Before-or-After 原子性
Apr 1, 2022 20:00 · 3259 words · 7 minute read

来自 MIT 6.033 Computer System Design Chapter 9。
9.1.5 Before-or-After 原子性:协调并发线程
并发的线程同时写同一块数据可能会有问题。
从程序员的角度来看,有两种截然不同的并发协调需求:
-
顺序协调 sequence coordination
sequence coordination 是一种约束,事件 W 必须在事件 X 之前发生。
第一个操作必须在第二个操作开始之前完成。
一般来说,写一个顺序协调的程序时,程序员已经知道并发操作的实体。因此顺序协调通常在代码中是显式的,使用特殊的语言结构或共享变量。
-
之前或之后原子性 before-or-after atomicity
before-or-after atomicity 是一种更普遍的约束,同时对同一数据的操作不应该相互干扰。
before-or-after atomicity 定义:
Concurrent actions have the before-or-after property if their effect from the point of view of their invokers is the same as if the actions occurred either completely before or completely after one another. 如果从调用方的角度看,不论完全在之前发生还是完全在之后,并发操作的结果都相同,那它们就具有 before-or-after 属性。
before-or-after atomicity 与 sequence coordination 不同之处在于程序员不一定知道所有可能接触共享变量的操作。这是一种信息缺失,会给通过明确的程序步骤来协调操作带来问题。相反,程序员要的是一个自动的隐式机制,它能够确保每个共享变量被正确处理。
在计算机系统中 before-or-after atomicity 的应用比比皆是。操作系统中,几个并发的线程可能同时要使用打印机,绝不可以不同线程交错输出打印行。其实哪个线程先用打印机并不重要,要考虑的是,在下一个线程开始打印前上一个线程要完成打印,这个需求赋予了每个打印作业 before-or-after atomicity 属性。
具体到银行转账这个案例:账户余额被保存在共享的变量中(reference 代表参数是一个引用,这样 TRANSFER 函数能够对其变更):
procedure TRANSFER (reference debit_account, reference credit_account, amount)
