BPF(BSD 包过滤器)
Feb 1, 2022 19:00 · 1991 words · 4 minute read

来自伯克利于 1993 年发表的论文 The BSD Packet Filter: A New Architecture for User-level Packet Capture。
用户态抓包,数据包必须从内核复制到用户空间。
通过部署内核代理最小化复制成本,尽早丢掉不想要的包。
性能提升源于两处架构改进:
- register-based 过滤机,可在如今的 RISC CPU 上高效实现(比原先的 stack-based 快 20 倍)
- 非共享缓冲区模型,非常适合抓包这样的用例
分流器
BPF 有两个主要组件:
- 网络分流器(network tap)
- 包过滤器(packet filter)
网络分流器(Network Tap)
从网卡驱动收集数据包的副本,并传递至监听程序。
-
走系统协议栈
当包到了网卡,链路层设备驱动将它发送到系统协议栈。
-
走 BPF(如果 BPF 正在监听网卡)
- 驱动首先调用 BPF。
- BPF 将包喂给用户定义的过滤器程序。
- BPF 将通过筛选的包复制到与过滤器相连接的缓冲区。
- 设备驱动重获控制权。
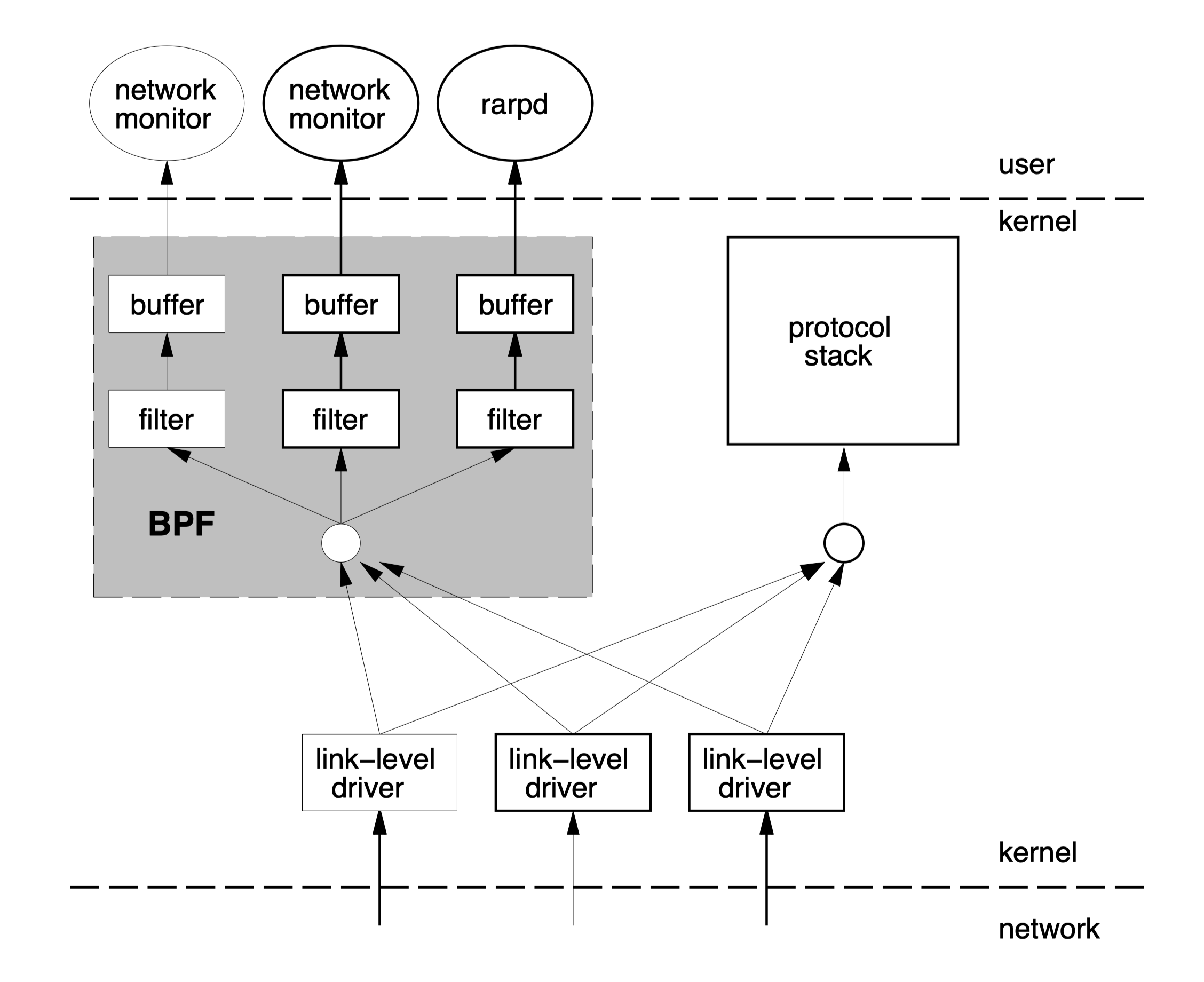
数据包之间的时间间隔只有几微秒,syscall 读每个包是不可能的。BPF 必须从包中收集数据并汇聚返回给监控应用程序。
包过滤器(Packet Filter)
决定是否丢包,以及每个包是否全都要被复制到监听程序。
**通过在中断上下文中过滤掉不想要的包实现巨大的性能提升。