CAP 定理(一)
Oct 10, 2021 21:30 · 2125 words · 5 minute read

译文
Robert Greiner 写了两篇文章来阐述 CAP 理论,本文是第一篇,已经过期。
几年前提升软件系统的性能是很简单的——要么堆硬件(scale up),要么优化程序使其更高效地运行。如今有了第三种选择:横向扩展(scale out)。
近年来由于计算的全球化和对应用程序性能要求的不断提高,横向扩展成为软件系统的必由之路。在很多情况下,在公司总部的机房内用单台服务器运行一个数据库已经难以接受。我们需要真正的分布式环境来应对当今的商业挑战。
很不幸,横向扩展所带来的性能提升是有代价的——复杂度。分布式系统引入了比以往更多的因素:不同地点的客户端/节点之间的数据有所不同;单点故障破坏了系统的正常运行;间歇性的网络问题会在最糟糕的时候悄然出现。
这些跨分布式系统的一致性(C)、可用性(A)和分区容错性(P)构成了 Eric Brewer 提出的 CAP 定理。简单地说,CAP 定理表明任何分布式系统都不能同时满足 C(一致性),A(可用性)和 P(分区容错性)三个设计约束,必须权衡以达到用户需求的性能和可用性。
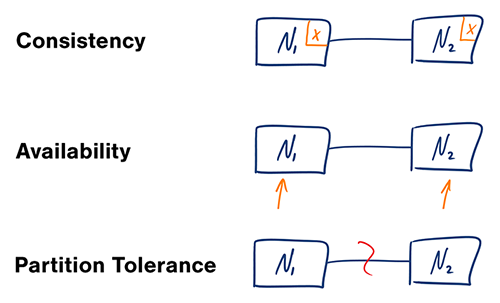
[C] 一致性 - 所有节点在同一时刻都能看到相同的数据
简单来说,执行一个读操作将返回最近一次写操作的值,所有节点都应该返回相同的值。如果一个事务开始时系统就处于一致的状态,那么结束时系统的状态也是一致的。在这个模型中,系统可以(而且实际上也是)在事务过程中转变为不一致的状态,但是在这个过程中的任意阶段出现错误整个事务都会回滚。
通常关系型数据库都是一致的:SQL Server、MySQL 和 PostgreSQL
[A] 可用性 - 每个请求都能得到成功或失败的响应
在分布式系统中实现可用性需要系统无时无刻不在运行。无论系统中任一节点的状态如何,每个客户端都能得到应答。这个指标很容易衡量:要么你可以提交读/写命令,要么不行。
通常关系型数据库也是可用的:SQL Server、MySQL 和 PostgreSQL。这就意味着关系型数据库存在于 CA 象限——一致性和可用性(当发生分区时,为了保证 C,系统要被禁止写入)。但是 CA 不仅仅是只为关系型数据库保留的,ElasticSearch 也属于 CA 的范畴。
[P] 分区容错性 - 出现消息丢失或者分区错误时系统能够继续运行
大多数人认为他们的数据存储是网络中的单点。“这是我们生产的 SQL Server 实例”。任何一个运行生产实例几分钟的人,都会很快意识到这创造了单一的故障点。一个分区容错的系统可以承受任何程度不会导致整个网络瘫痪的网络故障。数据在不同的节点和网络的组合中被充分地复制,以保证系统在间歇性的故障中持续运行。
属于 CP(一致性 & 分区容错性)象限的存储系统:MongoDB、Redis、AppFabric Caching 和 MemcacheDB。CP 系统可用作出色的分布式缓存,因为每个客户端都获得相同的数据,而且系统是跨网络边界分区的。
属于 AP(可用性 & 分区容错性)象限的存储系统包括 DynamoDB、CouchDB 和 Cassandra。
结论
分布式系统使得我们能够达到过去无法想象的计算能力和可用性。我们的系统有更高的性能、更低的延迟以及在遍布全球的数据中心里无时不刻不正常运行。最棒的是,如今的系统都是在商业硬件上运行的,很容易就可以买到和配置。
然而,所有这些算力和好处都是有代价的,分布式系统更复杂。要创建一个真正可扩展的高性能系统,需要掌握更多的工具和技能,权衡利弊(CAP),这些都是在计算系统向外发展而不是向上发展的世界中的关键技能。
原文
Note: This post is outdated. You can find the most up-to-date version here.
