Dapper 分布式系统追踪基础设施
Feb 10, 2022 22:00 · 5136 words · 11 minute read

来自 Google 于 2010 年发表的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure。
互联网服务通常被实现成复杂且规模巨大的分布式系统。应用程序由一组软件模块构成,它们可能由不同的团队开发,编程语言也可能不同,可以横跨成百上千的机器。在这样的环境中,帮助理解系统行为和定位性能问题的工具非常有价值。
Dapper 是 Google 的分布式系统追踪基础设施,旨在为 Google 的开发者提供更多关于复杂的分布式系统的行为信息。
它的设计目标:
-
low overhead 低开销
追踪系统应该尽可能不影响到运行着的服务的性能。
-
application-level transparency 对应用层透明
程序员没必要知道追踪系统。
-
ubiquitous deployment on a very large scale system 无处不在
监控应该全天候开启,因为通常情况下不正常的系统行为很难重现。
-
tracing data to be available for analysis quickly after it is generated 尽快让追踪数据可被分析使用
能更快地应对生产系统异常。
其他追踪系统:
Dapper 与它们的理念类似。
2 Dapper 的分布式追踪
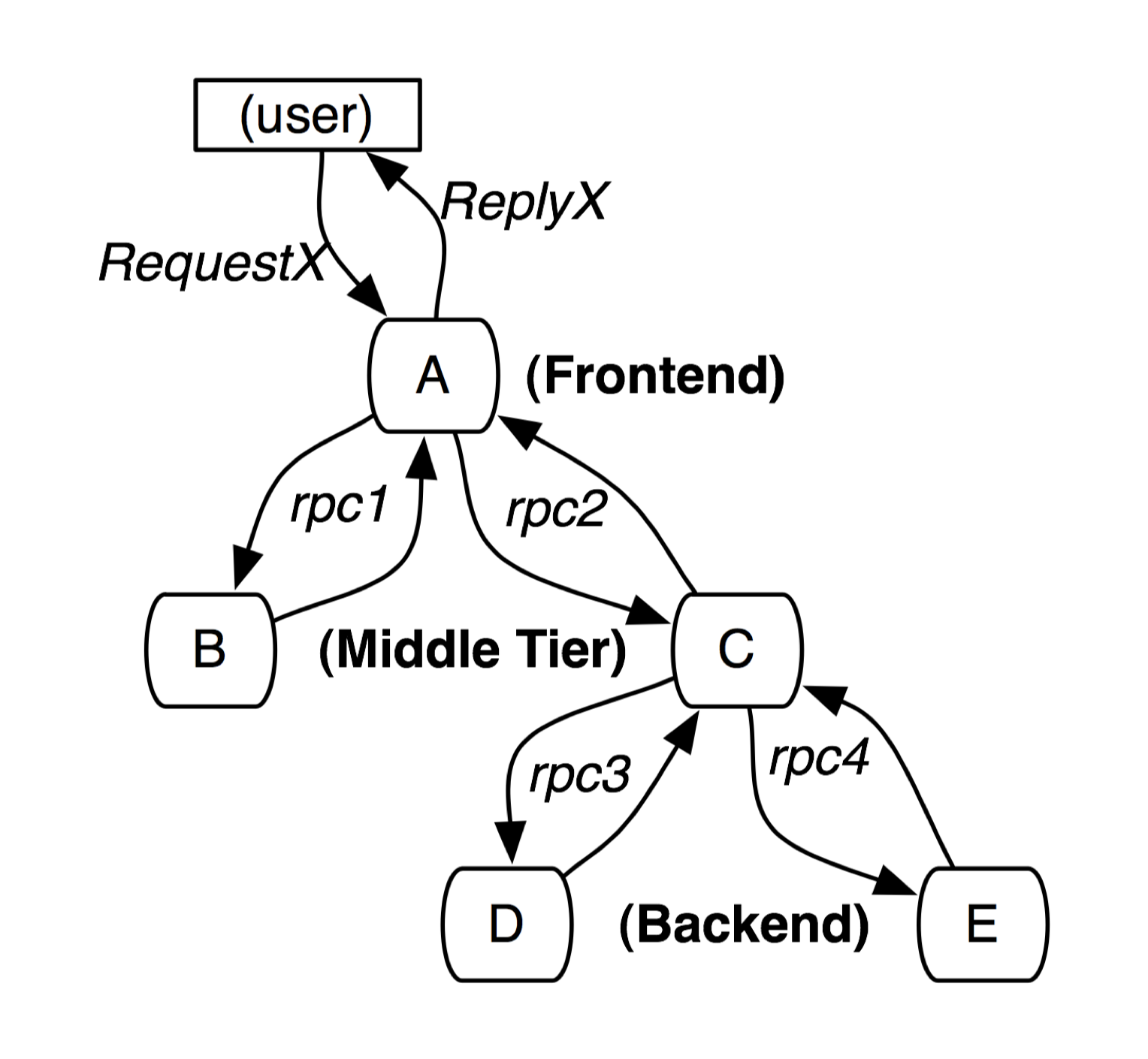
图 1 展示了一个由 5 个服务器构成的服务:
- 一个前端(A)
- 两个中间件(B 和 C)
- 两个后端(D 和 E)
当用户请求到达前端,A 发送两个 RPC 请求到服务器 B 和 C。B 能够立即应答,但是 C 在应答 A 之前则需要后端 D 和 E 的处理。对于这个请求,消息 ID 和所有服务器收发每个消息的带时间戳的事件的集合就是一种简单而有用的分布式追踪。
