以在 O(1) 时间内标记整个对象。
推出这项变化后,正如预期,我们看到 GC 次数减少了约 99%:
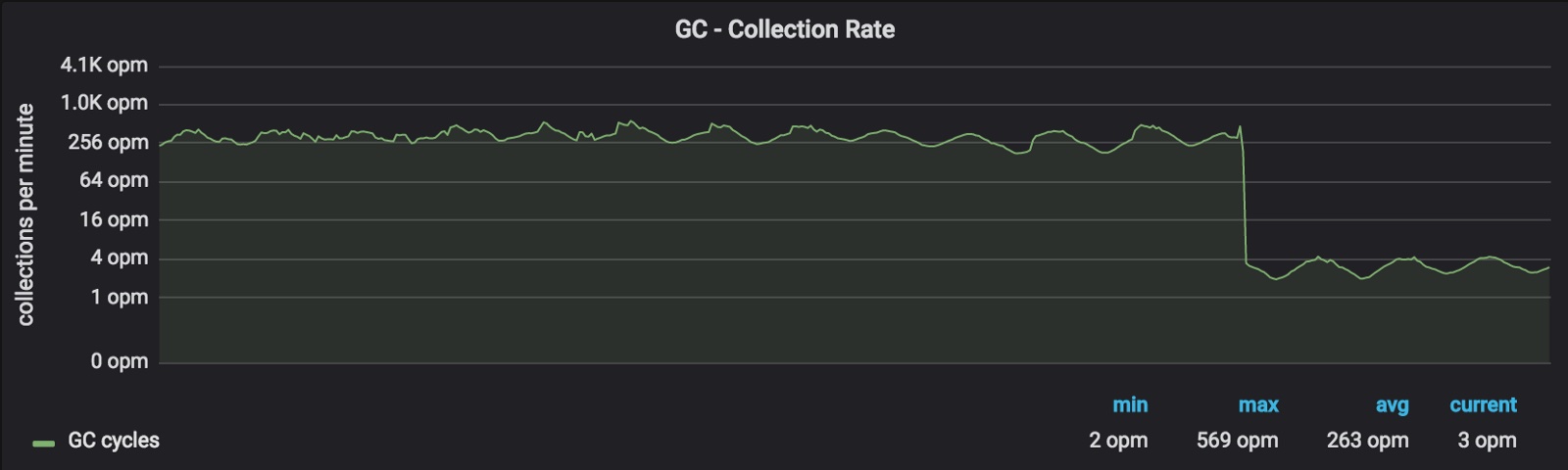
看上去不错,那么 CPU 使用率呢?
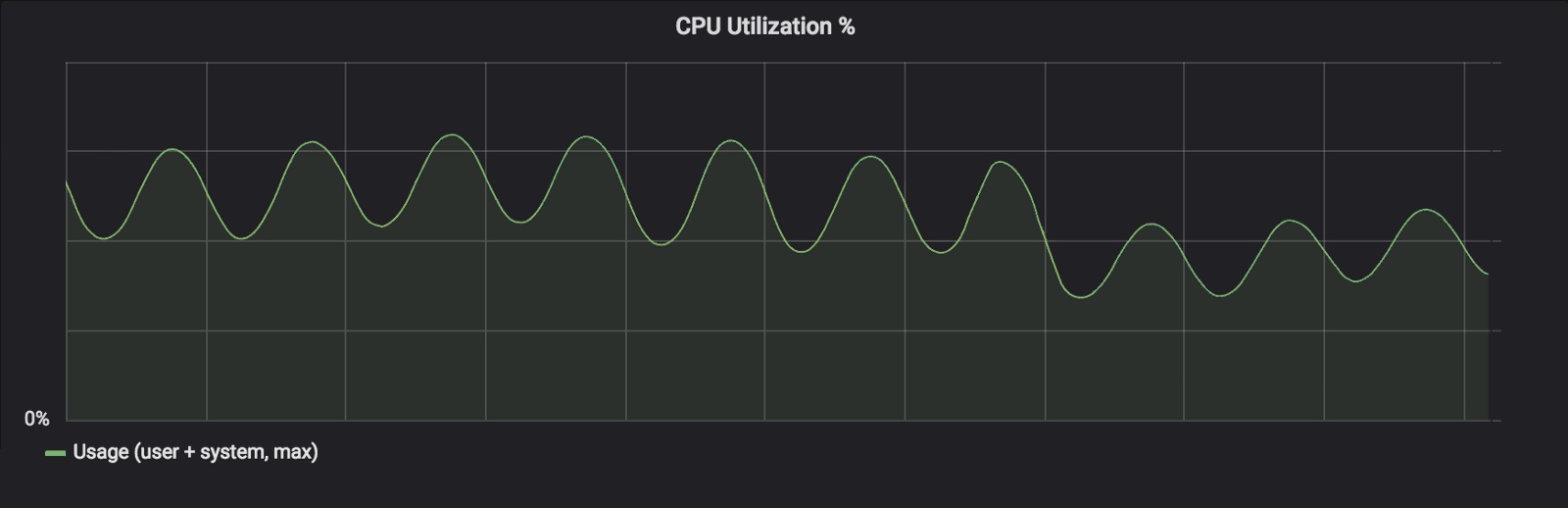
绿色的 CPU 使用率呈正弦波装是由于我们流量的日常振荡。可以看到变更后有所下降。
每个方块的 CPU 减少了约 30% 意味着我们可以将“舰队”规模缩小 30%,但是我们还关心 API 延迟。
上面提到,Go 运行时提供了一个 GOGC 环境变量允许对 GC 节拍器进行粗调。这个值控制了在触发 GC 前堆可以增长的比例。我们选择不使用这个,因为它有些明显的隐患:
- 比例本身对我们来说不重要;我们使用的内存量才是
- 我们必须把这个值设置得很高才能得到和压舱物相同的效果,容易受到存活的堆大小变化影响
- 推算实时内存及其变化率不容易;而思考使用的总内存则很简单
有一项提议是向 GC 添加一个目标堆大小的选项,对那些感兴趣的人来说,希望它能很快进入 Go 运行时。
现在来到第二个问题,这样不会占用掉 10GiB 宝贵的内存吗?答案是不会,除非你故意为之。类 nix 操作系统(甚至 Windows)使用虚拟内存,通过页表映射。当那段代码运行时,压舱物切片指向的数组将被分配到程序的虚拟地址空间中。只有当我们试图对切片读写,才会发生缺页,导致虚拟地址后面的物理内存被分配。
我们可以这样来确认:
func main() {
_ = make([]byte, 100<<20)
<-time.After(time.Duration(math.MaxInt64))
}
运行程序然后 ps 检查:
