基于容器的分布式系统设计模式
Oct 3, 2019 12:00 · 8756 words · 18 minute read

原论文:https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45406.pdf
1 介绍
在80年代末90年代初,面向对象编程革新了软件开发,推广了模块化地构建应用程序的方法。当下随着组件容器化的微服务架构日益流行,我们在分布式系统开发中见证了类似的变革。天然隔离的容器尤其适合作为分布式系统中的基本对象。随着这种架构的成熟,设计模式也就出现了,正如面向对象编程,原因不尽相同——从对象(容器)的角度抽象出底层的代码细节,最终实现各种应用程序和算法通用的高级模式。
这篇论文讲述了我们已知的基于容器分布式系统的三种设计模式:
- 用于容器管理的单例模式
- 用于紧密协作的单节点多容器模式
- 用于分布式算法的多节点模式
这些设计模式包含了最佳实践,能够简化开发,使系统更可靠。
2 分布式系统设计模式
面向对象编程使用多年后,设计模式出现了。这些设计模式归纳了用于解决特定编程问题的方法。它们大大降低了编程这门艺术的门槛,经验不足的程序员更容易写出好的代码,并直接促进了可重复使用的三方库的开发,开发更快速可靠了。
相比面向对象开发,分布式系统工程看起来还停留在80年代早期的水平。MapReduce 模式的成功赋予了广泛的领域和更多的开发者“大数据”编程的能力——建立正确的模式可以极大地提高分布式系统开发的质量、速度和可行性。但是 MapReduce 的成功很大程度上受限于单一的编程语言,Apache 的 Hadoop 生态系统主要由 Java 开发。为分布式系统设计开发一套全面的模式需要一种通用且无视语言的工具来作为系统中的原子单元。
幸运的是最近两年 Linux 容器技术的使用急剧增长。容器与容器镜像正是分布式系统开发所需的抽象单元。目前,容器和容器镜像是实现软件从开发到交付生产的更好更可靠的方法,因此非常受欢迎。容器既封闭,又自包含,还有原子性的部署信号(成功/失败),极大地提高了在云上部署软件的技术水平。但容器不仅仅是更好的部署工具,它们还有着更大的潜力——我们认为容器注定会成为面向对象软件系统中的那个对象,能够推动分布式系统设计模式的研究。下文将解释为什么我们会这么认为,并讲述一些我们已知的设计模式,它们将在未来几年中规范和指导分布式系统的设计。
3 基于容器管理的单容器模式
容器为定义接口提供了类似于对象边界的自然边界。不仅可以通过接口暴露特定的应用程序功能,也通过接口与管理系统挂钩。
传统的容器管理提供的接口极其有限,只有三个动作:run()、pause()、stop()。尽管这些接口挺有用,但是更丰富的接口可以为系统开发者与操作者提供更多的功能。几乎所有的现代编程语言都支持 HTTP 和 JSON,定义一个基于 HTTP 的管理 API 是一件很容易的事,通过容器在特定的节点托管一个 Web 服务器就能实现。
在上行方向容器可以暴露丰富的应用程序信息,包括应用特定的监控与计量指标(QPS、应用程序健康等)、开发者感兴趣的信息(线程、栈、锁、网络数据等等)、组件配置信息和组件日志。例如,Kubernetes、Aurora、Marathon 和其他容器管理系统允许用户通过特定的 HTTP 路由(比如 /health)定义健康检查。
在下行方向,容器接口提供了定义生命周期的天然环境,使编写管理系统控制的组件更容易。例如,集群管理系统通常会给任务绑定优先级,即使系统超载,高优先级的任务也要保证运行。通过强制驱逐正在执行的低优先级任务来实现,直到资源够用再继续作业。最简单的方法就是直接杀掉低优先级任务,但是这就给开发者带来了很多不必要的负担,他们需要在代码中处理任务被杀掉的情况。相反,如果在应用程序和系统管理中定义了正式的生命周期,那么应用程序组件将会更易于管理,遵循规范使得系统开发更简单。例如,Kubernetes 使用 Docker 的“优雅删除”功能,在发送 SIGKILL 信号前,通过 SIGTERM 信号来警告容器它将被终止。这就留给应用程序一定的缓冲时间来结束当前任务,赶紧写盘。扩展这种机制来支持状态序列化和恢复,使得有状态的分布式系统状态管理更加容易。