内存读写速率往往是性能瓶颈,数据包应该被就地过滤(网卡 DMA 引擎放置数据包的地方)**而不是在过滤前被复制到其他的内核缓冲区,从而避免 CPU 时间片被浪费在复制不想要的数据包。
性能测试(NIT vs BPF)
-
全接收
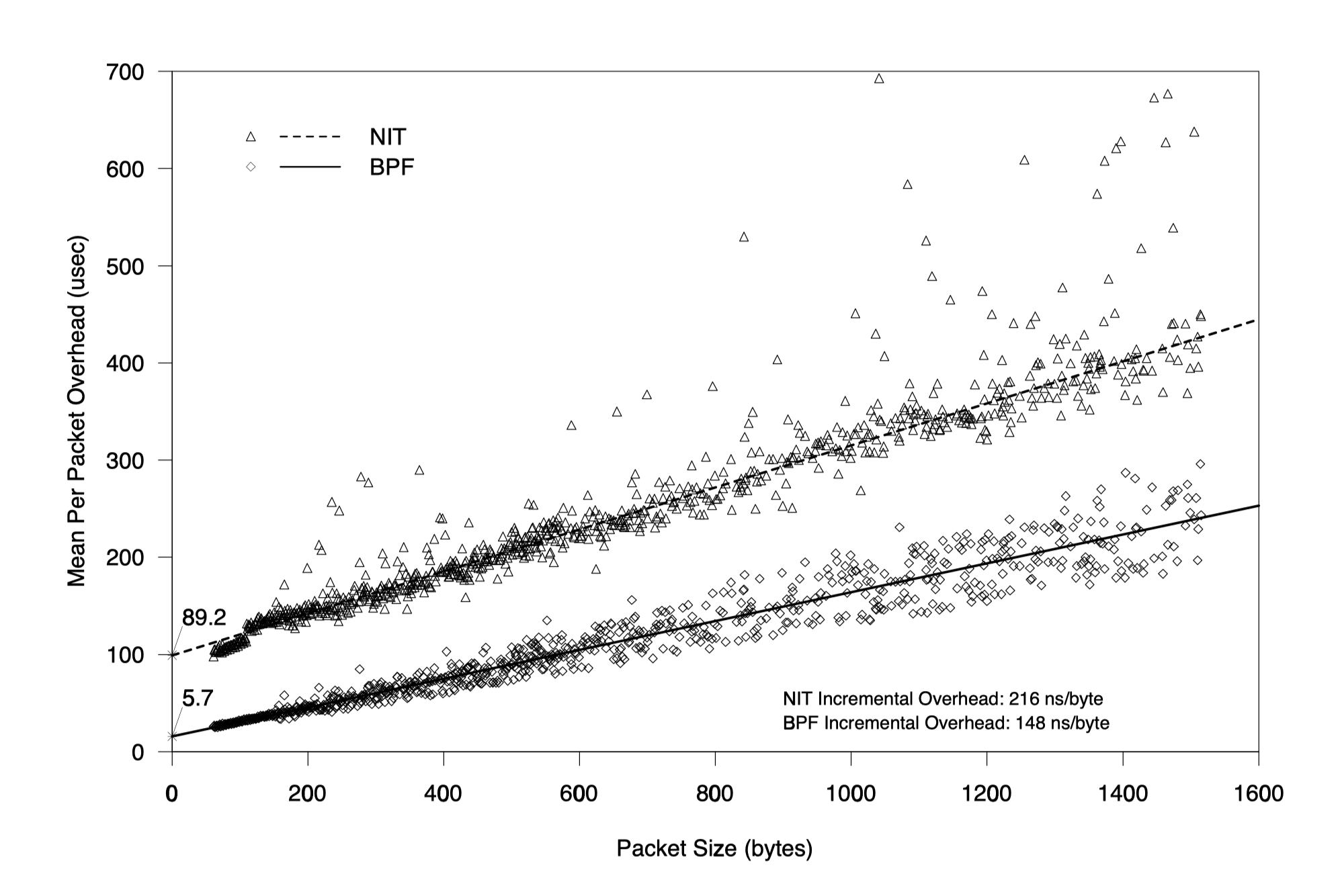
- 相较于 BPF 的内存复制速度(148ns/byte),NIT 慢了 45%(216ns/byte)
- BPF 每包调用开销大约 6us,而 NIT 89 us 是前者的 15 倍
-
全拒绝
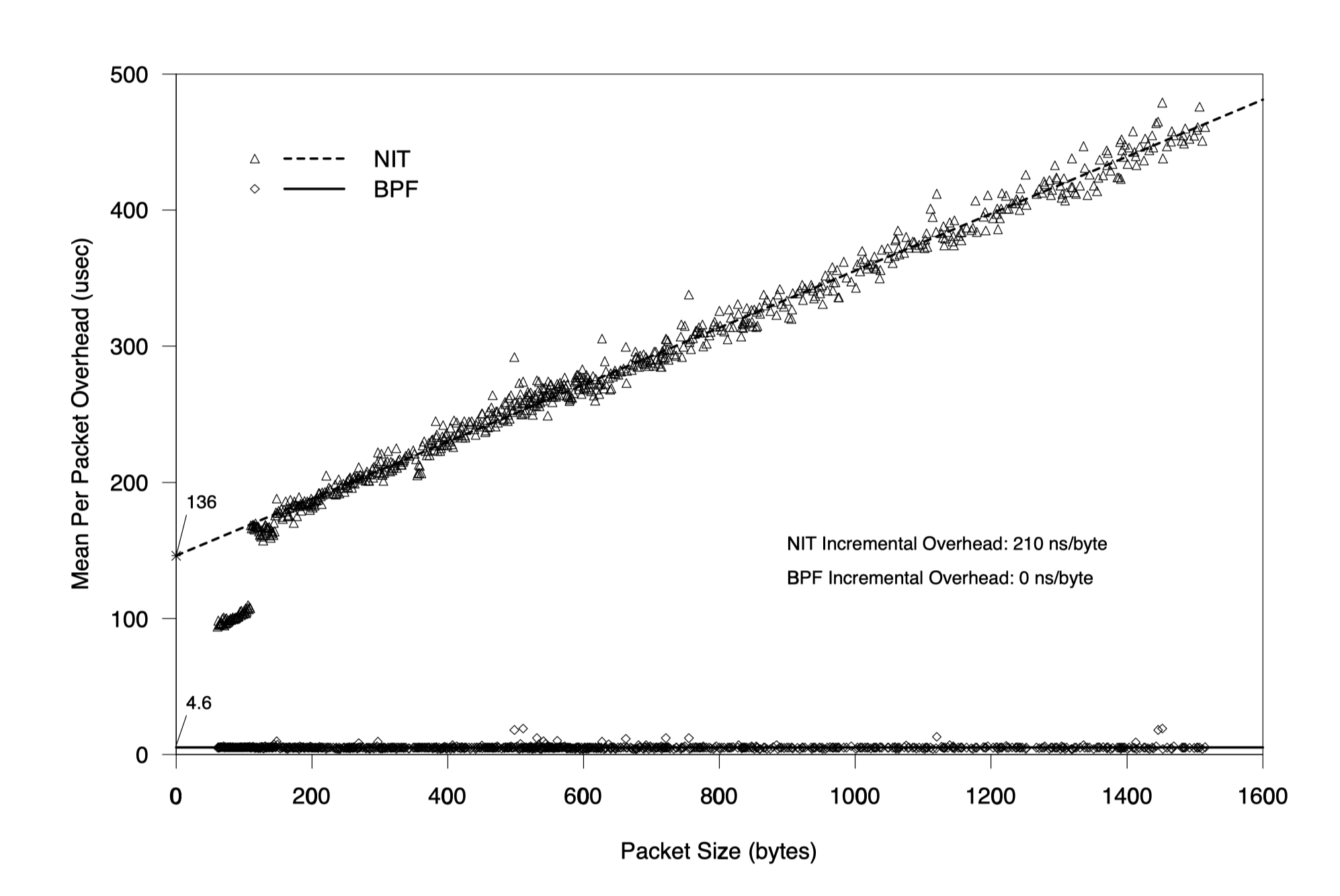
因为过滤器丢掉所有包,处理时间应该是个与包大小无关的常数
- 对于 BPF 来说以上理论成立,数据包的大小对其毫无影响;但是 NIT 没有就地过滤而是复制后再运行过滤器,因此开销与数据包体积成正比。
重要的事情说三遍,尽早就地处理数据包。