debit_account ← debit_account - amount
credit_account ← credit_account + amount
“X ← X + Y 这样的程序语句实际上是一系列复合的操作,包括:
- 读取 X 和 Y 的值
- 做加法
- 将结果写回 X
如果有一个并发的线程在该语句期间读取并修改了 X 的值,它所做的变更很可能会被覆盖掉。
假设账户 A(一开始有 $300)给账户 B(一开始有 $100)转账 TRANSFER (A, B, $10)
我们所期望的状态是:
- 账户 A,即转出的账户,转账结束后余额为 $290
- 账户 B,即转入的账户,转账结束后余额为 $110
假设还有一个并发的线程在执行 TRANSFER (B, C, $25)
账户 C 一开始有 $175。当两笔转账完成后,我们期望:
- 账户 B 余额为 $85
- 账户 C 余额为 $200
而且,两次转账不论顺序先后结果都应该是一样的。但是第一个线程中的变量 credit_account 和第二个线程中的变量 debit_account 实际上指向的是同一个对象(账户 B),当两笔交易同时发生时就有出错的风险。
两个线程的读写步骤存在多种可能的时间线:
- 如果步骤 1-1 和 1-2 先于步骤 2-1 和 2-2,那两笔转账就会如期执行(反之亦然),最终 B 账户的余额停留在 $85。
- 但如果步骤 2-1 在步骤 1-1 之后,步骤 1-2 之前发生,那就出错了:两笔转账其中之一将跳过账户 B。
前面两个案例是正确的时间线;后面四个案例则是错误的时间线。
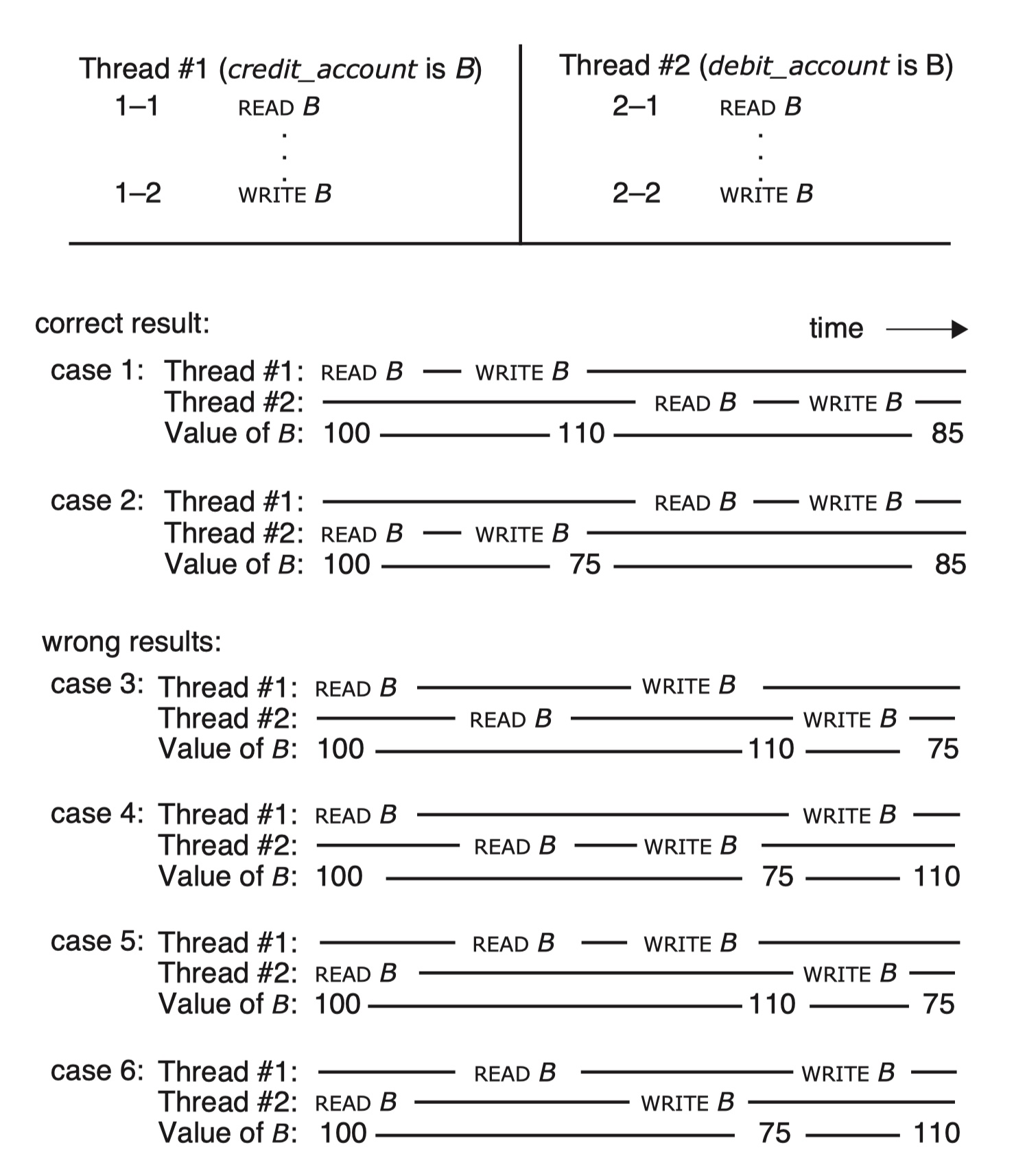
因此我们的目标就是要确保交易按前两个时间线走。一种办法是步骤 1-1 和 1-2 是原子的,同理步骤 2-1 和 2-2 也是原子的。 步骤 debit_account ← debit_account - amount 和 credit_account ← credit_account + amount 都应当是原子的。
9.1.6 正确性与串行化
以上案例的对错判定基于我们对银行转账的理解,最好有一个不依赖于特定应用场景的更广泛的正确性概念:如果每个结果都能保证由同样的操作的串行执行得到,那么并发操作之间的协调就可以被认为是正确的。
coordination among concurrent actions can be considered to be correct if every result is guaranteed to be one that could have been obtained by some purely serial application of those same actions.