对于更复杂的生命周期,比如安卓的 Activity 模型,有一堆回调(onCreate()、onStart()、onStop() 等等)和定义何时触发这些回调的状态机制。没有了正式的生命周期的话,很难开发出可靠的安卓应用程序。在基于容器的系统中,应用程序定义的钩子会在容器创建、启动、终结前被触发。另一个“下行” API 的例子是容器可能支持“自我复制”(扩展服务)。
4 单节点多容器协作模式
除了单个容器的接口,我们还看到一些跨容器的设计模式。这些单节点的模式由在单台宿主机上协同作业的共生容器组成。容器管理系统支持将协同调度的多个容器作为一个整体的单元,Kubernetes 中所谓的 Pod 和 Nomad 中所谓的 task groups 就是这种抽象,是实现我们这节所说的模式的前提。
4.1 Sidecar 模式
最常见的多容器部署模式是 Sidecar 模式(抗日剧中经常出现的日本摩托车,旁边会有一个小的挎斗,能让车多坐一个人)。Sidecar 容器扩展并增强了主容器。例如,主容器可能是个 web 服务器,可能与一个负责从本地磁盘收集并发送至集群的存储系统的日志 Sidecar 容器配对。参见图1。另一个常见的例子是用于分发本地磁盘中文件的 web 服务器,Sidecar 容器定期从 git 仓库、内容管理系统等数据源同步。这两种在 Google 都很常见。Sidecar 是可行的因为在同一个宿主机上的容器共享一个本地磁盘数据卷。
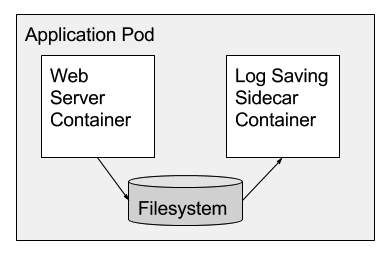
虽然将 Sidecar 容器与主容器合二为一永远可行,但是使用分开的模式有以下几点好处。
- 首先,容器是资源统计与分配的单元,就以 web 服务器容器为例,可以为它多分配些资源来提供高可用低延迟的服务,而日志收集应用的容器则配置成当 web 服务器不那么忙时来占用 CPU 空闲的时钟周期。
- 第二,容器是打包的单元,所以将 web 服务与日志收集分开便于区分它们的开发者甚至是开发团队的职责,既允许单元测试也可以做集成测试。
- 第三,容器是重用的单元,所以 sidecar 可以搭配多种不同的“主”容器(比如日志收集容器可以被任意产生日志的组件使用)。
- 第四,容器提供了遏制故障的边界,使整个系统优雅地降级成为可能(例如 web 服务容器在日志收集容器挂掉后依然能够提供服务)。
- 最后,容器是部署单元,系统的每个组件都允许独立升级,或是当有必要时单独回滚。(但这样也有缺陷——整个系统的测试模型必须考虑到在生产中可能会用到的所有容器版本,可能有很多种组合。当然单一的应用程序没有这个问题,组件化的系统在某种程度上更容易测试,因为它们由更小的可以独立测试的单元组成。)
这五个优点适用于我们论述的所有容器设计模式。
4.2 Ambassador 模式
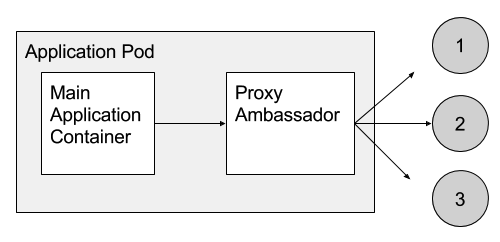
下一个是 Ambassador 模式(外交官模式???)。“外交官”代理了主容器的流量,使得应用程序容器访问服务时不需要使用外网的 IP 地址,只需要用 localhost 访问本地服务。例如,开发者可能需要和 twemproxy 信使匹配使用 memcache 协议的应用程序。这个应用程序自己的视界只是在与本地的 memcache 通信,但实际上 twemproxy 将请求分发至集群中分布的 memcache 节点。这种容器设计模式简化了程序员的工作:
- 开发时只要连接应用程序与 localhost
- 在自己的机器上运行一个 memcache 实例来测试应用程序
- 不同编程语言开发的应用都可以重用“外交官”
Ambassador 模式是可行的因为同一个宿主机上的容器共享相同的网络接口,如图2所示。
4.3 Adapter 模式
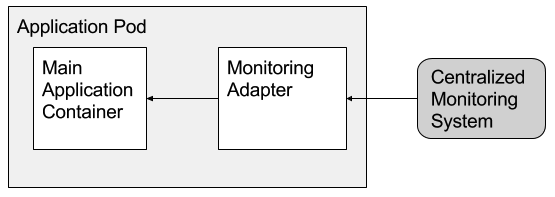
