Docker 单机网络模型动手实验
Sep 30, 2020 00:00 · 3939 words · 8 minute read
转载自 https://github.com/mz1999/blog/blob/master/docs/docker-network-bridge.md
容器的本质
容器的本质就是一个进程,只不过对它进行了 Linux Namesapce 隔离,让它看不到外面的世界,用 Cgroups 限制了它能使用的资源,同时利用系统调用 pivot_root 或 chroot 切换了进程的根目录,把容器镜像挂载为根文件系统 rootfs。rootfs 中不仅有要运行的应用程序,还包含了应用的所有依赖库,以及操作系统的目录和文件。rootfs 打包了应用运行的完整环境,这样就保证了在开发、测试、线上等多个场景的一致性。
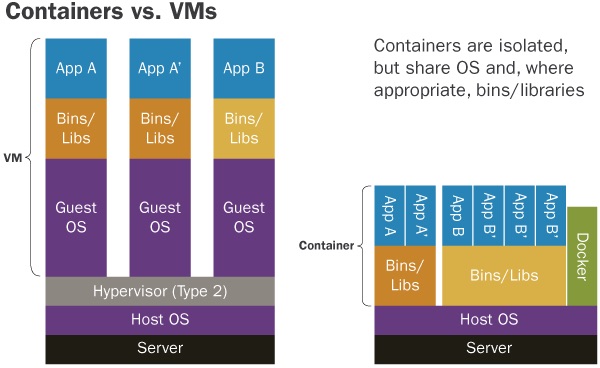
从上图可以看出,容器和虚拟机的最大区别就是,每个虚拟机都有独立的操作系统内核 Guest OS,而容器只是一种特殊的进程,它们共享同一个操作系统内核。
看清了容器的本质,很多问题就容易理解。例如我们执行 docker exec 命令能够进入运行中的容器,好像登录进独立的虚拟机一样。实际上这只不过是利用系统调用 setns,让当前进程进入到容器进程的 Namesapce 中,它就能“看到”容器内部的情况了。
关于容器涉及的基础技术,左耳朵耗子多年前写的系列文章仍然很有参考价值:
- DOCKER 基础技术:LINUX NAMESPACE(上)
- DOCKER 基础技术:LINUX NAMESPACE(下)
- DOCKER 基础技术:LINUX CGROUP
- DOCKER 基础技术:AUFS
- DOCKER 基础技术:DEVICEMAPPER
容器网络
如何让容器之间互相连接保持网络通畅,Docker 有多种网络模型。对于单机上运行的多个容器,可以使用缺省的 bridge 网络驱动。而容器的跨主机通信,一种常用的方式是利用 Overlay 网络,基于物理网络的虚拟化网络来实现。
本文会在单机上实验展示 bridge 网络模型,揭示其背后的实现原理。下一篇文章会演示容器如何利用 Overlay 网络进行跨主机通信。
我们按照下图创建网络拓扑,让容器之间网络互通,从容器内部可以访问外部资源,同时,容器内可以暴露服务让外部访问。
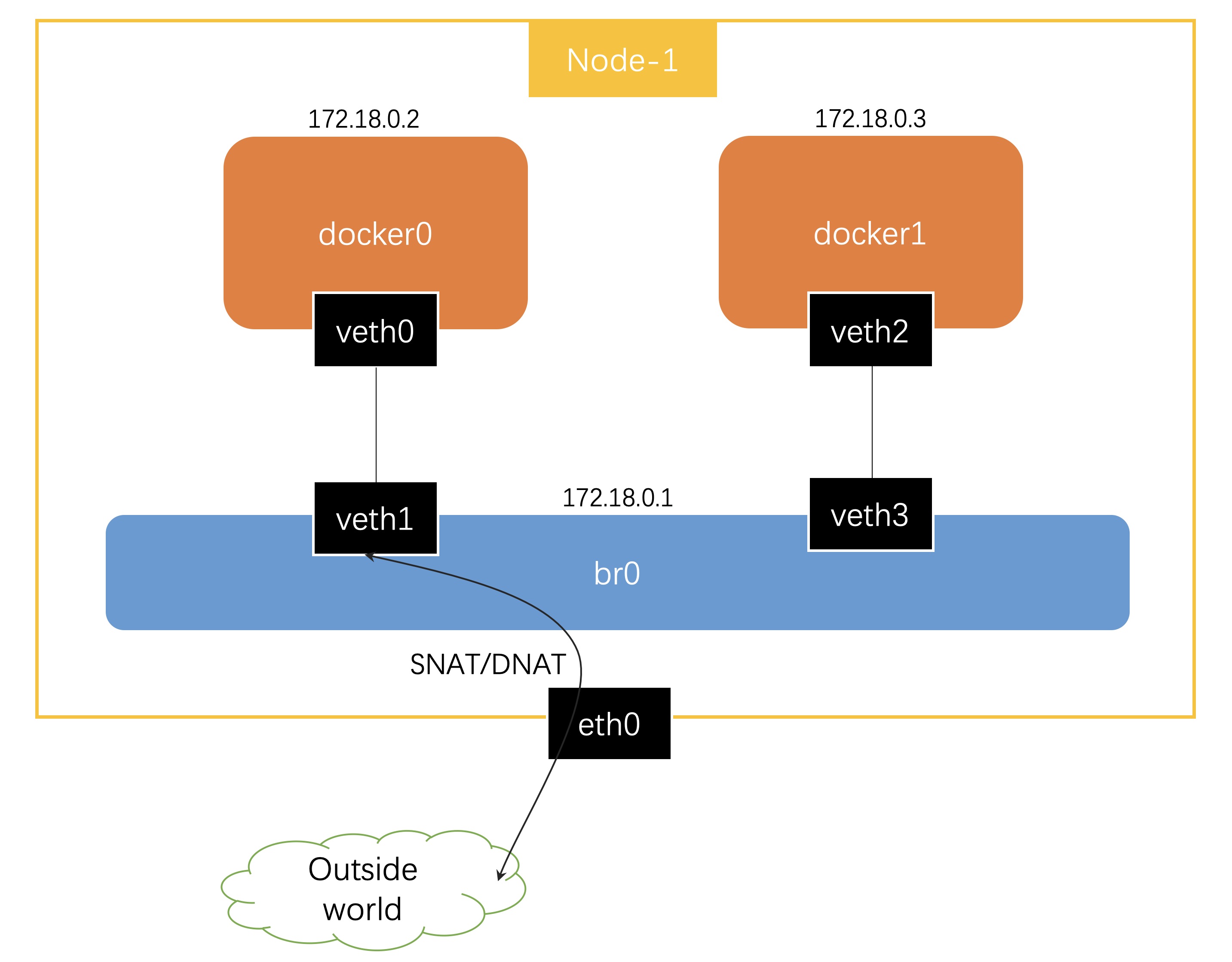
在开始动手实验之前,先简单介绍一下 bridge 网络模型会用到的 Linux 虚拟化网络技术。
Veth Pairs
Veth 是成对出现的两张虚拟网卡,从一端发送的数据包,总会在另一端接收到。利用 Veth 的特性,我们可以将一端的虚拟网卡"放入"容器内,另一端接入虚拟交换机。这样,接入同一个虚拟交换机的容器之间就实现了网络互通。
Linux Bridge
交换机是工作在数据链路层的网络设备,它转发的是二层网络包。最简单的转发策略是将到达交换机输入端口的报文,广播到所有的输出端口。当然更好的策略是在转发过程中进行学习,记录交换机端口和 MAC 地址的映射关系,这样在下次转发时就能够根据报文中的 MAC 地址,发送到对应的输出端口。