两种解决方案来汇总这些信息,将所有记录与一个既定的发起者联系起来(图 1 中的 RequestX):
- 黑盒(black-box)
- 基于注释(annotation-based)
黑盒方案比基于注释的方案更轻,但需要更多的数据确保准确性。而基于注释最大的缺陷是需要动程序。 在 Google 的环境中,由于所有的应用程序都使用相同的线程模型、控制流和 RPC 系统,有可能在一小部分通用库中集成,实现一个对开发者透明的监控系统。
追踪这些活动:
- RPC
- SMTP 会话
- HTTP 请求
- SQL 查询
使用树(trees)、跨度(spans)和注解(annotations)对 Dapper 追踪建模。
2.1 追踪树(trees)和跨度(spans)
在 Dapper 追踪树中,node 是基本单位,称之为跨度(span);而 edge 表示跨度(span)和它的父跨度(parent span)之间的关系。
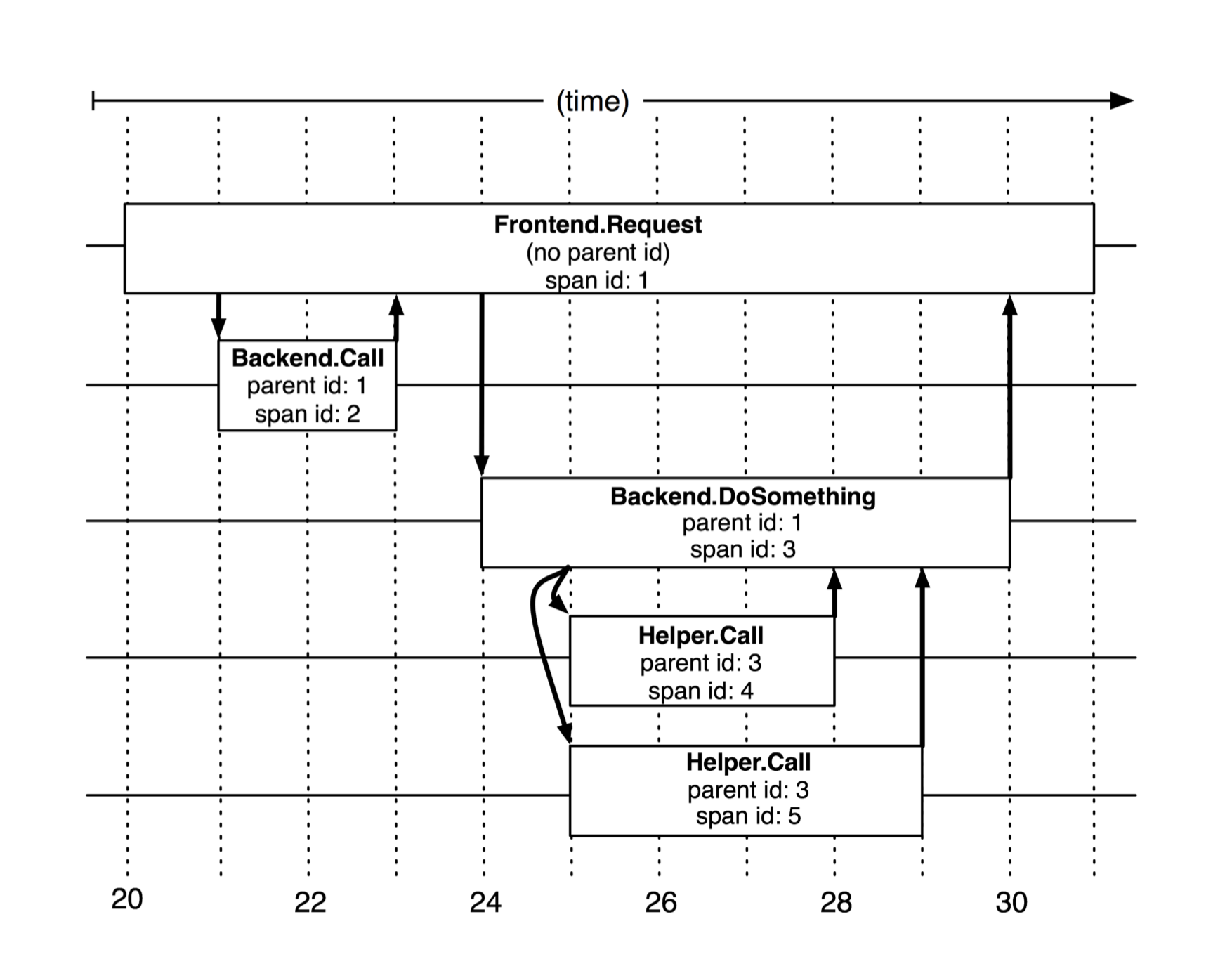
图 2 说明了跨度(span)是如何构成追踪(trace)的。
Dapper 为每个跨度记录一个对用户友好的名字,还有跨度(span)ID 和父跨度(parent span)ID,以便在单个分布式追踪中重建各跨度之间的因果关系。
- 没有父跨度(span)ID 的叫做 root 跨度(span)
- 所有与某个追踪相关的跨度共享一个公用的 trace ID
- 为每个 RPC 找到一个跨度,额外的基础设施层为追踪树增加一层额外的深度
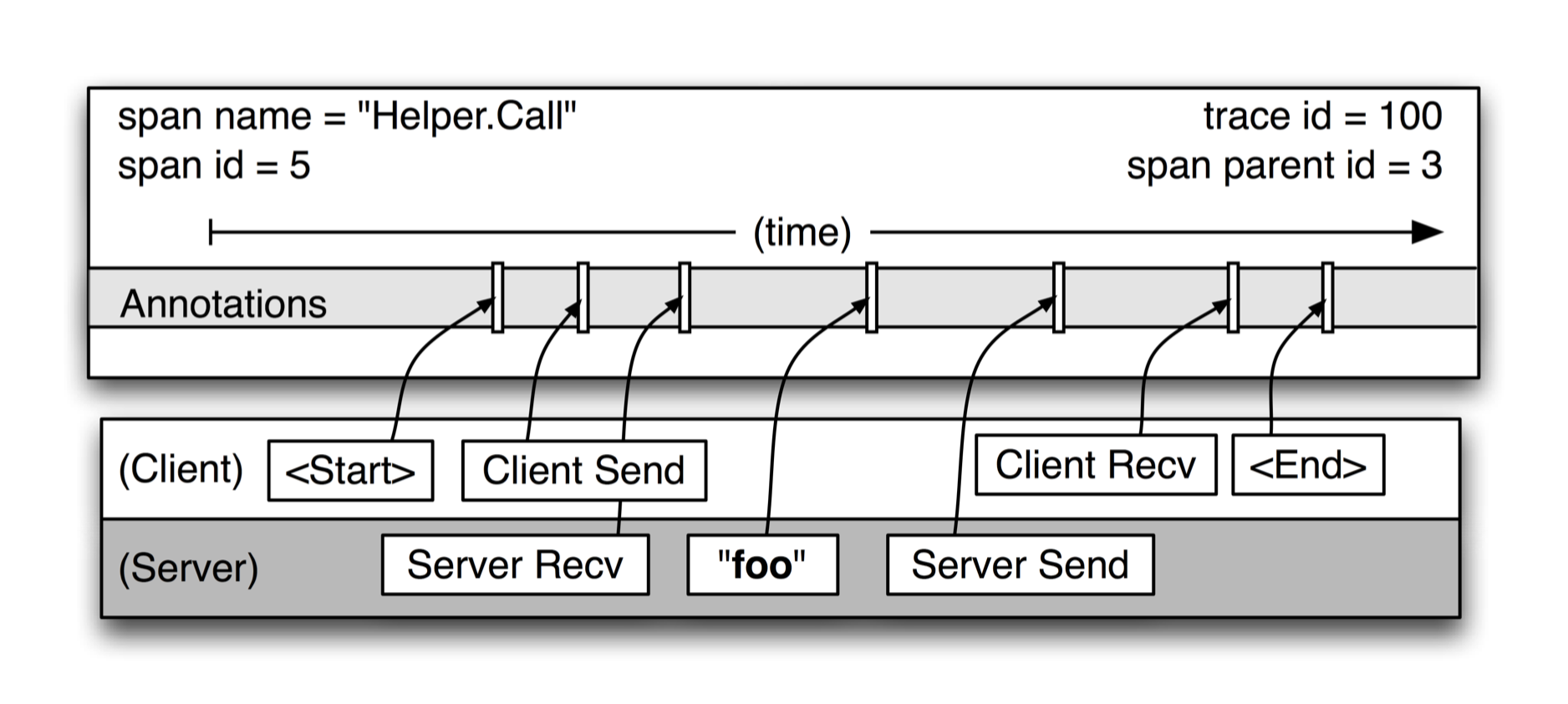
图 3 为 Dapper 追踪跨度中记录的事件
- 跨度描述了图 2 中的两个 Helper.Call RPC
- 记录了起始时间和结束时间
- 还可以记录注解(foo)