最后是 Adapter 模式。和为应用程序简化了外部呈现的 Ambassador 模式相反,适配器为外部世界简化了应用程序,通过标准化容器之间的输出与接口来实现。适配器模式的一个具体的实践是适配器确保系统中的所有容器都有相同的监控接口。现在的应用程序会使用多种方式来输出它们的计量指标(JMX、statsd 等)。如果所有的应用程序都提供了统一的监控接口,那单个监控工具收集、聚合、计量异构的应用程序集中的监控数据就简单多了。在 Google 内部通过规范代码来实现,但这也只有从 scratch 镜像构建应用才可能做到。Adapter 模式让异构的旧世界和开源程序在不改源码的情况下呈现统一的接口。主容器能够通过 localhost 或共享的本地数据卷与适配器通信。如图3所示。注意尽管某些现有的监控解决方案能够和多种后端通信,但它们在监控系统本身中使用了特定的应用程序代码,从而使得开发者的关注点不太清晰。
5 多节点应用程序模式
除了单节点多容器协作,模块化的容器还使构建在多节点协同工作的分布式应用程序变得更容易了。下面讲述三个这种的分布式系统模式。就和上文的那些模式一样,它们也需要系统对 Pod 抽象的支持。
5.1 Leader 选举模式
分布式系统中有个最常见的问题是 leader 选举。同一个组件的多副本常用于负载均衡,副本另一个更复杂的作用就是应用程序需要区分哪个是 leader。如果一个 leader 倒下了,其他副本会迅速取代它。一个系统中可能同时存在多种 leader 选举。现在有很多实现 leader 选举的三方库,但是通常难以理解,而且受限于特定的编程语言。一种可行的方法是通过容器将应用程序与 leader 选举库联系起来。有一组 leader 选举容器,每个都与需要 leader 选举的应用程序的实例一起调度,能够在它们之间进行选举,同时他们也可以在本地主机上提供简洁的 HTTP API 给其他需要 leader 选举功能的应用程序。这些用于 leader 选举的容器只要被构建一次,接口就可以被开发者重用,不管用啥语言都行。这是就是软件工程中所谓的抽象与封装。
5.2 work queue 模式
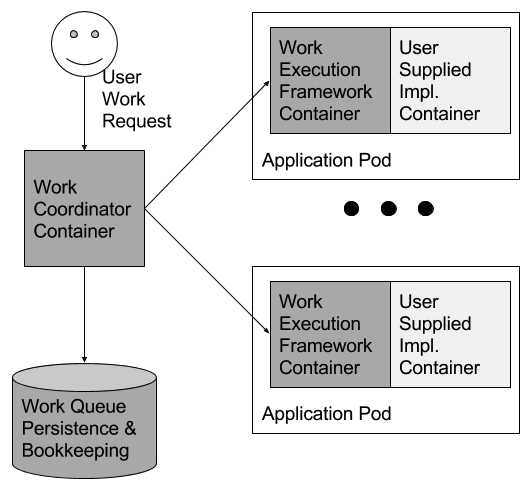
和 leader 选举类似,工作队列是个被广泛研究的课题,也有很多框架已经实现了,它们都是分布式系统中收益于面向对象架构的例子。之前的系统中框架限制了程序的语言环境,或者二进制文件的分发是实现者的课后作业。实现了 run() 和 mount() 接口的容器使构建通用工作队列框架变得非常简单,该框架可以将任意处理代码打包成容器和任意数据,并构建一个完整的工作队列系统。开发者只要创建一个将文件系统中的输入数据文件转换成输出文件的容器;这个容器将成为工作队列中的一环。所有涉及到工作队列开发的其他工作都可以由通用的工作队列框架来处理,该框架可以在需要此类系统时重用。用户代码集成到此共享工作队列框架中的方式如图4所示。
5.3 Scatter/Gather 模式
我们强调最后一种的是 scatter/gather (分散/聚集)模式。在这种系统中,外部客户端向 root 或者 parent 节点发送初始请求。root 将请求分发到大量服务器上执行并行运算。每个分片返回一部分数据,然后再由 root 将这些数据收集起来汇聚成单个应答体。这种模式在搜索引擎中很常见。开发这样的分布式系统涉及非常多的代码层面的工作:将请求分片、聚合返回数据、与客户端交互等等。就像面向对象编程,大部分代码是通用的,可以这样重构:只要提供特定的接口,就可以与任意容器一起使用。尤其,要实现一个 scatter/gather 系统,用户需要提供两样容器:
- 实现叶子节点计算的容器:它们执行部分计算并返回相应的结果。
- 合并容器:这个容器获取所有叶子容器的聚合输出,并将它们组合成单个响应。
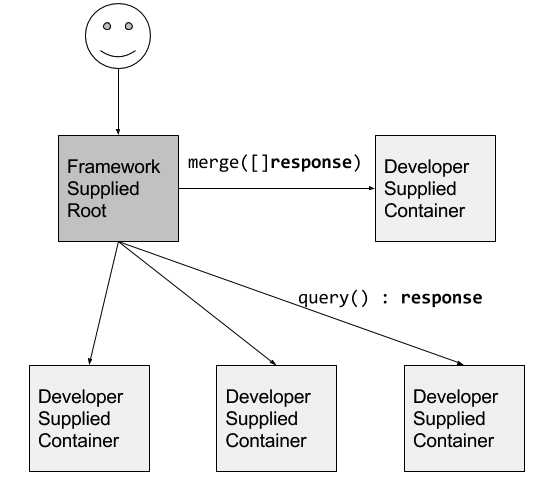
通过提供实现这些相对简单的接口的容器,可以很容易地看出用户如何实现任意深度的分散/聚集系统。