$ ps -eo pmem,comm,pid,maj_flt,min_flt,rss,vsz --sort -rss | numfmt --header --to=iec --field 4-5 | numfmt --header --from-unit=1024 --to=iec --field 6-7 | column -t | egrep "[t]est|[P]ID"
%MEM COMMAND PID MAJFL MINFL RSS VSZ
0.2 test_alloc 27826 0 1003 4.8M 108M
只有超过 100MiB 的内存被虚拟化地分配给了进程——Virtual SiZe(VSZ),同时约 5MiB 被分配在驻留集——Resident Set Size(RSS),即物理内存。
现在我们修改程序,写入一半切片底层的字节数组:
func main() {
ballast := make([]byte, 100<<20)
for i := 0; i < len(ballast)/2; i++ {
ballast[i] = byte('A')
}
<-time.After(time.Duration(math.MaxInt64))
}
再用 ps 检查:
%MEM COMMAND PID MAJFL MINFL RSS VSZ
2.7 test_alloc 28331 0 1.5K 57M 108M
正如预期,现在有一半的字节数组在 RSS 中占用物理内存。VSZ 没变化,因为两个程序虚拟分配大小相同。
对感兴趣的人来说,MINFL 一栏是次要页故障(Minor Page Faults)数量——这是进程发生需要从内存中加载页面的故障数量。如果操作系统能够连续地分配物理内存,那么每个页面故障将能够映射超过一个 RAM 页面,减少页面故障的数量。
所以只要不读写压舱物,就可以保证它只作为一个虚拟分配停留在堆上。
API 延迟呢?
