容器环境中避免 CPU 节流
Jul 4, 2022 20:30 · 1991 words · 4 minute read

原文 https://eng.uber.com/avoiding-cpu-throttling-in-a-containerized-environment/
当你拥有 6.5 万台主机,2.4 百万个核心,20 万个容器时,减少开销提升 CPU 利用率是非常重要的而且是一场持久战。CPU 节流意味着没有分配足够的资源。
在这篇博客中我们会论述 CPU quota 如何转换为 cpuset(也就是 CPU 时间片)。
Cgroup、Quota 和 Cpuset
CPU quota 和 cpuset 都是 Linux 内核调度器的功能。Linux 内核通过 cgroup 实现了资源隔离,所有的容器平台都基于该能力跑在容器中的进程的资源。
有两种 cgroup 来做到 CPU 隔离:CPU 和 cpuset。它们都能控制一组进程被允许使用多少 CPU,但是两种不同的路子:一边是通过 CPU 时间配额,而另一边则是 CPU 绑定。
CPU Quota
CPU 控制器使用配额使能隔离。对一个 CPU 集指定允许使用的 CPU 核心数,通过以下公式转换成时间片内(通常 100ms)的配额:
quota = core_count * period
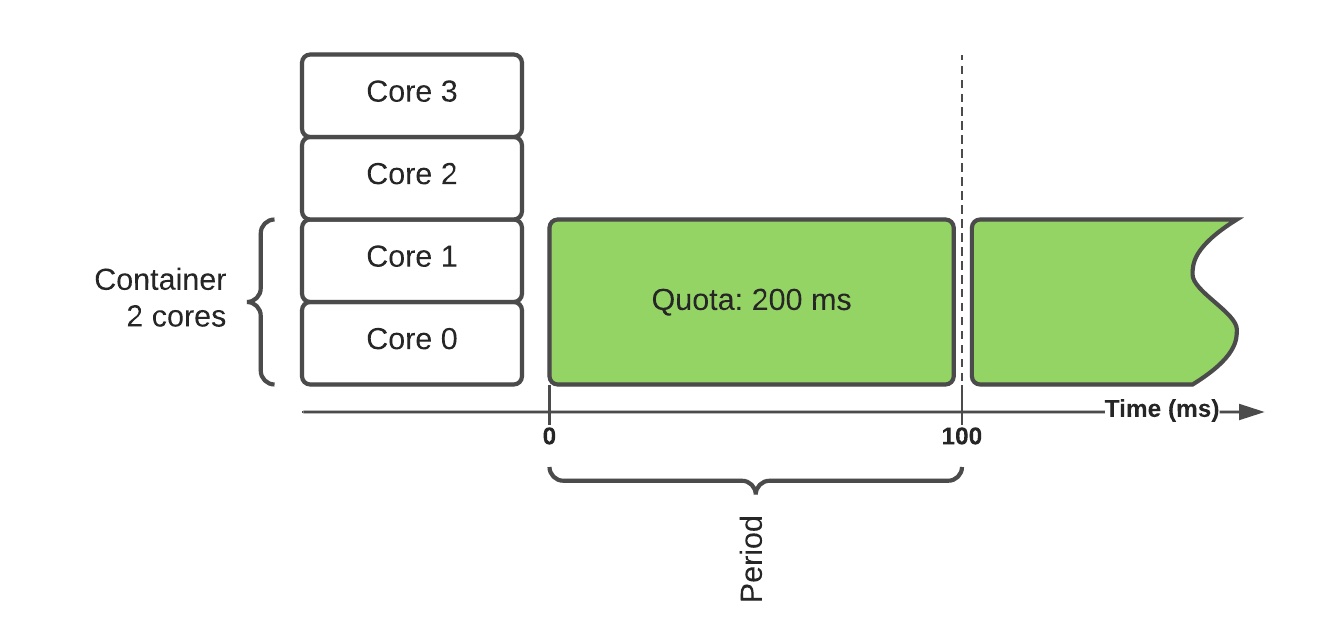
上述案例中某个容器需要两个核心,转换成了每时间片 200ms CPU 时间。
CPU Quota 和节流
不幸的是,如果容器内多进程/线程,这种方式就有问题:会使得容器过快地用光配额,导致它在剩下的时间里被节流。
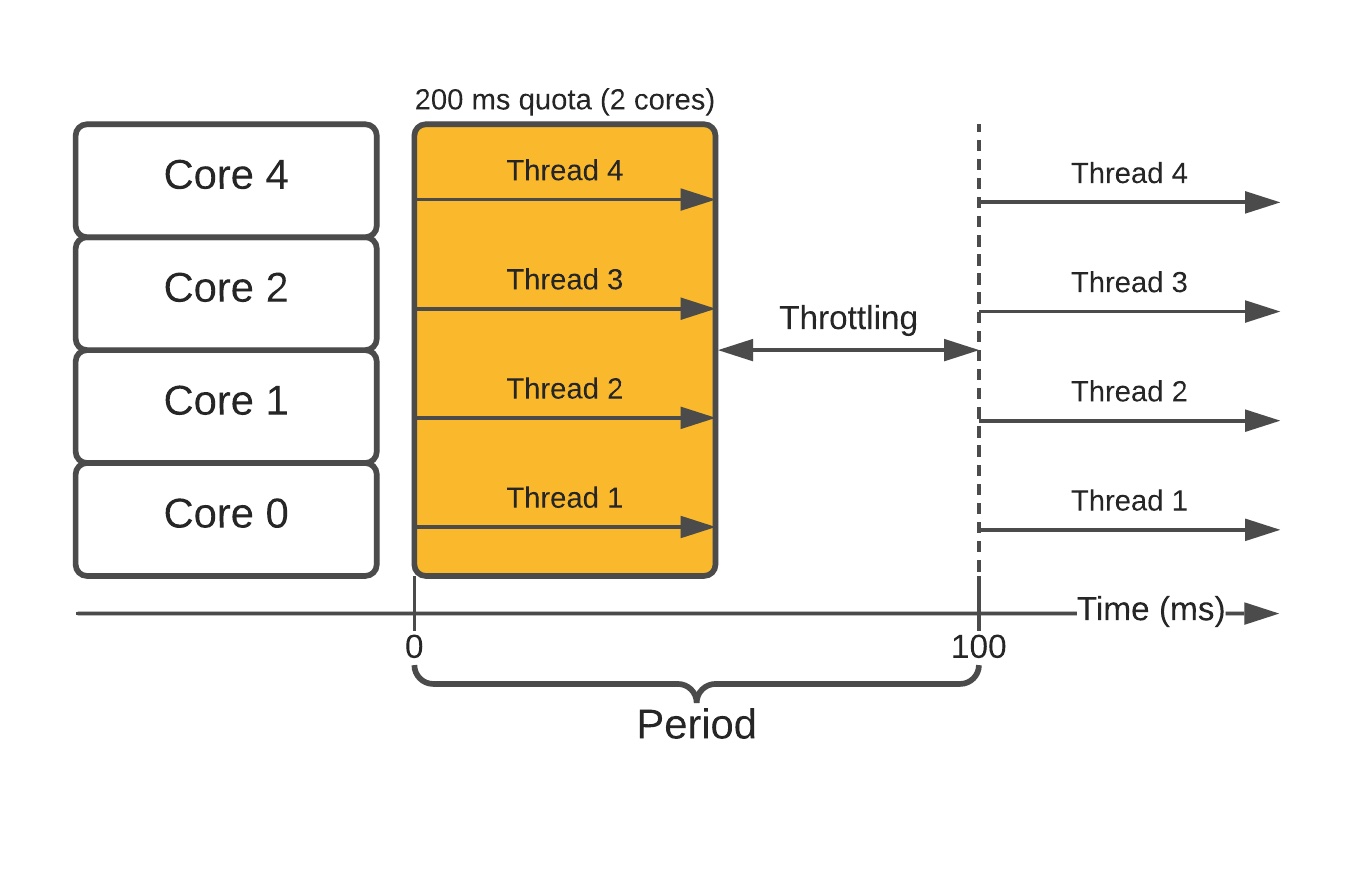
如果容器内跑着需要提供低延迟服务的程序,最终会出问题。突然间因为节流,通常只消几毫秒就能应答的请求可能要花一百多毫秒。