因为客户端和服务器的时间不同,必须留心时钟偏差。RPC 客户端发送请求总是在服务器收到请求之前,反之亦然。这样在服务器端有一个跨度(span)时间戳的上下限。
2.2 instrumentation point
Dapper 能够遵循分布式的控制路径,几乎不需要应用程序开发者干预,完全依赖于几个常用库:
- 当线程处理被追踪的控制路径,会附带追踪上下文(trace context),比如跨度 ID。
- 当计算被推迟或异步执行时,使用通用的控制流库(control flow library)来构建回调,确保回调函数包含追踪上下文。
- 几乎所有 Google 内部通信都使用同一个 RPC 框架,他们分析该框架以确定所有 RPC 的跨度(span)。
Dapper 追踪数据与编程语言无关。instrumentation points 足以还原出复杂分布式系统的使用痕迹细节。
2.3 注解
Dapper 允许应用程序开发者通过额外的注解信息来详实追踪,帮助调试。
- 通过 API 定义基于时间的注解
- 支持键值对形式的注解 map
2.4 采样
2.5 追踪集合
Dapper 追踪记录和收集管道分为三阶段:
- 跨度(span)数据被写入本地文件
- 被 Dapper 守护进程拉取并收集
- 最终写入区域的 Dapper Bigtable 仓库
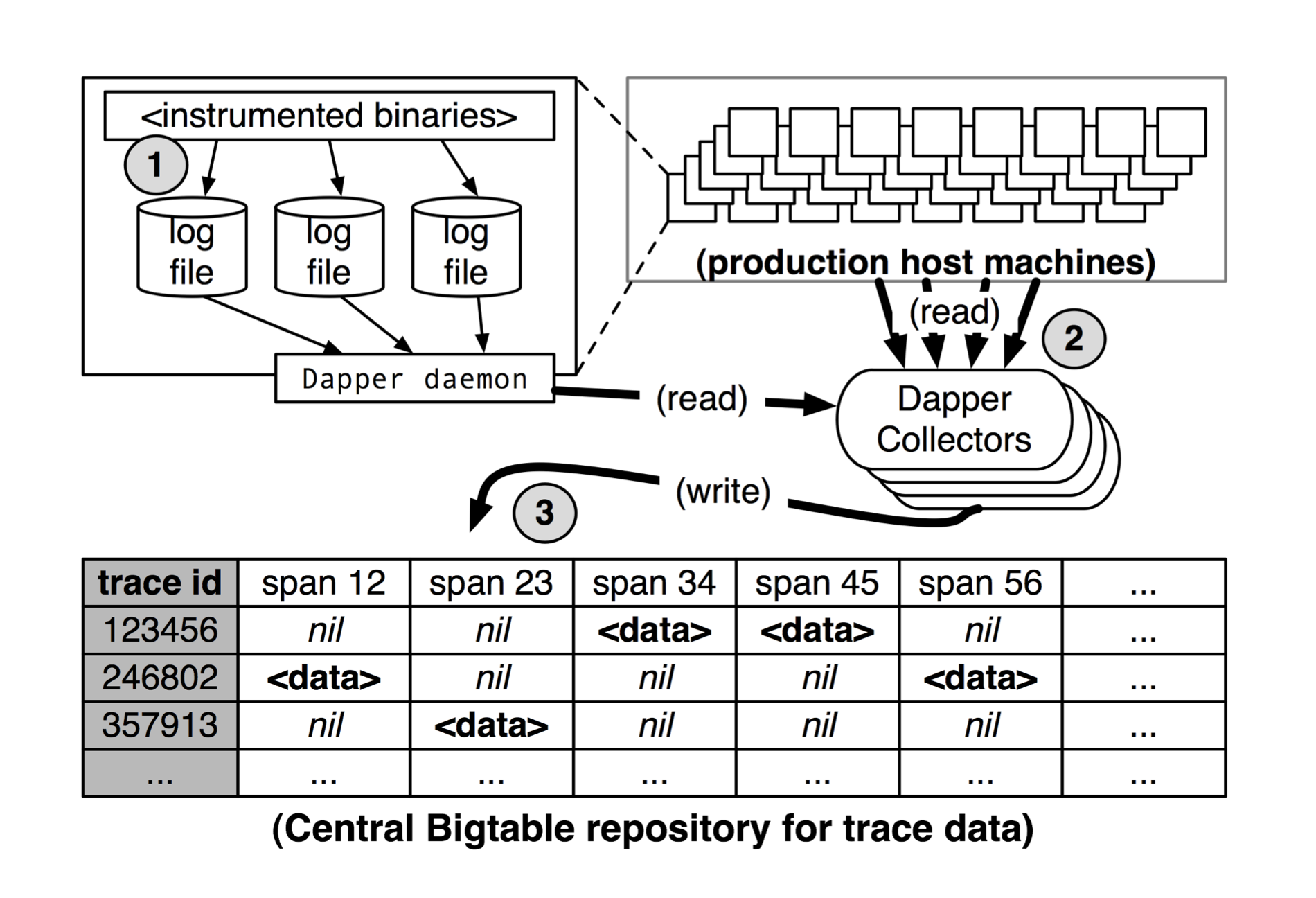
数据从应用程序二进制复制到中央仓库(收集追踪数据)的延迟低于 15 秒。
2.6 安全和隐私考虑
有时候追踪数据包含了不能对未授权的内部用户暴露的信息。Dapper 只存储 RPC 方法名称但不记录任何有效负载数据。开发者通过应用程序级别的注释将其与跨度(span)关联。
3 Dapper 部署状态
3.1 运行时库(runtime library)
Dapper 代码库中最关键的部分是基本 RPC、线程和流控制的工具化,包括创建跨度、采样和记录到本地磁盘。因为它已经被链接到大量应用程序中,维护和错误修复非常困难。
- 轻量
- 稳定
- 健壮