6 相关工作
面向服务的架构(SOA)也提上了日程,并且借鉴了不少基于容器的分布式系统的特征。比如都强调了可重用的组件,通过网络调用定义好的接口通信。另一方面,SOA 系统中的组件趋向于大粒度,相比于我们描述的多容器模式耦合更松。它们常用于实现商业活动,我们这里关注的组件更类似通用库,它们使得构建分布式系统变得更容易。最近出现的“微服务”一词描述了我们在本文中讨论过的组件类型。
标准化管理接口的概念要至少要追溯到 SNMP。SNMP 主要致力于管理硬件组件,而且现在还没有出现管理微服务/基于容器的系统的标准。这还是没能阻止许多容器管理系统的开发,包括 Aurora、ECS、Docker Swarm、Kubernetes、Marathon 和 Nomad。
我们在第5节中提到的分布式算法有着悠久的历史。Github 上就能找到一堆 leader 选举方案,它们看起来更像是三方库而不是独立的组件。工作队列也已经有不少包括 Celery 和 Amazon SQS 在内的实现。Scatter/Gather 则被定义成了一种企业级的整合模式。
7 总结
就像面向对象编程导致了面向对象设计模式的出现和分类一样,容器架构引领着基于容器的分布式系统的设计模式。这篇论文中我们阐述了三种我们已知的模式:
- 单例(容器)模式
- 单节点多容器协作模式
- 多节点模式
以上所有的模式中,容器就像面向对象系统中的对象一样,可以轻松地在多个团队之间实现并在新的项目中重用组件。它们还提供了那些分布式系统独一无二的优点:
- 允许组件被独立地升级
- 混合语言编程
- 可以优雅地降级系统
我们相信容器模式会越来越多,并在未来几年中将彻底改变分布式系统编程,就像过去几十年里的面向对象编程那样。这样就可以实现分布式系统开发的标准化和规范化了。
Design patterns for container-based distributed systems
1 Introduction
In the late 1980s and early 1990s, object-oriented programming revolutionized software development, popularizing the approach of building of applications as collections of modular components. Today we are seeing a similar revolution in distributed system development, with the increasing popularity of microservice architectures built from containerized software components. Containers [15] [22] [1] [2] are particularly well-suited as the fundamental “object” in distributed systems by virtue of the walls they erect at the container boundary. As this architectural style matures, we are seeing the emergence of design patterns, much as we did for object-oriented programs, and for the same reason – thinking in terms of objects (or containers) abstracts away the low-level details of code, eventually revealing higher-level patterns that are common to a variety of applications and algorithms.