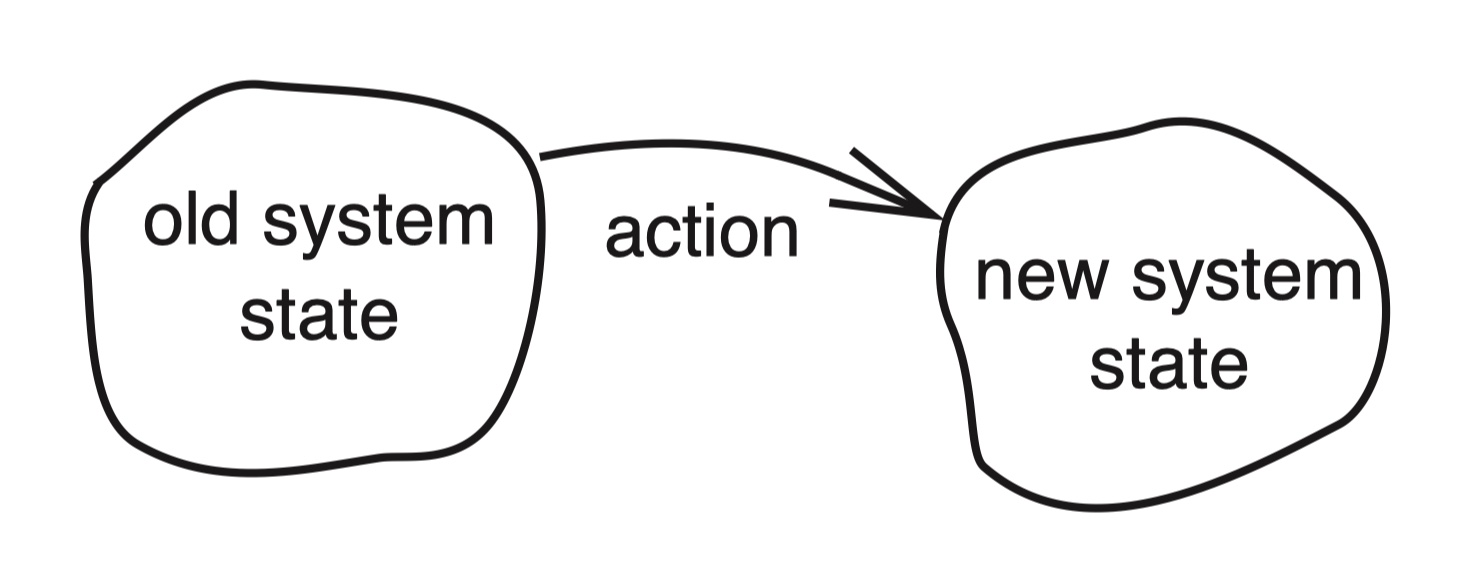
抽象地说,操作改变系统的状态。如果我们确定:
- 从应用程序的角度来看,系统原来的状态是正确的
- 完全由它自己执行的操作,正确地 将正确的旧状态 转变为 正确的新状态
那么就可以断言新的状态一定是正确的。这个推理思路适用于任何与应用程序相关的“正确”和“正确地转换”的定义。
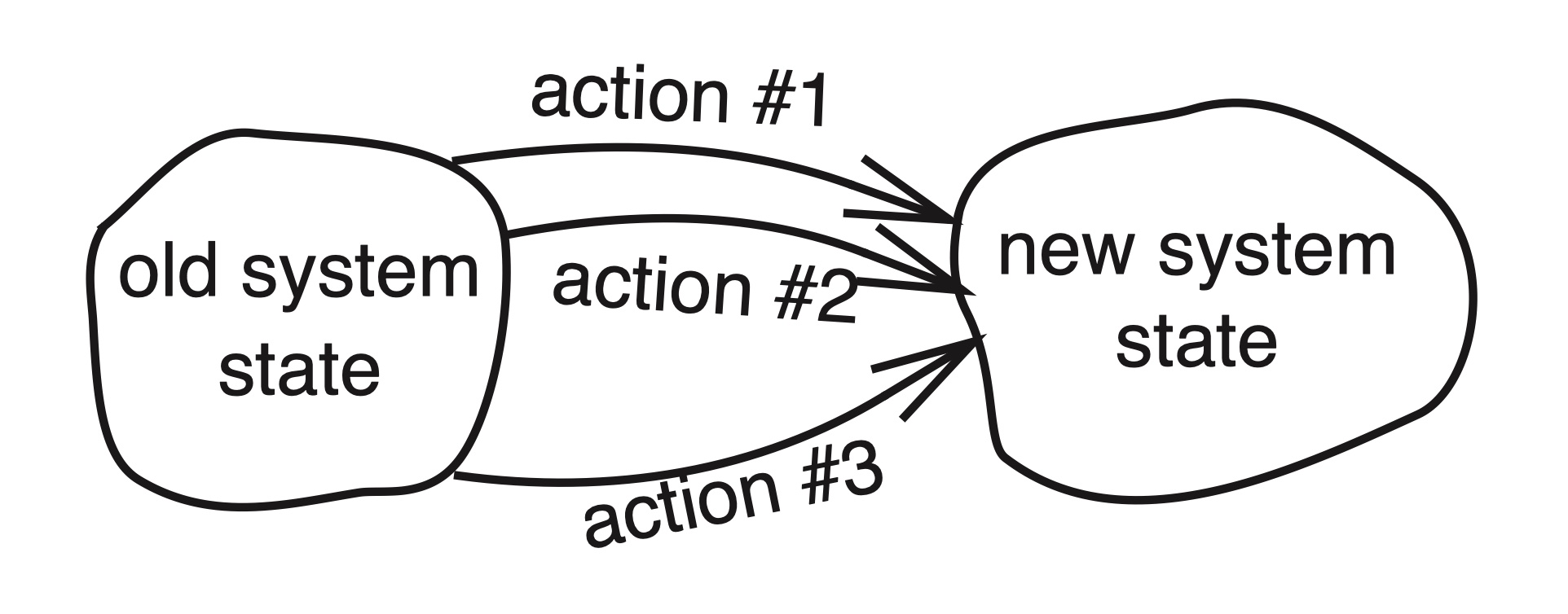
当几个操作并发进行时,相应的要求是它们产生的新状态,应该是由同样的操作按某种顺序执行后所产生的状态。只要 before-or-after atomicity 是唯一的协调要求,任何顺序都能做到。
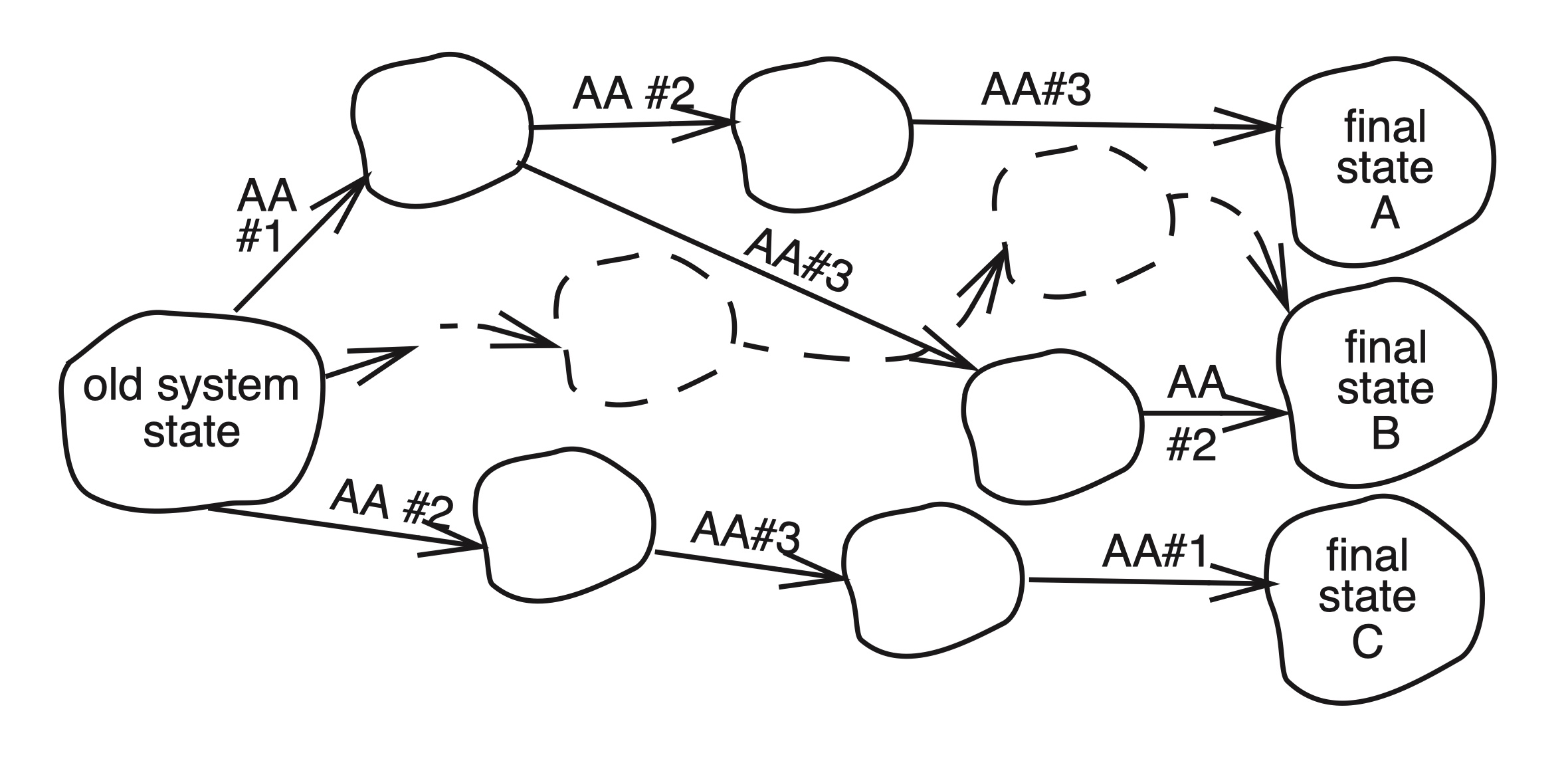
甚至系统的中间状态不正确也没事,因为中间状态是对应用不可见的,只要系统能够保证最终状态是可被接受的,我们也可以认为协调是正确的。
随着并发操作和每个操作中的步骤数量的增长,各步骤顺序的可能性会迅速增加,但只有其中的一部分能确保结果正确。由于并发是为了提升性能,我们希望有办法能够从一组正确的顺序中挑选出性能最好的那个,但是相当困难。
某些应用程序可能要求比可序列化更强的正确性。举个栗子,一种处理器架构可能要求时序一致性(sequential consistency):当处理器并发地执行来自同一条指令流的多条指令,结果应该和程序员指定的顺序执行一样。回到银行转账,实际的应用场景通常会有一些不同的 before-or-after atomicity 要求。考虑到接下来的审计,要验证所有账户的余额之和为零(属于银行的那个账户余额为负数)