3.2 生产环境覆盖
- 产生 Dapper 追踪的线上进程
- 运行 Dapper 追踪收集 daemon
Dapper daemon 被固化至机器镜像中,Google 的每台虚机上都有。
Dapper 无法正确追踪控制路径的案例:
- 使用了非标准的控制流原语,或者 Dapper 本身错误地无视了因果关系。
- 使用了不支持 Dapper 追踪的通讯库(TCP socket 或 SOAP RPC)
3.3 使用追踪注解
程序员倾向于使用应用程序特定的注解,作为分布式的调试日志或安装应用程序特征对追踪分类。举个栗子,所有 Bigtable 请求都以被访问表的名称作为注解。
4 管理追踪开销
追踪系统的成本表现为被监控系统的性能下降,因为生产和收集追踪的开销,以及存储和分析追踪数据也需要资源。
- 主要的 Dapper 操作
- 追踪收集的开销
- Dapper 对线上负载的影响
- 通过自适应追踪采样机制在开低开销和详尽的追踪之间取的平衡
4.1 生成追踪的开销
生成追踪的开销是 Dapper 性能最关键的部分,因为收集和分析在紧急情况下更容易被关闭。开销来自创建和删除跨度(span)还有注解,以及将它们落盘。创建和删除根跨度(root span)平均要 204 ms,非根跨度同样的操作只需 176 ns。区别在于要为根跨度(root span)分配一个全局唯一的追踪 ID 所产生的额外成本。
如果采样的跨度(span)不用于追踪,额外的跨度注解的开销几乎可以忽略不计,平均 9ns;如果被采样,通过字符转字面量来注解追踪(图 4 所示)花费 40 ns。以上都是在一台 2.2GHz 的 x86 服务器上测量的。
Dapper 运行时库中写本地磁盘是开销最大的操作,通过单次写盘聚合多个日志文件,可见开销大大降低,而且对于被追踪的应用程序来说是异步执行的。但是写日志还是会对高吞吐量的应用程序产生肉眼可见的影响,尤其在所有请求都被追踪时。
4.2 收集追踪的开销
读本地追踪数据也会干扰被监控的工作负载。