This paper describes three types of design patterns that we have observed emerging in container-based distributed systems: single-container patterns for container management, single-node patterns of closely cooperating containers, and multi-node patterns for distributed algorithms. Like object-oriented patterns before them, these patterns for distributed computation encode best practices, simplify development, and make the systems where they are used more reliable.
2 Distributed system design patterns
After object-oriented programming had been used for some years, design patterns emerged and were documented [3]. These patterns codified and regularized general approaches to solving particular common programming problems. This codification further improved the general state of the art in programming because it made it easier for less experienced programmers to produce well-engineered code, and led to the development of reusable libraries that made code more reliable and faster to develop.
The state-of-the-art in distributed system engineering today looks significantly more like the world of early 1980s programming than it does the world of object-oriented development. Yet it’s clear from the success of the MapReduce pattern [4] in bringing the power of “Big Data” programming to a broad set of fields and developers, that putting in place the right set of patterns can dramatically improve the quality, speed, and accessibility of distributed system programming. But even the success of MapReduce is largely limited to a single programming language, insofar as the Apache Hadoop [5] ecosystem is primarily written in and for Java. Developing a truly comprehensive suite of patterns for distributed system design requires a very generic, language-neutral vehicle to represent the atoms of the system.
Thus it is fortunate that the last two years have seen a dramatic rise in adoption of Linux container technology. The container and the container image are exactly the abstractions needed for the development of distributed systems patterns. To date, containers and container images have achieved the large measure of their popularity simply by being a better, more reliable method for delivering software from development all the way through production. By being hermetically sealed, carrying their dependencies with them, and providing an atomic deployment signal (“succeeded”/“failed”), they dramatically improve on the previous state of the art in deploying software in the datacenter or cloud. But containers have the potential to be much more than just a better deployment vehicle – we believe they are destined to become analogous to objects in object-oriented software systems, and as such will enable the development of distributed system design patterns. In the following sections we explain why we believe this to be the case, and describe some patterns that we see emerging to regularize and guide the engineering of distributed systems over the coming years.
3 Single-container management patterns
The container provides a natural boundary for defining an interface, much like the object boundary. Containers can expose not only application-spcefic functionality, but also hooks for management systems, via this interface.
The traditional container management interface is extremely limited. A container effectively exports three verbs: run(), pause(), and stop(). Though this interface is useful, a richer interface can provide even more utility to system developers and operators. And given the ubiquitous support for HTTP web servers in nearly every modern programming language and widespread support for data formats like JSON, it is easy to define an HTTP based management API that can be “implemented” by having the container host a web server at specific endpoints, in addition to its main functionality.
In the “upward” direction the container can expose a rich set of application information, including application-specific monitoring metrics (QPS, application health, etc.), profiling information of interest to developers (threads, stack, lock contention, network message statistics, etc.), component configuration information, and component logs. As a concrete example of this, Kubernetes [6], Aurora [7], Marathon [8], and other container management systems allow users to define health checks via specific HTTP endpoints (e.g. “/health”). Standardized support for other elements of the “upward” API we have described is more rare.