过滤模型
缓冲模型的设计是接收数据包的主要成本所在;而拒绝数据包的主要成本在于滤包计算。大多数抓包器丢的包远多于接收的包,所以包过滤器的性能至关重要。
包过滤器本质上是一个返回布尔值的函数。
两种过滤器抽象:
- 布尔值表达式树(boolean expression tree)由 CSPF 采用
- 有向无环控制流图 CFG(directed acyclic control flow graph)由 BPF 使用
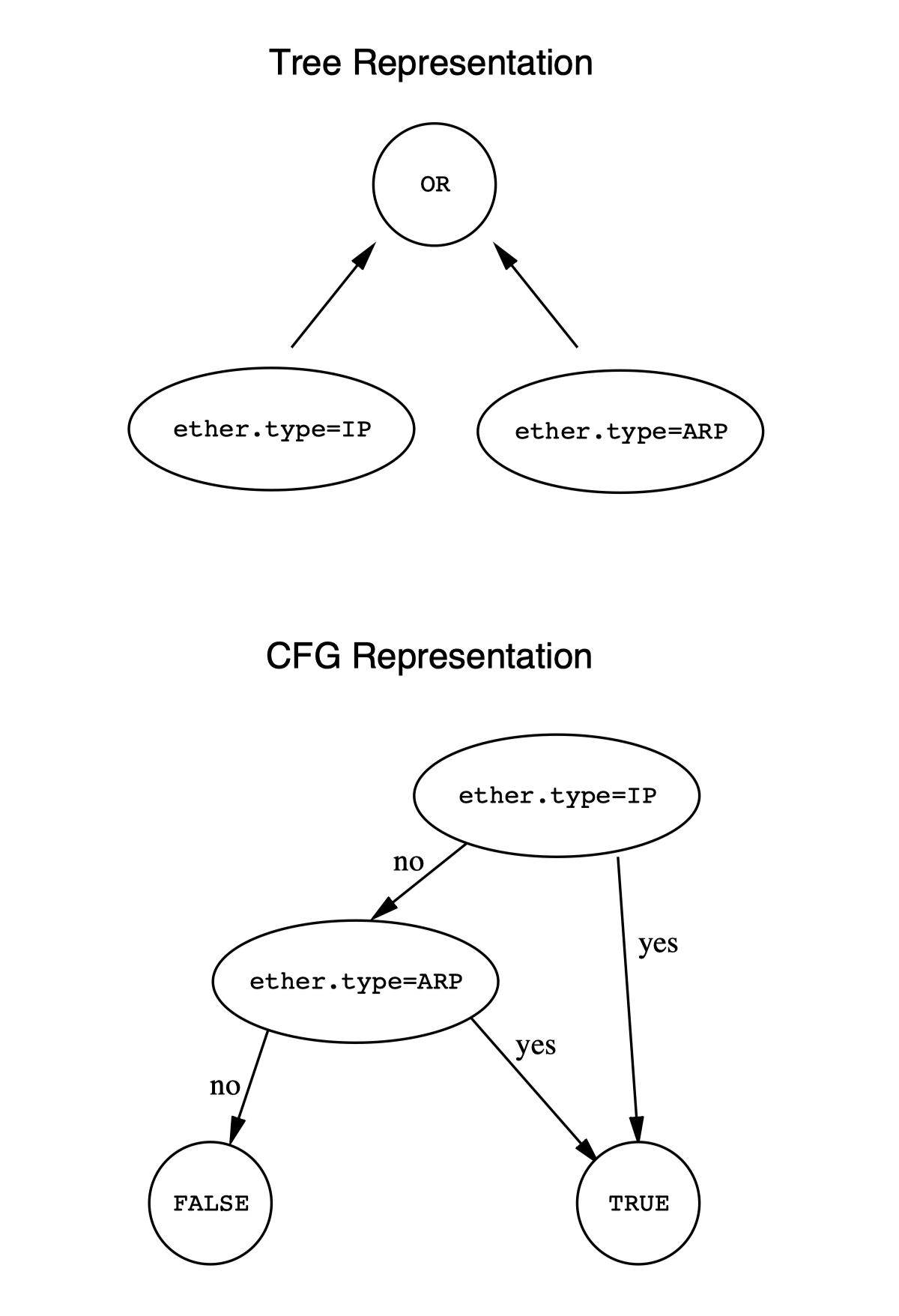
两种过滤模型在计算上是等价的;但是实现却截然不同:树模型自然地映射为堆栈机(stack machine)的代码而 CFG 模型就是注册机(register machine)了。而大多数现代机器都是基于注册机的。
CSPF(树)模型
基于运算元栈
- 缺点:
- 必须模拟运算元栈。产生加减操作来维护栈顶指针,实际上也从内存读取/写入来模拟栈。由于内存往往是主要性能瓶颈,使用寄存器中值的过滤器模型会更高效。
- 树模型经常做些不必要或者冗余的计算。图 4 中即使确认了
ether.type == IP为真还是会计算一遍ether.type == ARP。 - 无法解析可变长度包头,比如 IP 包。
- 优点:
- CSPF 将包视为简单的字节数组,过滤模型完全独立于协议
BPF(CFG)模型
将解析信息内置进流图。
While the tree model may need to redundantly parse a packet many times, the CFG model allows parse information to be ‘built into’ the flow graph.