This post is outdated. Please find the updated version here. I am intentionally leaving this article here so I do not disrupt other sites linking back to me.
Several years ago, building performance into a software system was simple - you either increased your hardware resources (scale up) or modified your application to run more efficiently (performance tuning). Today, there’s a third option: horizontal scaling (scale out).
Horizontal scaling of software systems has become necessary in recent years, due to the global nature of computing and the ever-increasing performance demands on applications. In many cases, it is no longer acceptable to run a single server with a single database in a single data center adjacent to your company’s headquarters. We need truly distributed environments to tackle the business challenges of today.
Unfortunately, the performance benefits that horizontal scaling provides come at a cost - complexity. Distributed systems introduce many more factors into the performance equation than existed before. Data records vary across clients/nodes in different locations. Single points of failure destroy system up-time, and intermittent network issues creep up at the worst possible time.
These concerns of consistency (C), availability (A), and partition tolerance (P) across distributed systems make up what Eric Brewer coined as the CAP Theorem. Simply put, the CAP theorem demonstrates that any distributed system cannot guaranty C, A, and P simultaneously, rather, trade-offs must be made at a point-in-time to achieve the level of performance and availability required for a specific task.
[C] Consistency - All nodes see the same data at the same time.
Simply put, performing a read operation will return the value of the most recent write operation causing all nodes to return the same data. A system has consistency if a transaction starts with the system in a consistent state, and ends with the system in a consistent state. In this model, a system can (and does) shift into an inconsistent state during a transaction, but the entire transaction gets rolled back if there is an error during any stage in the process.
Typical relational databases are consistent: SQL Server, MySQL, and PostgreSQL.
[A] Availability - Every request gets a response on success/failure.
Achieving availability in a distributed system requires that the system remains operational 100% of the time. Every client gets a response, regardless of the state of any individual node in the system. This metric is trivial to measure: either you can submit read/write commands, or you cannot.
Typical relational databases are also available: SQL Server, MySQL, and PostgreSQL. This means that relational databases exist in the CA space - consistency and availability. However, CA is not only reserved for relational databases - some document-oriented tools like ElasticSearch also fall under the CA umbrella.
[P] Partition Tolerance - System continues to work despite message loss or partial failure.
Most people think of their data store as a single node in the network. “This is our production SQL Server instance”. Anyone who has run a production instance for more than four minutes, quickly realizes that this creates a single point of failure. A system that is partition-tolerant can sustain any amount of network failure that doesn’t result in a failure of the entire network. Data records are sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
Storage systems that fall under Partition Tolerance with Consistency (CP): MongoDB, Redis, AppFabric Caching, and MemcacheDB. CP systems make for excellent distributed caches since every client gets the same data, and the system is partitioned across network boundaries.
Conclusion
Distributed systems allow us to achieve a level of computing power and availability that were simply not available in yesteryears. Our systems have higher performance, lower latency, and near 100% up-time in data centers that span the entire globe. Best of all, the systems of today are run on commodity hardware that is easily obtainable and configurable with costs approaching $0.
All of this computing power and benefit comes at a price, however. Distributed systems are more complex than their single-network counterparts. There are many more tools and skills that need to be acquired in order to create a truly scalable, high performance system. Understanding the complexity incurred in distributed systems, making the appropriate trade-offs for the task at hand (CAP), and selecting the right tool for the job are all critical skills in a world where computing systems are moving out, not up.