我们可以认为 Linux bridge 就是虚拟交换机,连接在同一个 bridge 上的容器组成局域网,不同的 bridge 之间网络是隔离的。docker network create [NETWORK NAME] 实际上就是创建出虚拟交换机。
iptables
容器需要能够访问外部世界,同时也可以暴露服务让外界访问,这时就要用到 iptables。另外,不同 bridge 之间的隔离也会用到 iptables。
我们说的 iptables 包含了用户态的配置工具(/sbin/iptables)和内核 netfilter 模块,通过使用 iptables 命令对内核的 netfilter 模块做规则配置。
netfilter 允许在网络数据包处理流程的各个阶段插入 hook 函数,可以根据预先定义的规则对数据包进行修改、过滤或传送。
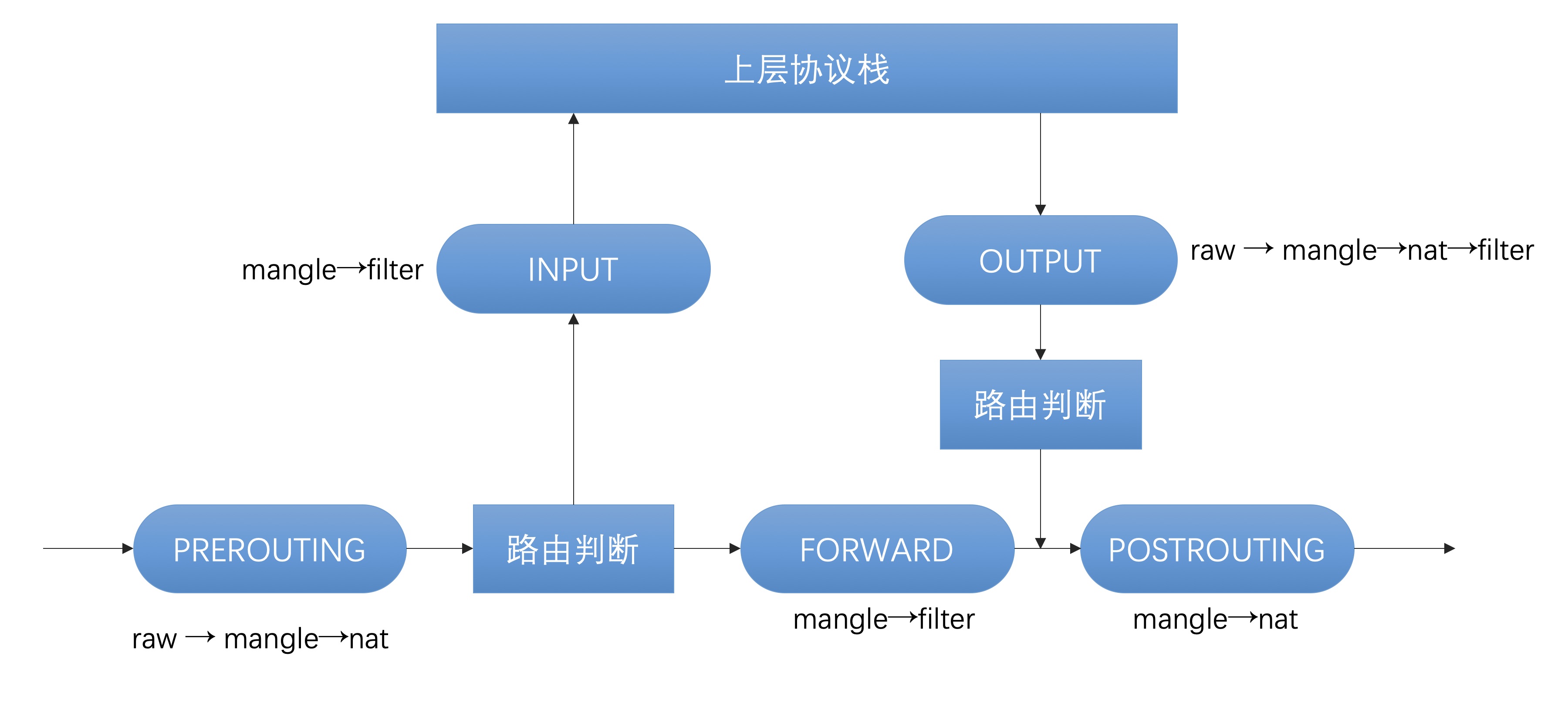
从上图可以看出,网络包的处理流程有五个关键节点:
PREROUTING:数据包进入路由表之前INPUT:通过路由表后目的地为本机FORWARDING:通过路由表后,目的地不为本机OUTPUT:由本机产生,向外转发POSTROUTIONG:发送到网卡接口之前
iptables 提供了四种内置的表 raw → mangle → nat → filter,优先级从高到低:
raw用于配置数据包,raw中的数据包不会被系统跟踪。不常用。mangle用于对特定数据包的修改。不常用。nat: 用于网络地址转换(NAT)功能(端口映射,地址映射等)。filter:一般的过滤功能,默认表。
每个表可以设置在多个指定的节点,例如 filter 表可以设置在 INPUT、FORWARDING、OUTPUT 等节点。同一个节点中的多个表串联成链。
iptables 是按照表的维度来管理规则,表中包含多个链,链中包含规则列表。例如我们使用 sudo iptables -t filter -L 查看 filter 表:

可以看到,filter 表中包含三个链,每个链中定义了多条规则。由于 filter 是缺省表,上面的命令可以简化为:sudo iptables -L,即不通过 -t 指定表时,操作的就是 filter 表。
在容器化网络场景,我们经常用到的是在 nat 表中设置 SNAT 和 DNAT。源地址转换是发生在数据包离开机器被发送之前,因此 SNAT 只能设置在 POSTROUTIONG 阶段。DNAT 是对目标地址的转换,需要在路由选择前完成,因此可以设置在 PREROUTING 和 OUTPUT 阶段。
动手实验
有了前面的背景知识,我们就可以开始动手实验了。因为涉及到很多系统级设置,建议在一个“干净”的虚拟机内折腾,以免干扰到工作环境。我使用的实验环境是 Ubuntu 18.04.1 LTS,不需要安装 Docker,我们使用系统命令模拟出容器网络环境。
场景一:容器间的网络互通
- 创建“容器”
从前面的背景知识了解到,容器的本质是 Namespace + Cgroups + rootfs。因此本实验我们可以仅仅创建出 Namespace 网络隔离环境来模拟容器行为:
$ sudo ip netns add docker0
$ sudo ip netns add docker1
查看创建出的网络 Namesapce:
$ ls -l /var/run/netns
-r--r--r-- 1 root root 0 Nov 11 03:52 docker0
-r--r--r-- 1 root root 0 Nov 11 03:52 docker1
- 创建 Veth Pairs
$ sudo ip link add veth0 type veth peer name veth1
$ sudo ip link add veth2 type veth peer name veth3
查看创建出的 Veth Pairs:
$ ip addr show
...
3: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3e:fe:2b:90:3e:b7 brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 6a:a3:02:07:f4:92 brd ff:ff:ff:ff:ff:ff
5: veth3@veth2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 76:14:e5:0e:26:98 brd ff:ff:ff:ff:ff:ff
6: veth2@veth3: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 6a:0a:84:0f:a7:f7 brd ff:ff:ff:ff:ff:ff
- 将 Veth 的一端放入“容器”
设置 Veth 一端的虚拟网卡的 Namespace,相当于将这张网卡放入“容器”内:
$ sudo ip link set veth0 netns docker0
$ sudo ip link set veth2 netns docker1
查看“容器” docker0 内的网卡:
$ sudo ip netns exec docker0 ip addr show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 6a:a3:02:07:f4:92 brd ff:ff:ff:ff:ff:ff link-netnsid 0
ip netns exec docker0 ... 的意思是在网络 Namesapce docker0 的限制下执行后面跟着的命令,相当于在“容器”内执行命令。
可以看到,veth0 已经放入了“容器” docker0 内。同样使用命令 sudo ip netns exec docker1 ip addr show 查看“容器” docker1 内的网卡。
同时,在宿主机上查看网卡 ip addr,发现 veth0 和 veth2 已经消失,确实是放入“容器”内了。
- 创建 bridge
安装 bridge 管理工具 brctl
$ sudo apt-get install bridge-utils