包的解析状态在图中被记忆。
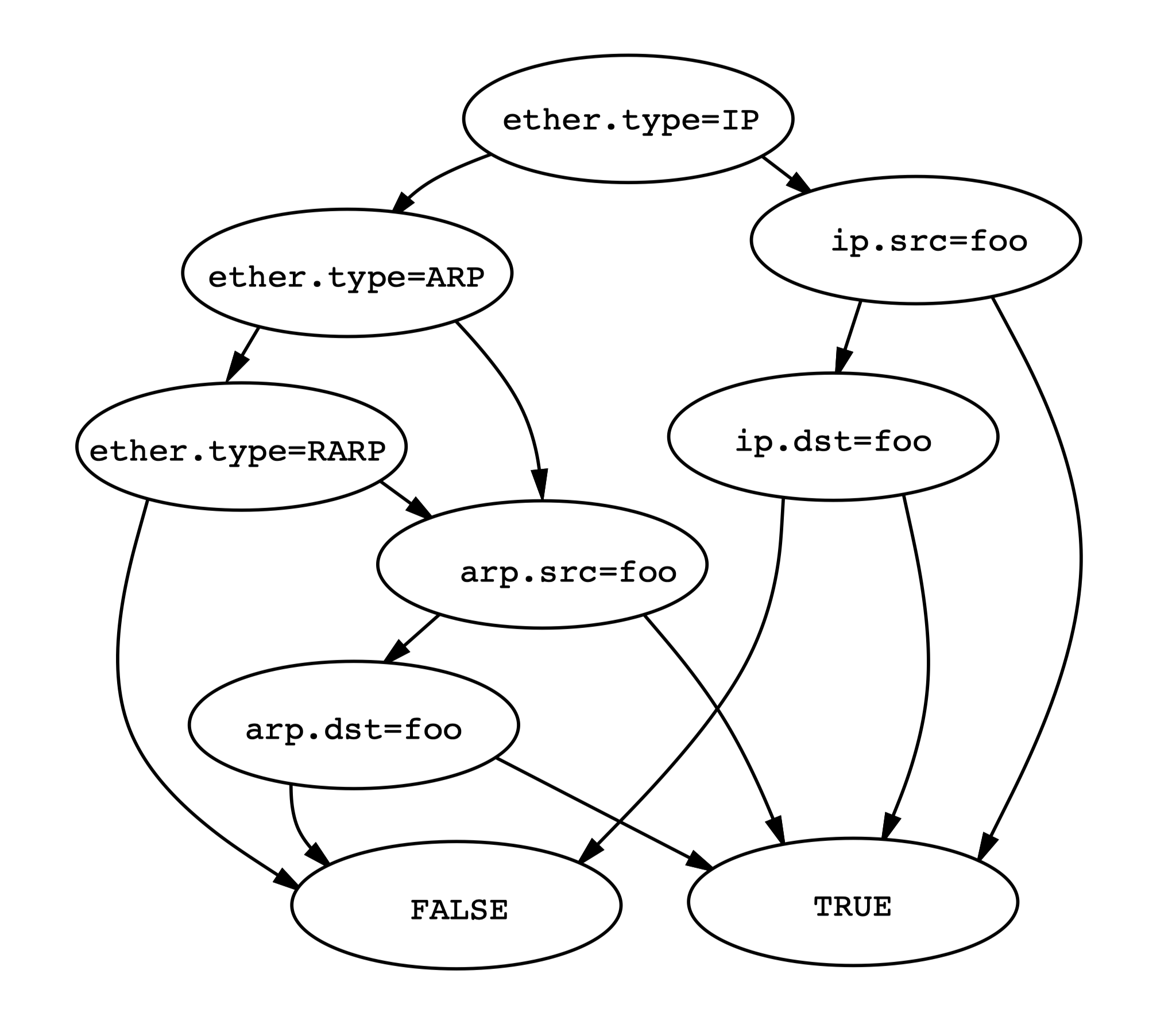
假设网络层协议为 IP、ARP 和 RARP(Reverse ARP),全都包含源 IP 和目的 IP。首先看链路层的 type 字段,一旦确定是 IP 包,就无需检查是不是 ARP 或 RARP。在表达式树模型中,在遍历整棵树时要 7 次比较和 6 次布尔运算;而 CFG 最长的一条路径有 5 次比较运算(平均 3 次)。
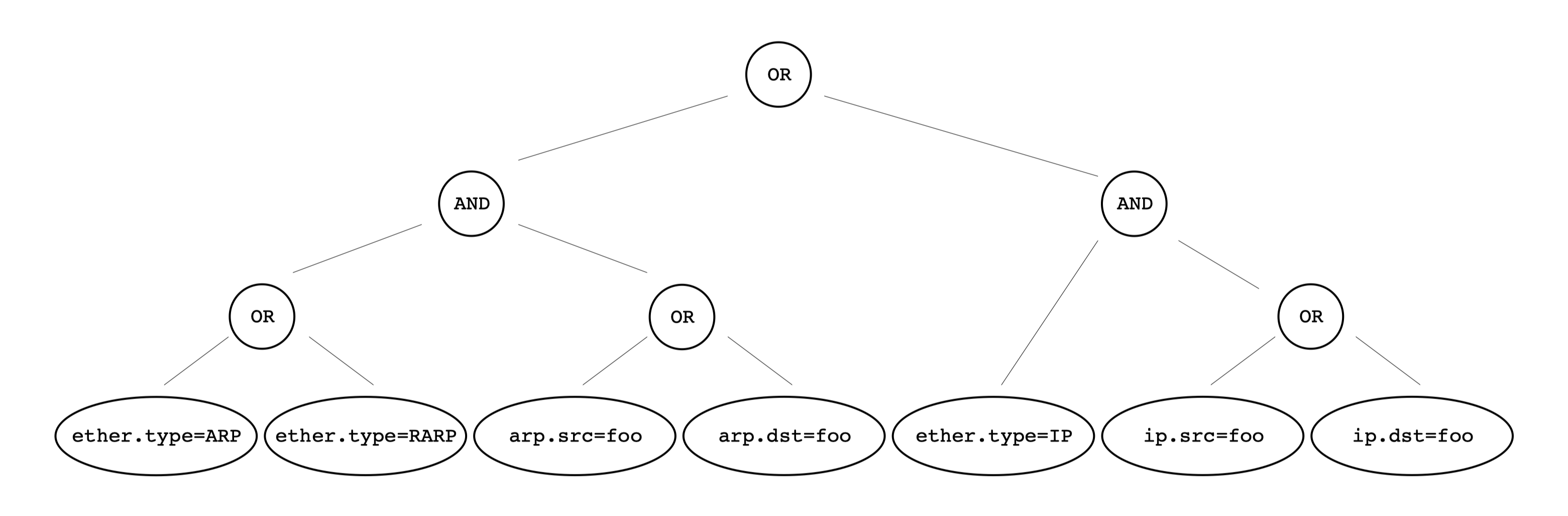
pseudo-machine 过滤器的设计
-
It must be protocol independent. The kernel should not have to be modified to add new protocol support.
与协议解耦,在模型中不能涉及任何协议。
-
It must be general. The instruction set should be rich enough to handle unforeseen uses.