一个简单的解决方案是为进程分配更多的 CPU 时间,虽然有效,但规模大了后代价巨大;另一个解决方案是直接不要隔离了,但这是个非常烂的主意,因为一个进程可能会彻底饿死同节点上的另一个进程。
使用 Cpuset 避免节流
cpuset 控制器使用 CPU 绑定而非配额——基本上限制了容器能够运行在哪个核心上。这意味着有可能将所有的容器分布至不同的 CPU 核心,这样每个核心只服务单个容器。这样就实现了完全隔离,不再需要配额或节流。
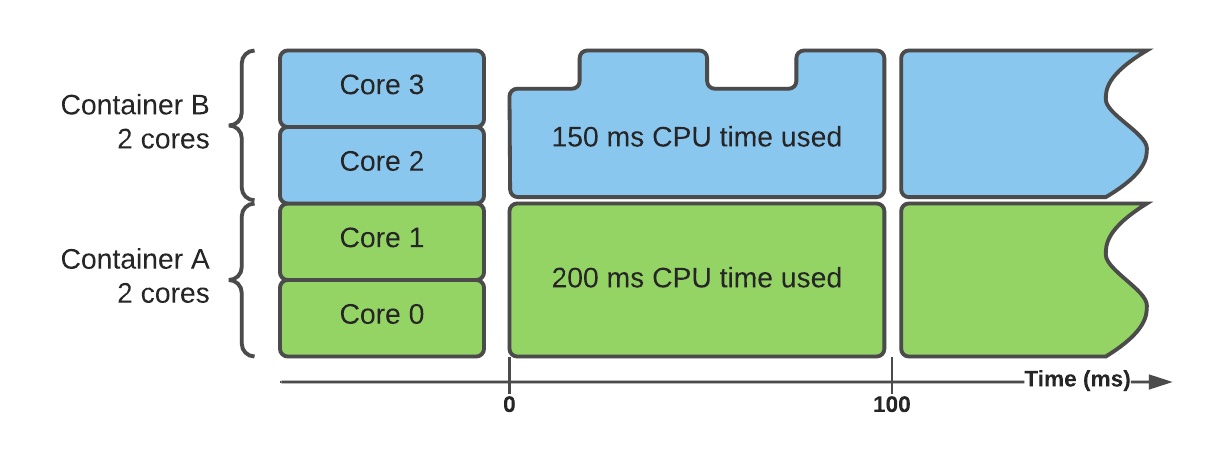
此时两个容器运行在两组不同的核心上。它们被允许使用这些核心上所有可以使用的时间,但丝毫不能利用未分配的核心。
这样做的结果是 P99 延迟变得更稳定。。。下面是一个在生产数据库集群上使用 cpuset 的案例,所有的节流都如期消失,因为容器可以随心使用所有已分配的核心。