创建 bridge br0:
$ sudo brctl addbr br0
- 将 Veth 的另一端接入 bridge
$ sudo brctl addif br0 veth1
$ sudo brctl addif br0 veth3
查看接入效果:
$ sudo brctl show

两个网卡 veth1 和 veth3 已经“插”在 bridge 上。
- 为"容器“内的网卡分配 IP 地址,并激活上线
docker0 容器:
$ sudo ip netns exec docker0 ip addr add 172.18.0.2/24 dev veth0
$ sudo ip netns exec docker0 ip link set veth0 up
docker1 容器:
$ sudo ip netns exec docker1 ip addr add 172.18.0.3/24 dev veth2
$ sudo ip netns exec docker1 ip link set veth2 up
- Veth 另一端的网卡激活上线
$ sudo ip link set veth1 up
$ sudo ip link set veth3 up
- 为 bridge 分配 IP 地址,激活上线
$ sudo ip addr add 172.18.0.1/24 dev br0
$ sudo ip link set br0 up
- “容器”间的互通测试
我们可以先设置监听 br0:
$ sudo tcpdump -i br0 -n
从容器 docker0 ping 容器 docker1:
$ sudo ip netns exec docker0 ping -c 3 172.18.0.3
br0 上监控到的网络流量:
05:53:10.859956 ARP, Request who-has 172.18.0.3 tell 172.18.0.2, length 28
05:53:10.859973 ARP, Reply 172.18.0.3 is-at 06:f4:01:c2:dd:6e, length 28
05:53:10.860030 IP 172.18.0.2 > 172.18.0.3: ICMP echo request, id 1310, seq 1, length 64
05:53:10.860050 IP 172.18.0.3 > 172.18.0.2: ICMP echo reply, id 1310, seq 1, length 64
05:53:11.878348 IP 172.18.0.2 > 172.18.0.3: ICMP echo request, id 1310, seq 2, length 64
05:53:11.878365 IP 172.18.0.3 > 172.18.0.2: ICMP echo reply, id 1310, seq 2, length 64
05:53:12.901334 IP 172.18.0.2 > 172.18.0.3: ICMP echo request, id 1310, seq 3, length 64