通用计算模型,具有控制流、足够的 ALU 操作和传统的寻址模式。
-
Packet data references should be minimized.
尽可能减少对数据包的引用,只接触数据包一次。
-
Decoding an instruction should consist of a single C switch statement.
解码一条指令应该使用 C 语言 switch 语句。
-
The abstract machine registers should reside in physical registers.
抽象的机器寄存器应当基于物理寄存器。
BPF Pseudo-Machine
BPF 机器抽象由累加器、索引寄存器、从动存储和隐式程序计数器组成。
-
LOAD 指令
将值复制到累加器或索引寄存器
-
STORE 指令
将累加器或索引寄存器的值复制到从动存储
-
ALU 指令
使用索引寄存器的值或常数作为操作数,对累加器执行算术或逻辑运算
-
BRANCH 指令
比较常数或索引寄存器还有累加器,然后选择控制流
-
RETURN 指令
结束过滤。如果过滤器返回 0 表示包完全被丢掉
-
MISCELLANEOUS 指令
一堆汇编,不看了。
过滤器性能测试
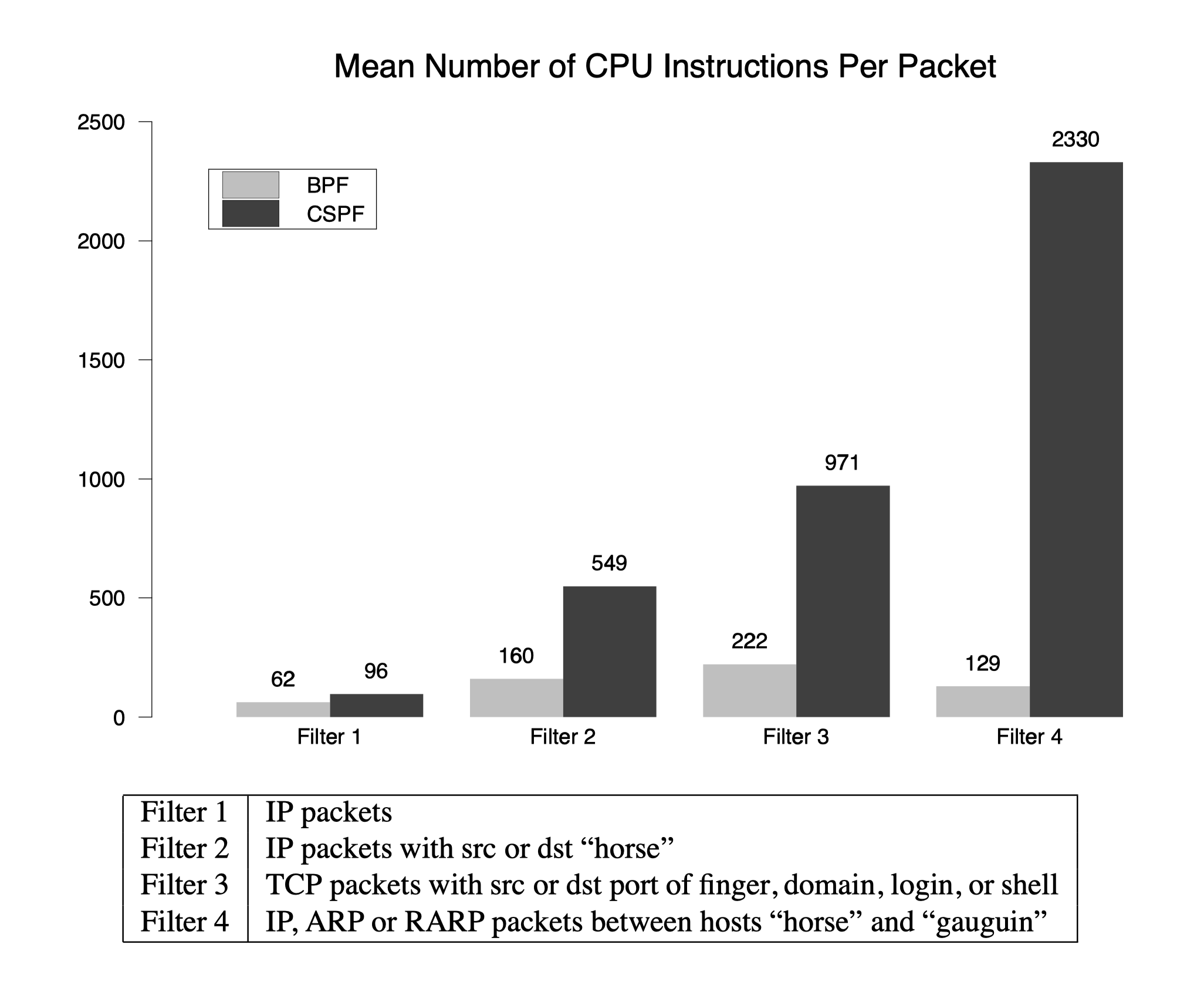
-
过滤器 1 测试数据包中的一个 16 位的字是否包含既定值
BPF 快了 50%
-
过滤器 2 搜索特定的 IP 主机(源 IP 或目的 IP)
性能差距扩大到 240%,CSPF 只能对 16 位字操作,需要两次比较才能确定 32 为的网络地址是否一致
-
过滤器 3 解析数据包(要求确定 TCP 目的端口字段)
BPF 过滤器只对数据包解析一次,而 CSPF 过滤器会反复解析
-
过滤器 4 IP、ARP 还有 RARP 数据包主机名为 horse 和 gauguin
CSPF 采用的树模型存在冗余计算导致
应用
- tcpdump
- 过滤器由对用户友好的、高级的描述语言来说明
- 有一个内置的编译器来将高级过滤器翻译为 BPF 程序
- arpwatch
- Icon 编程语言
- netload
- histo
- RARPD(Reverse ARP daemon)
总结
- 高效
- 可扩展
- 通用
- 可移植