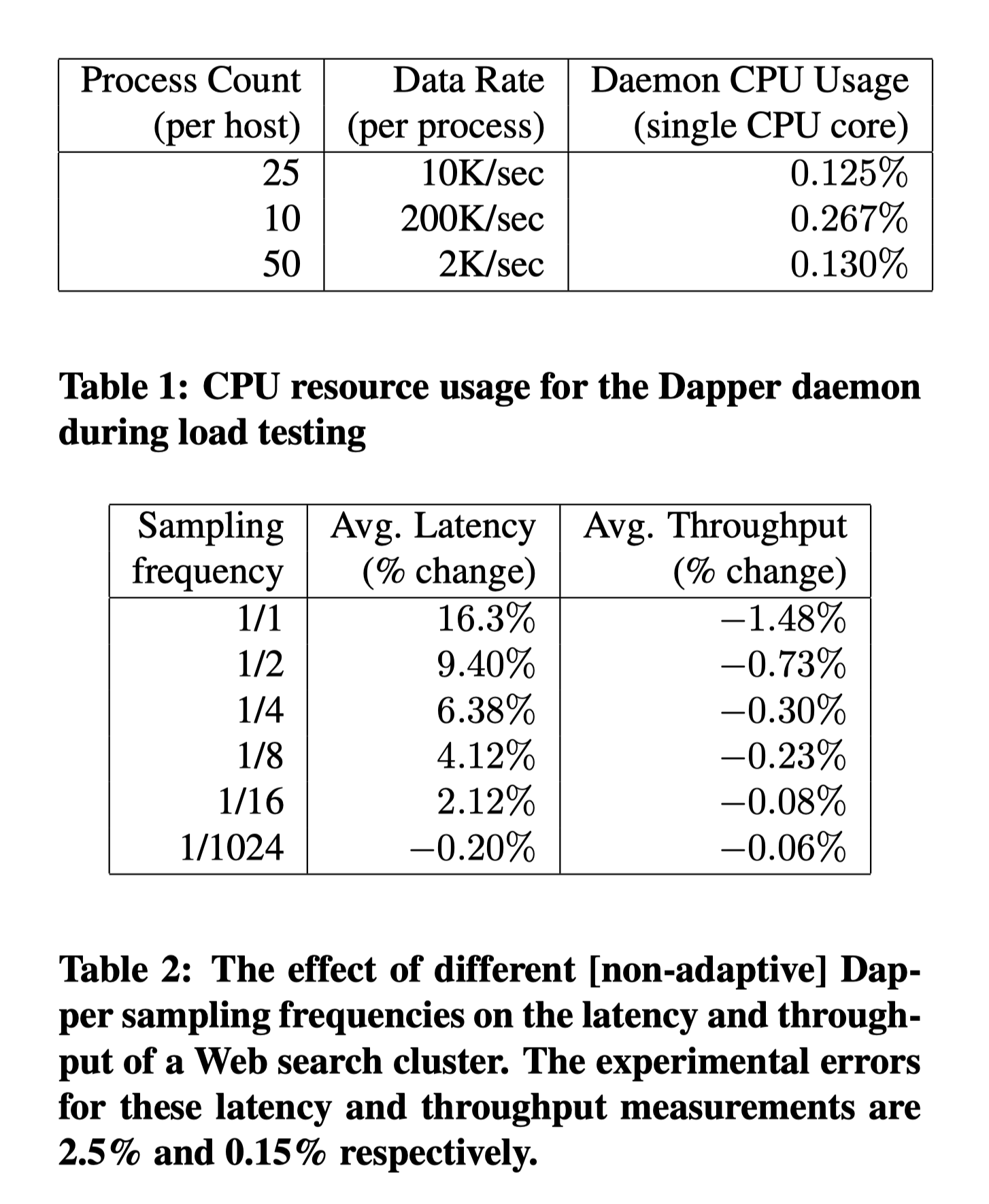
- 表 1 展示了 Dapper daemon 进程基于重度负载基准测试的最坏情况下 CPU 使用率。在收集过程中,daemon 对单核的使用从未使用超过 0.3%,并且内存也非常节省。他们将 Dapper daemon 在内核调度器中的优先级限制得尽可能低,防止抢 CPU。
- Dapper 对网络资源消耗也很低。中央仓库中每个跨度平均只有 426 字节;追踪数据的收集的网络流量在 Google 生产环境中只占不到 0.01%。
4.3 对线上负载的影响
利用海量机器的高吞吐量线上服务会产生大量的追踪数据,而且对性能干扰非常敏感。表 2 中他们使用网络搜索服务集群为例,尽管对吞吐量的影响不大,但为了避免明显的延迟,追踪采样是有必要的。实际上,他们发现使用低至 1/1024 的采样率,对于高容量的服务来说任然有足够的追踪数据。保持 Dapper 基线的低开销可以使得应用程序使用更完整的注解 API 而不用担心性能受到影响。
4.4 自适应采样
进程的 Dapper 开销与采样率成正比。Dapper 的第一个生产版本对所有的进程使用了统一的采样率,1024 来一发。但是低负载在低采样率下可能会错失重要事件。开发自适应采样方案,低流量的工作负载自动提高采样率而大流量负载则会降低采样率,从而控制开销。实际使用的采样率会和追踪本身一起被记录下来,有利于在 Dapper 数据分析工具中准确计算追踪频率。
4.5 激进的采样策略(1/1024)
Goolge 的经验,对于高吞吐量服务,超低的采样率并不会妨碍到大多数重要分析。如果一个值得注意的执行模式在这样的系统中出现了一次,那它会成千上万次重现。流量较低的服务就不能这么搞。
4.6 采集过程中的额外采样
Dapper 也要控制写入中央仓库的数据量,为此加入第二轮采样。