05:53:12.901350 IP 172.18.0.3 > 172.18.0.2: ICMP echo reply, id 1310, seq 3, length 64
05:53:16.006471 ARP, Request who-has 172.18.0.2 tell 172.18.0.3, length 28
05:53:16.006498 ARP, Reply 172.18.0.2 is-at c2:23:fe:ac:f5:4e, length 28
可以看到,先是 172.18.0.2 发起的 ARP 请求,询问 172.18.0.3 的 MAC 地址,然后是 ICMP 的请求和响应,最后是 172.18.0.3 的 ARP 请求。因为接在同一个 bridge br0 上,所以是二层互通的局域网。
同样,从容器 docker1 ping 容器 docker0 也是通的:
$ sudo ip netns exec docker1 ping -c 3 172.18.0.2
场景二:从宿主机访问“容器”内网络
在“容器” docker0 内启动服务,监听 80 端口:
$ sudo ip netns exec docker0 nc -lp 80
在宿主机上执行 telnet,可以连接到 docker0 的 80 端口:
$ telnet 172.18.0.2 80
场景三:从“容器”内访问外网
- 配置内核参数,允许 IP forwarding
$ sudo sysctl net.ipv4.conf.all.forwarding=1
- 配置 iptables FORWARD 规则
首先确认 iptables FORWARD 的缺省策略:
$ sudo iptables -L
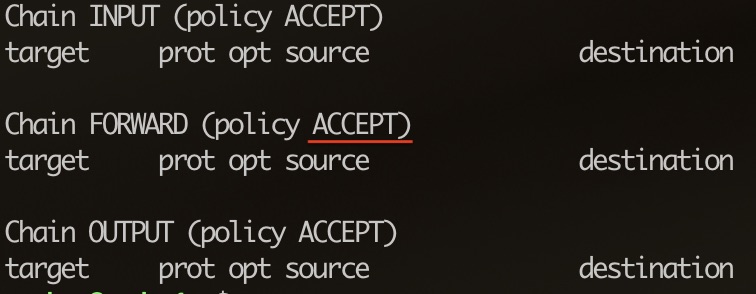
如果缺省策略是 DROP,需要设置为 ACCEPT:
$ sudo iptables -P FORWARD ACCEPT
缺省策略的含义是,在数据包没有匹配到规则时执行的缺省动作。
- 将 bridge 设置为“容器”的缺省网关
$ sudo ip netns exec docker0 route add default gw 172.18.0.1 veth0
$ sudo ip netns exec docker1 route add default gw 172.18.0.1 veth2
查看“容器”内的路由表:
$ sudo ip netns exec docker0 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.18.0.1 0.0.0.0 UG 0 0 0 veth0
172.18.0.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
可以看出,“容器”内的缺省 Gateway 是 bridge 的 IP 地址,非 172.18.0.0/24 网段的数据包会路由给 bridge。
- 配置 iptables 的 SNAT 规则