procedure AUDIT()
sum ← 0
for each W ← in bank.accounts
sum ← sum + W.balance
if (sum ≠ 0) call for investigation
假设有一条线程正在转账,另一条线程同时在跑 AUDIT。如果 AUDIT 在转账前检查账户 A,在转账后检查账户 B,它将会两次计数转账金额并计算出错误的结果。所以整个审计操作应该要么都在转账前要么都在转账后发生:我们希望它是一个 before-or-after 操作。也就是说两次余额更新要么在所有审计操作完成之前要么在完成之后,转账应当是一个 before-or-after 操作。
9.5.2 简单锁(Simple Locking)
简单锁有两条规则:
- 每个事务在读写前,必须为读写的共享数据对象获取锁。
- 只有在事务提交或完全回滚数据后才能释放锁。
- lock point:事务获得所有锁的那个瞬间。
- lock set:事务在 lock point 获取到的锁的集合
想象一下有个上帝视角的外部观察者维护着一个有序列表,当事务来到其 lock point 时,它会将事务的 ID 加到表中;并在锁释放时从表中剔除。在简单锁的约定下,所有事务都不能在它被观察者添加至列表中之前读写任何东西。还有一个已知条件,在观察者的列表中排在前面的事务一定已经越过了它们的 lock point。因此没有数据对象可以出现在两个事务的 lock set 中,所以任意事务 lock set 中的数据对象都不会出现在观察者列表中排在它前面的事务的 lock set 中。因此该事务所有的输入值都和列表中前一个事务提交或中止时的输入值相同,这个结论也同样适用于前面的事务。 简单锁的规则确保一个事务在前一个事务完成后执行,在下一个事务执行前完成。并发事务会被串行化为它们到达 lock point 时的顺序。复杂事务使用简单锁可能会丢失并发性;另一方面如果事务很简单,简单锁就很有用。
9.5.3 二阶段锁(Two-Phase Locking)
二阶段锁被广泛使用,但很难说它是否正确。 主要限制在于在越过 lock point 前事务不会释放任何锁。二阶段锁这个名称是因为事务持锁数量单调递增直到 lock point(第一阶段),然后单调递减(第二阶段)。和简单锁一样,二阶段锁也会对并发事务排序,这样结果就和它们到达 lock point 时的顺序一样。lock manager 通过在首次接触每个共享变量时持锁实现二阶段锁,它会持锁至事务结束或中止,然后一次性释放掉。
二阶段锁的灵活性使得它难以保证 before-or-after atomicity。
二阶段锁可能比简单锁的并发性更好。举个栗子,假设事务 T1 读 X 变量写 Y 变量,而 T2 只对 Y 变量写一次。因为 T1 和 T2 的 lock set 相交于变量 Y,二阶段锁的性质会强制事务 T2 要么在 T1 之前完成要么在它之后。但是,以下顺序