当时 Google 的生产集群每天产生超过 1TB 的追踪数据。Dapper 用户希望追踪数据能至少保留两周。必须权衡增加追踪数据密度的收益与机器和磁盘的成本,而且高采样率也会使得 Dapper 收集器对Dapper Bigtable 仓库的吞吐量造成压力。
尽管追踪在成千上万台机器上铺开,共享同一个追踪 ID。对于收集系统中的每个跨度(span),他们把追踪 ID 哈希成一个标量 z,0 ≤ z ≤ 1。如果 z 小于收集采样系数,跨度被保留并写入 Bigtable,反之丢弃。将这个系数作为配置参数,通过改变参数来调节整体写入率。
因为快速调整已经部署的二进制的配置是不可能的,Google 选择使用两个参数:
- 运行时采样率,使得运行时产生的数据比最终写入到仓库的略多
- 收集系统的二次采样系数,修改它来全局控制写入率
5 通用 Dapper 工具
5.1 Dapper Depot API
通过 Depot API(DAPI)直接访问区域 Dapper 仓库中的分布式追踪记录。
三种访问方式:
- 追踪 ID 访问:通过全局唯一的追踪 ID
- 批量访问:利用 MapReduce 并行访问数十亿追踪
- 索引访问:Dapper 仓库支持单一索引
选择自定义索引是 DAPI 设计中最具挑战的部分。追踪数据索引的体积仅比实际数据本身少 26%,代价非常大。一开始他们实现了两种 indice:宿主机名称一条索引;服务名称一条索引,但是基于机器的 indice 的使用率并不足以抵消它的存储成本,所以最终他们将两者合并到一个复合索引中,这样不论根据服务名称还是机器名称都能高效查询。
DAPI 在 Google 内部的使用:
- 持久的在线 web app
- 基于 DAPI 的命令行工具
- 一次性分析工具
5.2 Dapper UI
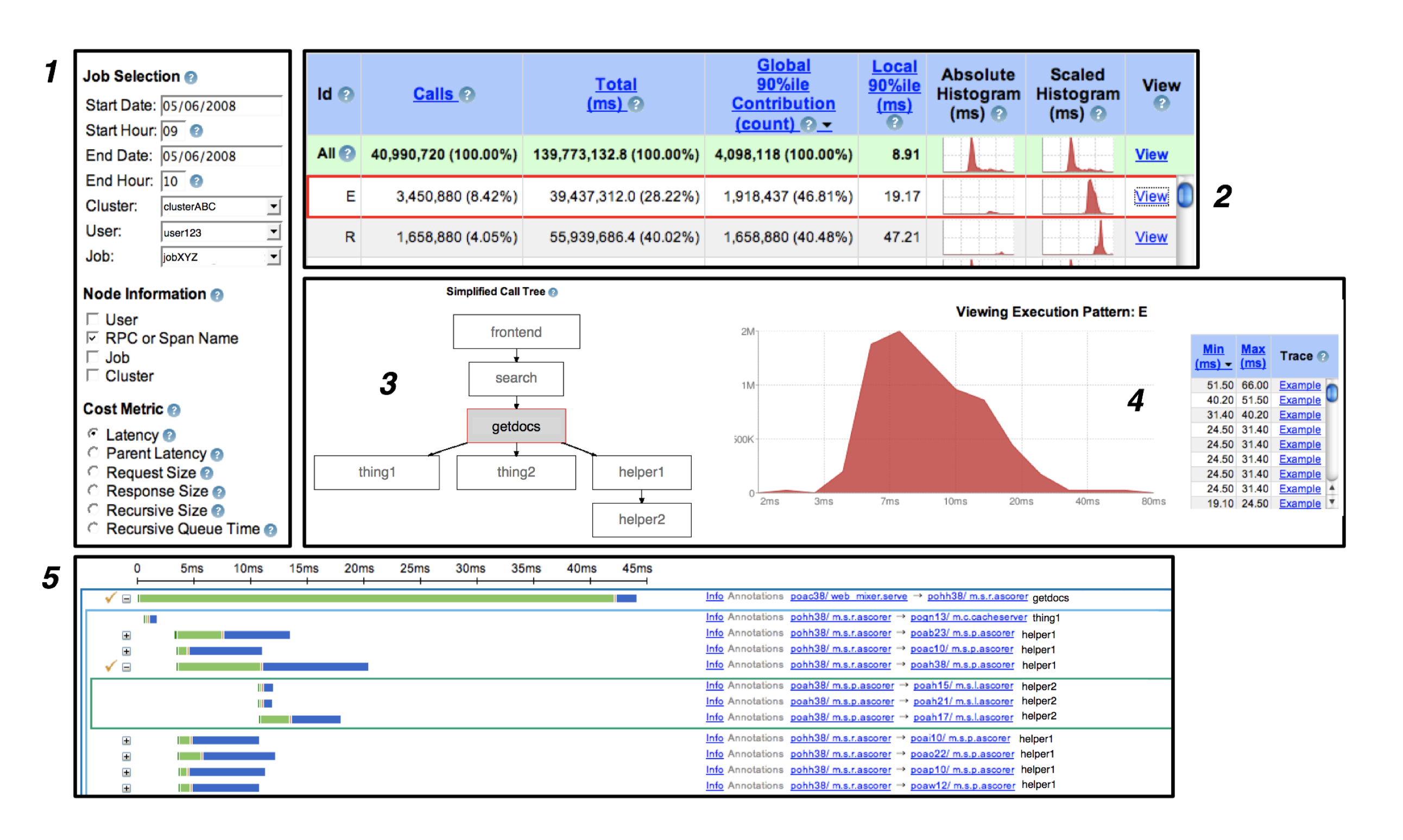
基于 web 的交互式 UI。
- 用户描述想要查看的服务和时间窗口、跨度(span)名称,指定一个计量方面的关键字(比如服务延迟)
- 给定服务相关的所有分布式性能摘要汇总至一张表,用户对执行模式分类并选择以查看详情