In the “downward” direction, the container interface provides a natural place to define a lifecycle that makes it easier to write software components that are controlled by a management system. For example, a cluster management system will typically assign “priorities” to tasks, with high-priority tasks guaranteed to run even when the cluster is oversubscribed. This guarantee is enforced by evicting already-running lower-priority tasks, that will then have to wait until resources become available. Eviction can be implemented by simply killing the lower-priority task, but this puts an undue burden on the developer to respond to arbitrary death anywhere in their code. If instead, a formal lifecycle is defined between application and management system, then the application components become more manageable, since they conform to a defined contract, and the development of the system becomes easier, since the developer can rely on the contract. For example, Kubernetes uses a “graceful deletion” feature of Docker that warns a container, via the SIGTERM signal, that it is going to be terminated, an application-defined amount of time before it is sent the SIGKILL signal. This allows the application to terminate cleanly by finishing in-flight operations, flushing state to disk, etc. One can imagine extending such a mechanism to provide support for state serialization and recovery that makes state management significantly easier for stateful distributed systems.
4 Single-node, multi-container application patterns
Beyond the interface of a single container, we also see design patterns emerging that span containers. We have previously identified several such patterns [10]. These single-node patterns consist of symbiotic containers that are co-scheduled onto a single host machine. Container management system support for co-scheduling multiple containers as an atomic unit, an abstraction Kubernetes calls “Pods” and Nomad [11] calls “task groups,” is thus a required feature for enabling the patterns we describe in this section.
4.1 Sidecar pattern
The first and most common pattern for multi-container deployments is the sidecar pattern. Sidecars extend and enhance the main container. For example, the main container might be a web server, and it might be paired with a “logsaver” sidecar container that collects the web server’s logs from local disk and streams them to a cluster storage system. Figure 1 shows an example of the sidecar pattern. Another common example is a web server that serves from local disk content that is populated by a sidecar container that periodically synchronizes the content from a git repository, content management system, or other data source. Both of these examples are common at Google. Sidecars are possible because containers on the same machine can share a local disk volume.
While it is always possible to build the functionality of a sidecar container into the main container, there are several benefits to using separate containers. First, the container is the unit of resource accounting and allocation, so for example a web server container’s cgroup [15] can be configured so that it provides consistent low-latency responses to queries, while the log-saver container is configured to scavenge spare CPU cycles when the web server is not busy. Second, the container is the unit of packaging, so separating serving and log saving into different containers makes it easy to divide responsibility for their development between two separate programming teams, and allows them to be tested independently as well as together. Third, the container is the unit of reuse, so sidecar containers can be paired with numerous different “main” containers (e.g. a log saver container could be used with any component that produces logs). Fourth, the container provides a failure containment boundary, making it possible for the overall system to degrade gracefully (for example, the web server can continue serving even if the log saver has failed). Lastly, the container is the unit of deployment, which allows each piece of functionality to be upgraded and, when necessary, rolled back, independently. (Though it should be noted that this last benefit also comes with a downside – the test matrix for the overall system must consider all of the container version combinations that might be seen in production, which can be large since sets of containers generally can’t be upgraded atomically. Of course while a monolithic application doesn’t have this issue, componentized systems are easier to test in some regards, since they are built from smaller units that can be independently tested.) Note that these five benefits apply to all of the container patterns we describe in the remainder of this paper.
4.2 Ambassador pattern
The next pattern that we have observed is the ambassador pattern. Ambassador containers proxy communication to and from a main container. For example, a developer might pair an application that is speaking the memcache protocol with a twemproxy ambassador. The application believes that it is simply talking to a single memcache on localhost, but in reality twemproxy is sharding the requests across a distributed installation of multiple memcache nodes elsewhere in the cluster. This container pattern simplifies the programmer’s life in three ways: they only have to think and program in terms of their application connecting to a single server on localhost, they can test their application standalone by running a real memcache instance on their local machine instead of the ambassador, and they can reuse the twemproxy ambassador with other applications that might even be coded in different languages. Ambassadors are possible because containers on the same machine share the same localhost network interface. An example of this pattern is shown in Figure 2.