T 1 : READ X
T 2 : WRITE Y
T 1 : WRITE Y
中,T2 事务中的写操作出现在 T1 事务的两步之间,和 T2 在 T1 之前完成结果是一样的,结果也是正确的,但是这种顺序会被二阶段锁阻止。既考虑到所有可能的并发性又要确保 before-or-after atomicity 相当难搞。
锁和日志之间的两种交互值得深思:
-
个别事务中止
中止相对好处理些,要在锁释放之前把数据还原。
-
系统恢复
问题在于锁本身也是数据对象,是都应该被日志记录下来。要分析这个问题,假设现在系统崩溃了。在恢复完成时,不应该有 pending 的事务,因为所有在崩溃时 pending 的事务都应该已经在恢复处理中被回滚。并且在恢复完成前不允许开始任何新事务。由于锁的存在只是为了协调 pending 的事务,如果恢复完成后仍有锁未被释放,这明显有问题。锁属于易失性存储,系统崩溃时它们会自动消失。然而更大的问题是,基于日志的恢复算法是否会构建一个正确的系统状态——是由那些在崩溃前提交的事务某些序列产生的。假设有些事务只记录下了 BEGIN 但还没来得及记录 END。恢复算法会对未完成的事务 UNDO 或 REDO,修改的变量就是在崩溃时被事务上锁的那些。因为 lock set 不重叠,所以这些操作能够安全地重做或撤销,而不必在恢复时担心 before-or-after atomicity。换句话说,锁将事务序列化了,而日志捕获了这个序列。