上面提到,我们看到了 API 延迟的改善(特别在高负载期间)是 GC 频率降低的结果。最初我们认为可能是因为 GC 暂停时间的减少——GC 周期内 STW 的时长。但实际上 GC 暂停时间并无明显差异。此外,暂停时间只有几毫秒,而不是在高峰负载时看到的 100 多毫秒的改进。
要理解延迟是如何改善的,我们要谈一谈 Go GC 一个叫做*辅助(assists)*的功能。
GC 辅助
GC 辅助将 GC 周期中内存分配的任务交由负责分配的 goroutine。如果没有这个机制,运行时无法防止在 GC 周期中堆不受约束地增长。
由于 Go 已经有一个运行在后台的 GC worker,所以术语 assists 指的是协助后台 worker 的 goroutine。特别是协助标记工作。
为了更好地理解这点,我们举个栗子:
someObject := make([]int, 5)
当执行这段代码,通过一系列的符号转换和类型检查,goroutine 调用 runtime.makeslice,该函数又调用 runtime.mallocgc 来为切片分配一些内存。
查看 runtime.mallocgc 函数,我们看到有趣的代码路径:
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// Some error checking and debug code omitted here...
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// Actual allocation code ommited below...
}
上面这段代码,if assistG.gcAssistBytes < 0 会检查在 GC 周期内是否 goroutine 的分配量超过了它所做的 GC 工作。
你可以认为这就像你的 goroutine 在 GC 周期中必须为分配交税,只是这个税必须在分配真正发生前预付。此外,税与 goroutine 试图分配的量成正比。这在一定程度上是公平的,很多 goroutine 将会为这些分配付出代价。
所以假设这是 goroutine 在当前 GC 周期内的第一次分配,它将被迫做 GC 辅助工作。gcAssistAlloc 调用很有趣。
这个函数负责一些内务,最终调用 gcAssistAlloc1 来执行真正的 GC 协助工作。我不细说 gcAssistAlloc 函数的细节,基本上就干了这些事:
- 检查 goroutine 是否在做一些不可抢占的事情
- 执行 GC 标记工作
- 检查 goroutine 是否还有分配债务,否则返回
- goto 2
现在应该清楚了,任何涉及分配工作的 goroutine 都会在 GC 周期中产生辅助工作。由于这些工作必须在分配前完成,这将会表现成 goroutine 实际的工作延迟或者缓慢。
在我们的 API 前端,这意味着 API 响应在 GC 周期中出现延迟增加。随着服务器负载变大,内存分配率也增加,这又反过来提高了 GC 周期的速率(通常每秒 10s 或 20s 的周期)。我们现在知道,更多的 GC 周期意味着对为 API 服务的 goroutine 来说 GC 辅助工作更多,因此 API 延迟增大。
你可以从我们应用程序的执行追踪中很清楚地看到这点。下面是 Visage 的两个片段,一个是 GC 周期中,另一个不是。

追踪展示了哪些 goroutine 正在哪个处理器上运行。被打上 app-code 标签的是执行应用程序业务逻辑的 goroutine。注意除了运行 GC 代码的四个专用进程外,我们其他的 goroutine 被迫延迟来协助标记了(runtime.gcAssistAlloc)。

在这里 goroutine 集中精力运行业务代码,符合预期。
所以通过简单地降低 GC 频率,我们看到辅助标记工作下降了接近 99%,这转化为流量高峰期 P99 API 延迟改善了 45%。
你可能好奇为啥 Go 要这样设计它的 GC(使用辅助),但实际上很有意义。GC 的主要功能是将堆维持在一个合理的大小,不要让它因为垃圾无限制增长。这在 STW GC 中很容易做到,但是在并发的 GC 中,我们需要一种机制来确保 GC 周期内发生的分配不会无限制增长。在我看来,让每个 goroutine 在 GC 周期中按分配的比例“交税”是一个相当优雅的设计。
关于设个设计选择,请阅读文档 https://docs.google.com/document/d/1wmjrocXIWTr1JxU-3EQBI6BK6KgtiFArkG47XK73xIQ/edit。
总结
- 我们留意到应用程序干了一大堆 GC 工作
- 实现了一个内存压舱物
- 通过允许堆变得更大减少 GC 次数
- 因为 Go GC 更少地强迫业务 goroutine 辅助工作,API 延迟也得到了改善
- 压舱物分配基本没啥成本因为它只驻留在虚拟内存中
- 压舱物比配置
GOGC值更简单合理
Go 在抽象许多运行时细节方面做的很好。对大多数程序员和应用程序来说,很棒很有效。
当你开始挑战应用程序环境的极限时,无论是计算、内存还是 I/O,必须掀开引擎盖看看,找出引擎无法有效运行的原因。当你需要这样做的时候,Go 提供了一套工具,帮你迅速发现瓶颈。