4.3 Adapter pattern
The final single-node pattern we have observed is the adapter pattern. In contrast to the ambassador pattern, which presents an application with a simplified view of the outside world, adapters present the outside world with a simplified, homogenized view of an application. They do this by standardizing output and interfaces across multiple containers. A concrete example of the adapter pattern is adapters that ensure all containers in a system have the same monitoring interface. Applications today use a wide variety of methods to export their metrics (e.g. JMX, statsd, etc). But it is easier for a single monitoring tool to collect, aggregate, and present metrics from a heterogenous set of applications if all the applications present a consistent monitoring interface. Within Google, we have achieved this via code convention, but this is only possible if you build your software from scratch. The adapter pattern enables the heterogenous world of legacy and open-source applications to present a uniform interface without requiring modification of the original application. The main container can communicate with the adapter through localhost or a shared local volume. This is shown in Figure 3. Note that while some existing monitoring solutions are able to communicate with multiple types of back-ends, they use applications specific code in the monitoring system itself, which provides a less clean separation of concerns.
5 Multi-node application patterns
Moving beyond cooperating containers on a single machine, modular containers make it easier to build coordinated multi-node distributed applications. We describe three of these distributed system patterns next. Like the patterns in the previous section, these also require system support for the Pod abstraction.
5.1 Leader election pattern
One of the most common problems in distributed systems is leader election (e.g. [20]). While replication is commonly used to share load among multiple identical instances of a component, another, more complex use of replication is in applications that need to distinguish one replica from a set as the “leader.” The other replicas are available to quickly take the place of the leader if it fails. A system may even run multiple leader elections in parallel, for example to determine the leader of each of multiple shards. There are numerous libraries for performing leader election. They are generally complicated to understand and use correctly, and additionally, they are limited by being implemented in a particular programming language. An alternative to linking a leader election library into the application is to use a leader election container. A set of leader-election containers, each one co-scheduled with an instance of the application that requires leader election, can perform election amongst themselves, and they can present a simplified HTTP API over localhost to each application container that requires leader election (e.g. becomeLeader, renewLeadership, etc.). These leader election containers can be built once, by experts in this complicated area, and then the subsequent simplified interface can be re-used by application developers regardless of their choice of implementation language. This represents the best of abstraction and encapsulation in software engineering.
5.2 Work queue pattern
Although work queues, like leader election, are a well-studied subject with many frameworks implementing them, they too are an example of a distributed system pattern that can benefit from container-oriented architectures. In previous systems, the framework limited programs to a single language environment (e.g. Celery for Python [13]), or the distribution of work and binary were exercises left to the implementer (e.g. Condor [21]). The availability of containers that implement the run() and mount() interfaces makes it fairly straightforward to implement a generic work queue framework that can take arbitrary processing code packaged as a container, and arbitrary data, and build a complete work queue system. The developer only has to build a container that can take an input data file on the filesystem, and transform it to an output file; this container would become one stage of the work queue. All of the other work involved in developing a complete work queue can be handled by the generic work queue framework that can be reused whenever such a system is needed. The manner in which a user’s code integrates into this shared work queue framework is illustrated in Figure 4.
5.3 Scatter/gather pattern
The last distributed systems pattern we highlight is scatter/gather. In such a system, an external client sends an initial request to a “root” or “parent” node. This root fans the request out to a large number of servers to perform computations in parallel. Each shard returns partial data, and the root gathers this data into a single response to the original request. This pattern is common in search engines. Developing such a distributed system involves a great deal of boilerplate code: fanning out the requests, gathering the responses, interacting with the client, etc. Much of this code is quite generic, and again, as in object-oriented programming, can be refactored in such a way that a single implementation can be provided that can be used with arbitrary containers so long as they implement a specific interface. In particular, to implement a scatter/gather system, a user is required to supply two containers. First, the container that implements the leaf node computation; this container performs the partial computation and returns the corresponding result. The second container is the merge container; this container takes the aggregated output of all of the leaf containers, and groups them into a single response. It is easy to see how a user can implement a scatter/gather system of arbitrary depth (including parents, in addition to roots, if necessary) simply by providing containers that implement these relatively simple interfaces. Such a system is illustrated in Figure 5.
6 Related work
Service-oriented architectures (SOA) [16] pre-date, and share a number of characteristics with, container-based distributed systems. For example, both emphasize reusable components with well-defined interfaces that communicate over a network. On the other hand, components in SOA systems tend to be larger-grain and more loosely-coupled than the multi-container patterns we have described. Additionally, components in SOA often implement business activities, while the components we have focused on here are more akin to generic libraries that make it easier to build distributed systems. The term “microservice” has recently emerged to describe the types of components we have discussed in this paper.
