CAP 定理
Dec 30, 2021 22:00 · 2259 words · 5 minute read

译文
在今天的技术领域,我们正在见证当需要额外的资源在合理的时间窗口内成功完成工作负载时,人们对扩展系统的欲望愈加强烈。通过向系统添加额外的商业硬件来应对增长的负载,而这种扩展策略也会带来惩罚性的后果,系统会变的越来越复杂。这就是 CAP 定理发挥作用的地方。
CAP 定理指出,在一个分布式系统(互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。然而,正如下所示,并没有想象中的那么多选择。
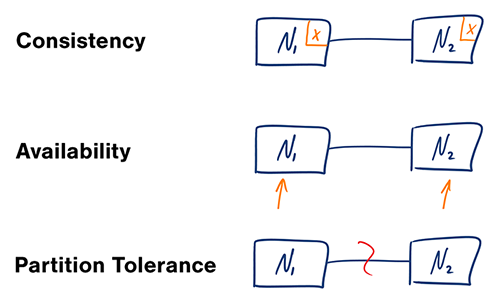
与第一版定义相比,第二版定义强调了互联(interconnected)和共享数据(share data),因为分布式系统不一定互联并共享数据;第二版还强调了读写(write/read pair),CAP 关注的是对数据的读写操作,而不是分布式系统的所有功能。
-
一致性(Consistency)
- 第一版:所有节点在同一时刻都能看到相同的数据。
- 第二版:对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
第一版从节点角度描述而第二版从客户端角度描述。
-
可用性(Availability)
- 第一版:每个请求都能得到成功或失败的响应
- 第二版:非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
第二版的解释明确了不能超时、不能出错,结果是合理的(可以不正确)。
-
分区容错性(Partition Tolerance)
- 第一版:出现消息丢失或者分区错误时系统能够继续运行
- 第二版:出现网络分区错误系统能够继续运行
消息丢失只是一种网络分区原因,连接中断和网络拥塞也有可能导致网络分区。
我们要弄清楚一件事,面向对象编程不等于网络编程!在构建共享内存的应用程序时,有些假设是我们想当然的,一旦节点在空间和时间上分隔,这些假设就不成立了。
分布式计算的谬论之一:网络是可靠的。实际上并不是,网络经常会出人意料地发生故障,你也没法选择何时发生故障。
鉴于网络并不完全可靠,你就必须容忍分布式系统中的分区(P)。不过幸运的是,你可以选择在分区发生时如何应对。根据 CAP 定理,意味着我们只剩下两个选择:一致性(C)和可用性(A)。
-
CP —— 一致性/分区容错性
等待分区节点的应答可能导致超时错误。系统也可以选择直接返回一个错误,取决于你所想要的场景。当你的业务需要原子读写,那就选择一致性而不是可用性。
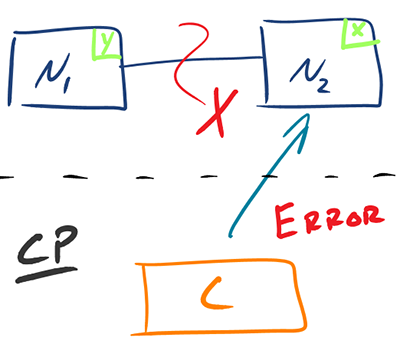
当发生分区现象后,N1 节点上的数据已经更新成 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,此时 N2 节点上的数据还是原来的 x。这时客户端 C 访问 N2 时,N2 需要返回错误(N2 无从得知 N1 那边数据已被更新,所以错误也只能是当前系统出现了故障)。这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
-
AP —— 可用性/分区容错性
返回你有的数据的最新版本,有可能还是老的。这个系统在分区问题解决后也会接受写数据。当你的业务需要系统中的数据同步时有一定的灵活度,那就选择可用性而不是一致性。当系统要在外部错误的情况下继续运行,可用性也是必选的。
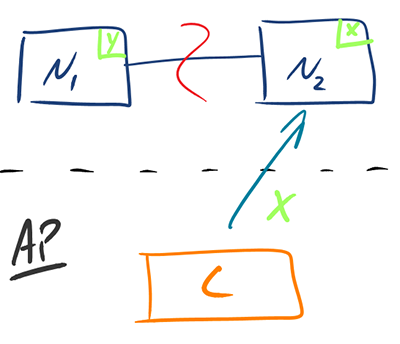
当发生分区现象后,N1 节点上的数据已经更新成 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,此时 N2 节点上的数据还是原来的 x。这时客户端 C 访问 N2,N2 直接将当前自己拥有的数据 x 返回给客户端 C 了,实际上最新的数据已经是 y 了。这种处理方式违背了一致性(Consistency)的要求,因此 CAP 三者只能满足 AP。
注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只不过不是最新的数据而已。
一致性与可用性之间的选择是一种权衡。你可以决定如何应对分区——控制权在你手里。网络故障,或大或小,不取决于人的意志,随时都有可能发生——存在于软件之外。
构建分布式系统提供了诸多优点,但也增加了复杂度。在面对网络错误时选择正确的路,对你的应用程序至关重要。如果不能一开始就解决好这个问题,那就会注定失败。
原文
Note: Close to two months ago, I wrote a blog post explaining the CAP Theorem. Since publishing, I’ve come to realize that my thinking on the subject was quite outdated and is no longer applicable to the real world. I’ve attempted to make up for that in this post.
In today’s technical landscape, we are witnessing a strong and increasing desire to scale systems out when additional resources (compute, storage, etc.) are needed to successfully complete workloads in a reasonable time frame. This is accomplished through adding additional commodity hardware to a system to handle the increased load. As a result of this scaling strategy, an additional penalty of complexity is incurred in the system. This is where the CAP theorem comes into play.
The CAP Theorem states that, in a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed. However, as you will see below, you don’t have as many options here as you might think.
- Consistency - A read is guaranteed to return the most recent write for a given client.
- Availability - A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
- Partition Tolerance - The system will continue to function when network partitions occur.
Before moving further, we need to set one thing straight. Object Oriented Programming != Network Programming! There are assumptions that we take for granted when building applications that share memory, which break down as soon as nodes are split across space and time.
One such fallacy of distributed computing is that networks are reliable. They aren’t. Networks and parts of networks go down frequently and unexpectedly. Network failures happen to your system and you don’t get to choose when they occur.
Given that networks aren’t completely reliable, you must tolerate partitions in a distributed system, period. Fortunately, though, you get to choose what to do when a partition does occur. According to the CAP theorem, this means we are left with two options: Consistency and Availability.
- CP - Consistency/Partition Tolerance - Wait for a response from the partitioned node which could result in a timeout error. The system can also choose to return an error, depending on the scenario you desire. Choose Consistency over Availability when your business requirements dictate atomic reads and writes.
- AP - Availability/Partition Tolerance - Return the most recent version of the data you have, which could be stale. This system state will also accept writes that can be processed later when the partition is resolved. Choose Availability over Consistency when your business requirements allow for some flexibility around when the data in the system synchronizes. Availability is also a compelling option when the system needs to continue to function in spite of external errors (shopping carts, etc.)
The decision between Consistency and Availability is a software trade off. You can choose what to do in the face of a network partition - the control is in your hands. Network outages, both temporary and permanent, are a fact of life and occur whether you want them to or not - this exists outside of your software.
Building distributed systems provide many advantages, but also adds complexity. Understanding the trade-offs available to you in the face of network errors, and choosing the right path is vital to the success of your application. Failing to get this right from the beginning could doom your application to failure before your first deployment.