- 选中一个分布式执行模式,用户就会看到上述执行模式的图表
- 呈现直方图
- Dapper 有全局时间线,能够交互式地扩展折叠子树
- Dapper UI 还能够直接与每个生产机器上的 Dapper daemon 通信,查看实时数据
6 经验
6.1 部署时使用 Dapper
Google AdWords 系统
- 性能:追踪请求延迟,指出容易优化的点。Dapper 还被用于识别关键路径上不必要的串行请求。
- 正确性:广告审查业务后面有一个大型数据库,该系统有可读写的主节点和只读的从节点。Dapper 被用于识别查询被错误地发送到主节点而非从节点的情况(主节点的访问成本较昂贵)。
- 理解:广告审查系统的查询扇出至包括 Bigtable、数据库、多维索引服务。Dapper 追踪被用于凭据查询成本,鞭策开发者优化设计,降低对其依赖服务造成的负载。
- 测试:新代码的发布要经过 Dapper QA,来验证系统行为和性能没问题。
总的来说,广告审核团队估计,它们的延迟通过 Dapper 追踪平台优化后降低了两个数量级。
6.2 解决长尾延迟问题
由于组件数量以及代码库和部署的规模,调试像通用搜索这样的服务是非常困难的。Dapper 能够验证关于端到端延迟的假设,具体来说是通用搜索请求的关键路径。当系统涉及不只几十个子系统还有几十个工程团队时,最好的工程师也会猜错导致性能问题的原因。在这种情况下 Dapper 可以提供雪中送炭的事实。
通过 Dapper 导致了以下发现:
- 关键路径的网络性能瞬间下降当时并不会影响系统的吞吐量,但会对异常延迟产生深远的影响。
- 有诸多问题和昂贵的查询由服务之间的非预期互动造成。一旦被识别出来,往往很容易纠正。
- 从 Dapper 之外的安全日志仓库中获取普通查询,并使用 Dapper 的唯一追踪 ID,与 Dapper 仓库连接。这种映射被用于建立示例查询列表,这些查询对通用搜素中的每个独立的子系统来说都很慢。
6.3 推断服务的依赖关系