The concept of standardized management interfaces to networked components dates back at least to SNMP [19]. SNMP focuses primarily on managing hardware components, and no standard has yet emerged for managing microservice/container-based systems. This has not prevented the development of numerous container management systems, including Aurora [7], ECS [17], Docker Swarm [18], Kubernetes [6], Marathon [8], and Nomad [11].
All of the distributed algorithms we mentioned in Section 5 have a long history. One can find a number of leader election implementations in Github, though they appear to be structured as libraries rather than standalone components. There are a number of popular work queue implementations, including Celery [13] and Amazon SQS [14]. Scatter-gather has been identified as an Enterprise Integration Pattern [12].
7 Conclusion
Much as object-oriented programming led to the emergence and codification of object-oriented “design patterns,” we see container architectures leading to design patterns for container-based distributed systems. In this paper we identified three types of patterns we have seen emerging: single-container patterns for system management, single-node patterns of closely-cooperating containers, and multi-node patterns for distributed algorithms. In all cases, containers provide many of the same benefits as objects in object-oriented systems, such as making it easy to divide implementation among multiple teams and to reuse components in new contexts. In addition, they provide some benefits unique to distributed systems, such as enabling components to be upgraded independently, to be written in a mixture of languages, and for the system a whole to degrade gracefully. We believe that the set of container patterns will only grow, and that in the coming years they will revolutionize distributed systems programming much as object-oriented programming did in earlier decades, in this case by enabling a standardization and regularization of distributed system development.
8 Acknowledgements
Ideas don’t simply appear in our heads from a vaccum. The work in this paper has been influenced heavily by conversations with Brian Grant, Tim Hockin, Joe Beda and Craig McLuckie.
References
- Docker Engine http://www.docker.com
- rkt: a security-minded standards-based container engine https://coreos.com/rkt/
- Erich Gamma, John Vlissides, Ralph Johnson, Richard Helm, Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley, Massachusetts, 1994.
- Jeffrey Dean, Sanjay Ghemawat, MapReduce: Simplfied Data Processing on Large Clusters, Sixth Symposium on Operating System Design and Implementation, San Francisco, CA 2004.
- Apache Hadoop, http://hadoop.apache.org
- Kubernetes, http://kubernetes.io
- Apache Aurora, https://aurora.apache.org.
- Marathon: A cluster-wide init and control system for services, https://mesosphere.github.io/marathon/
- Managing the Activity Lifecycle, http://developer.android.com/training/basics/activitylifecycle/index.html
- Brendan Burns, The Distributed System ToolKit: Patterns for Composite Containers, http://blog.kubernetes.io/2015/06/the-distributedsystem-toolkit-patterns.html
- Nomad by Hashicorp, https://www.nomadproject.io/
- Gregor Hohpe, Enterprise Integration Patterns, Addison-Wesley, Massachusetts, 2004.
- Celery: Distributed Task Queue, http://www.celeryproject.org/
- Amazon Simple Queue Service, https://aws.amazon.com/cn/sqs/
- https://www.kernel.org/doc/Documentation/cgroupv1/cgroups.txt
- Service Oriented Architecture, [https://en.wikipedia.org/wiki/Serviceoriented architecture](https://en.wikipedia.org/wiki/Serviceoriented architecture)
- Amazon EC2 Container Service, https://aws.amazon.com/ecs/
- Docker Swarm https://docker.com/swarm
- J. Case, M. Fedor, M. Schoffstall, J. Davin, A Simple Network Management Protocol (SNMP), [https://www.ietf.org/rfc/rfc1157.txt, 1990](https://www.ietf.org/rfc/rfc1157.txt, 1990)
- R. G. Gallager, P. A. Humblet, P. M. Spira, A distributed algorithm for minimum-weight spanning trees, ACM Transactions on Programming Languages and Systems, January, 1983.
- M.J. Litzkow, M. Livny, M. W. Mutka, Condor: a hunter of idle workstations, IEEE Distributed Computing Systems, 1988.
- https://linuxcontainers.org/