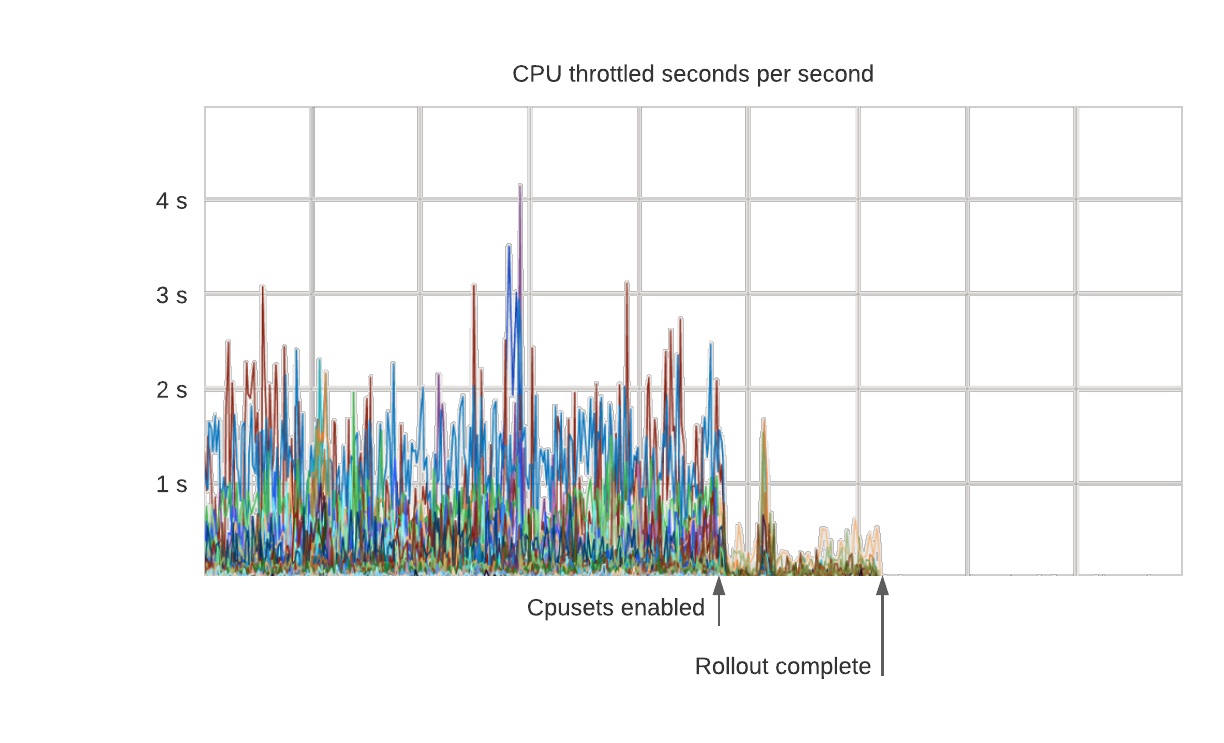
更有趣的是 P99 延迟甚至改善了因为容器能够以稳定的速率处理请求。在这个案例中由于消除了严重的节流,延迟下降了约 50%。
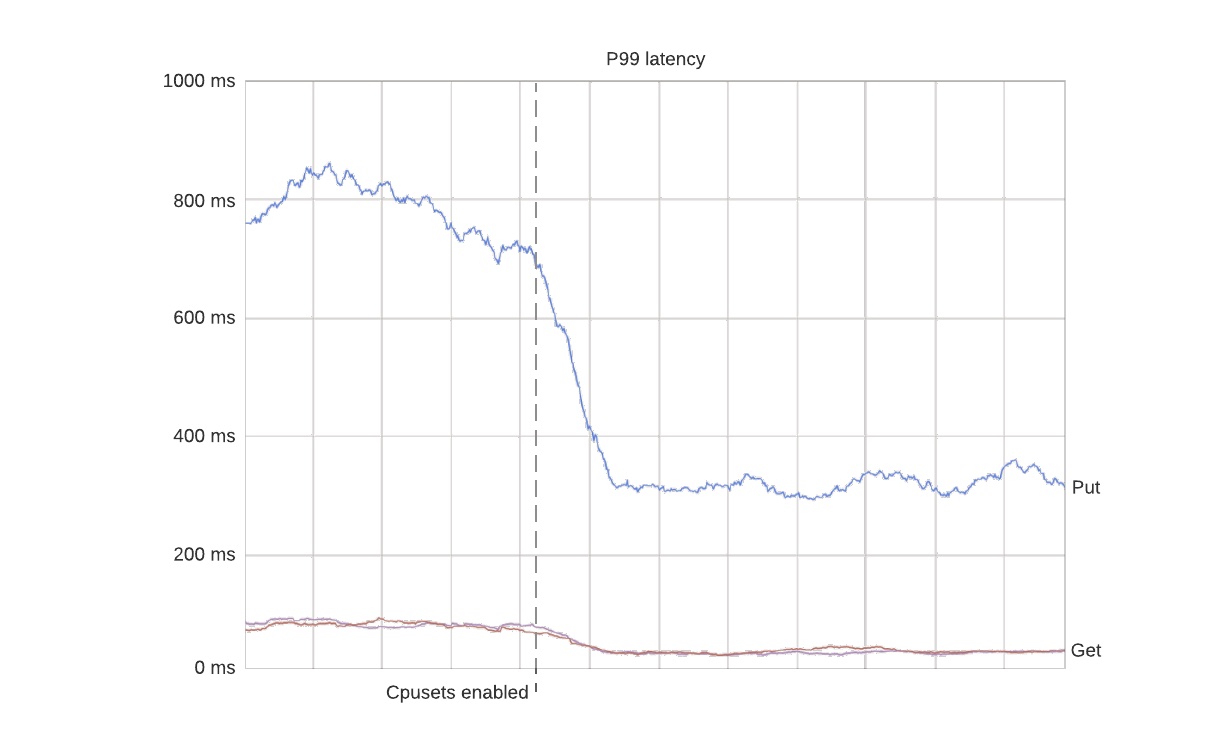
要注意的是使用 cpuset 也有副作用。尤其是 P50 延迟通常会增加一些因为不可能再用到未分配的核心了。最终结果是 P50 和 P99 延迟更加接近,这样最好。
P99 延迟(第 99 百分位延迟时间):所有请求中处理速度最快的 99% 的最长延迟时间(以秒为单位)。举个栗子,如果第 99 百分位延迟时间是 2 秒,表示有 99% 的请求可以在 2 秒内得到处理。 P50 延迟(第 50 百分位延迟时间):所有请求中处理速度最快的 50% 的最长延迟时间(以秒为单位)。如果第 50 百分位的延迟时间是 0.5 秒,表示有 50% 的请求可以在 0.5 秒内得到处理。