容器的 IP 地址外部并不认识,如果它要访问外网,需要在数据包离开前将源地址替换为宿主机的 IP,这样外部主机才能用宿主机的 IP 作为目的地址发回响应。
另外一个需要注意的问题,内核 netfilter 会追踪记录连接,我们在增加了 SNAT 规则时,系统会自动增加一个隐式的反向规则,这样返回的包会自动将宿主机的 IP 替换为容器 IP。
$ sudo iptables -t nat -A POSTROUTING -s 172.18.0.0/24 ! -o br0 -j MASQUERADE
上面的命令的含义是:在 nat 表的 POSTROUTING 链增加规则,当数据包的源地址为 172.18.0.0/24 网段,出口设备不是 br0 时,就执行 MASQUERADE 动作。
MASQUERADE 也是一种源地址转换动作,它会动态选择宿主机的一个 IP 做源地址转换,而 SNAT 动作必须在命令中指定固定的 IP 地址。
- 从“容器”内访问外部地址
$ sudo ip netns exec docker0 ping -c 3 123.125.115.110
$ sudo ip netns exec docker1 ping -c 3 123.125.115.110
我们确认在“容器”内是可以访问外部网络的。
场景四:从外部访问“容器”内暴露的服务
- 配置 iptables 的 DNAT 规则
当外部通过宿主机的 IP 和端口访问容器内启动的服务时,在数据包进入 PREROUTING 阶段就要进行目的地址转换,将宿主机 IP 转换为容器 IP。同样,系统会为我们自动增加一个隐式的反向规则,数据包在离开宿主机时自动做反向转换。
$ sudo iptables -t nat -A PREROUTING ! -i br0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.18.0.2:80
上面命令的含义是:在 nat 表的 PREROUTING 链增加规则,当输入设备不是 br0,目的端口为 80 时,做目的地址转换,将宿主机 IP 替换为容器 IP。
- 从远程访问“容器”内暴露的服务
在“容器”docker0 内启动服务:
$ sudo ip netns exec docker0 nc -lp 80
在和宿主机同一个局域网的远程主机访问宿主机 IP:80
$ telnet 192.168.31.183 80
确认可以访问到容器内启动的服务。
测试环境恢复
删除虚拟网络设备
$ sudo ip link set br0 down
$ sudo brctl delbr br0
$ sudo ip link del veth1
$ sudo ip link del veth3
iptables 和 Namesapce 的配置在机器重启后被清除。
总结
本文我们在介绍了 veth、Linux bridge、iptables 等概念后,亲自动手模拟出了 docker bridge 网络模型,并测试了几种场景的网络互通。实际上 docker network 就是使用了上述技术,帮我们创建和维护网络。通过动手实验,相信你对 docker bridge 网络理解的更加深入。