任意时候 Google 一个典型的计算集群都承载着数以千计的逻辑“作业”:即执行共同函数的进程组。事实上他们发现一个计算集群中的工作经常依赖于其他集群的工作结果。由于工作直接的依赖关系是动态变化的,因此仅通过配置信息来推断所有服务之间的依赖关系是不可能的。Google 的 Service Dependencies 项目恰如其分地利用了追踪注解和 DAPI MapReduce 接口,实现自动化推断服务依赖关系。
6.4 不同服务的网络使用情况
虽然 Dapper 并非为链路级监控而设计,但是它非常适用于集群间网络活动的应用级分析任务。Google 利用 Dapper 平台建立了一个持续更新的控制台,展示集群间网络流量最活跃的应用级断点。甚至使用 Dapper 可以指出昂贵的网络请求的前世今生。
6.5 分层和共享的存储系统
Google 的许多存储系统是由多个复杂的分布式基础设施层构成的。例如 Google App Engine 是在一个可扩展的实体存储系统上建立的。这个实体存储系统在底层的 Bigtable 之上暴露了特定的 RDBMS 功能。而 Bigtable 又使用了 Chubby(一个分布式锁系统)和 GFS(高富帅)。此外为了简化部署和更好地利用计算资源,像 Bigtable 这样的系统被作为一个共享服务来管理。
在这样的分层系统中,要确定最终用户的资源消耗模式并不容易。比如来自某个 Bigtable 单元的大量 GFS 流量可能主要来源于某个用户。没有 Dapper 这样的工具,对共享服务的争夺也同样难以调试。
6.6 通过 Dapper 救火
Dapper 很有用但也不是包治百病,这里是指处于火炕中的分布式系统。通常救火的 Dapper 用户需要访问最新的数据,没时间来编写新的 DAPI 代码或等待定期报告。对于正处于异常状态的服务,通过与 Dapper daemon 直接通信来收集特定的新数据。但是对于需要汇总足够的追踪信息来生成分析报告的情景,Dapper 就没那么有效了。