分配 CPU
要使用 cpuset,容器必须与核心绑定。正确地分配核心需要一点现代 CPU 架构的背景知识,因为错误的分配会导致严重的性能衰减。
典型的 CPU 结构:
- 一台物理机可能有多个 CPU 插槽
- 每个 CPU 有多个核心
- 每个 CPU socket 有一个独立的 L3 缓存
- 每个核心有独立的 L2/L1 缓存
- 超线程通常被视为核心,但是分配两个超线程带来的性能提升只有一个的 1.3 倍。
挑选正确的核心至关重要。有个比较麻烦的问题,编号不连续,有时甚至不确定——例如拓扑结构可能看起来像这样:
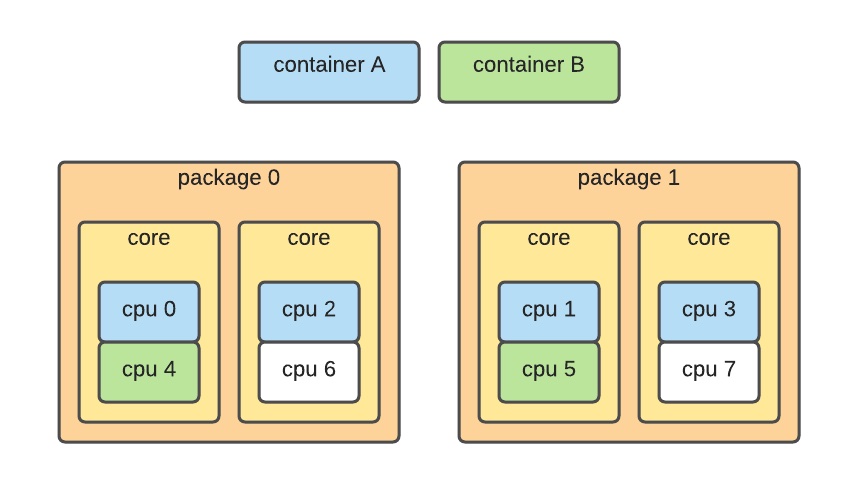
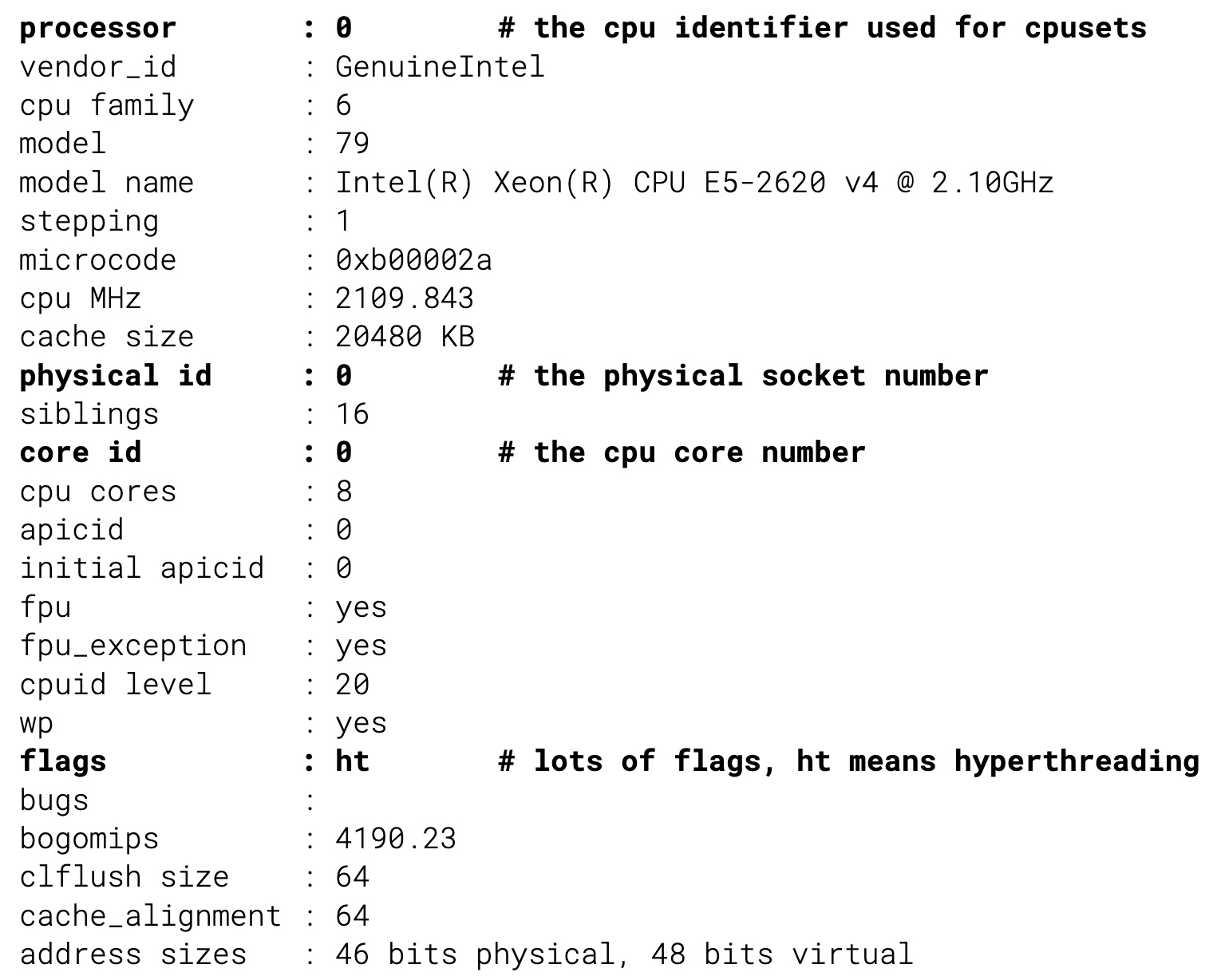
在这种情况下,容器被调度在跨插槽的不同 CPU 核心上,这会导致糟糕的性能——由于错误的插槽分配,P99 延迟下降了 500%。要处理这个问题,调度器必须从内核中收集准确的硬件拓扑结构,并利用它来分配内核。真实信息在 /proc/cpuinfo 提供:
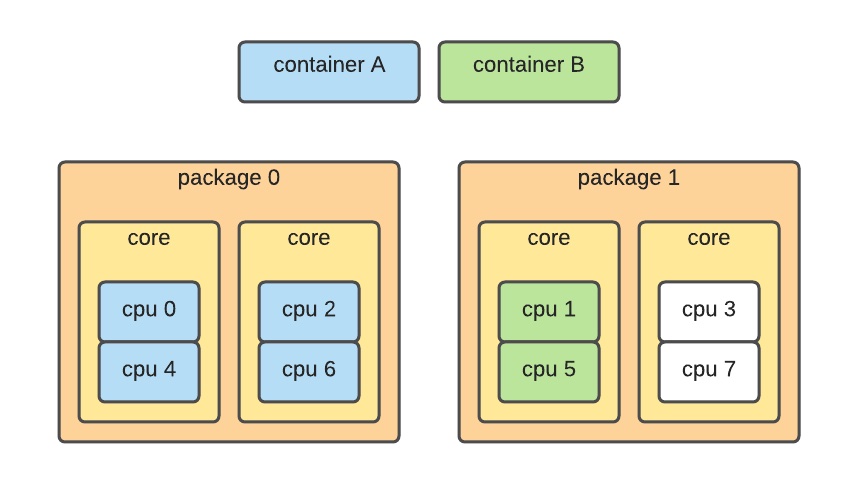
利用这个信息,我们可以分配物理距离更近的核心:
弊端与局限性
- 不能分配零散的核心:这对数据库进程来说不是问题因为它们通常都很大,所以向上或向下取整没问题。但这意味着,容器数量不能大于 CPU 核心数量,不然某些工作负载会出问题。
- 系统级进程仍会偷时间:systemd、kernel worker 还是要跑的呀,理论上也可以把它们分配给一组有限的核心,但棘手的是它们需要的 CPU 时间与系统负载成正比。另一个变通方法是在容器的一个子集上使用实时进程调度。
- 需要碎片管理:随着时间的推移可用的核心会变得支离破碎,进程要被移动以创造连续的可用核心块。虽然这个可以在线完成,但是从一个物理插槽移动到另一个物理插槽意味着与内存的距离会变得遥远。也可以缓解,主题是 NUMA。
- 没有加速(burst):有时你可能想要使用主机上未分配的资源来加速容器,本文讨论了独占的 cpuset,但也有可能将同一核心分配给多个容器,通过 quota 合并 cpuset 也是有可能的:这就允许加速了,但是也是另一个主题。
总结
将有状态的工作负载切换至 cpuset 对 Uber 来说是一个巨大的提升,实现了更稳定的数据库级延迟,节省了之前采用超配来解决节流导致的 11% 的核心浪费。由于没有加速,相同尺寸的容器在主机上的性能表现一致。
Uber 有状态部署平台是内部开发的,但 Kubernetes 通过静态策略(static policy)支持 cpuset。
Uber 测试 quota 和 cpuset 的细节,请阅读 https://gist.github.com/ubermunck/2f116b7817812ae6255d19a4e10242f4。