NSQ
Nov 2, 2020 23:15 · 1873 words · 4 minute read

NSQ 是一个实时的分布式消息平台。
特点:
- 分布式拓扑,无惧单点故障
- 水平扩展,随时可以向集群添加节点
- 低延迟的消息推送
- 结合了负载均衡和组播式消息路由
- 尤其适合流媒体(高吞吐量)和面向作业(低吞吐量)的负载
- 主要基于内存
- 为消费者提供生产者发现服务(nsqlookupd)
- 统计信息、管理操作等接口走 HTTP 协议
- 强大的集群管理图形界面(nsqadmin)
部署 NSQ
从 NSQ github release 下载对应操作系统版本的 nsq 二进制可执行文件并解压:
$ wget https://github.com/nsqio/nsq/releases/download/v1.2.0/nsq-1.2.0.linux-amd64.go1.12.9.tar.gz
$ tar xvzf nsq-1.2.0.linux-amd64.go1.12.9.tar.gz
$ ll nsq-1.2.0.linux-amd64.go1.12.9/bin
-rwxr-xr-x. 1 root wheel 8759168 Aug 28 2019 nsqadmin
-rwxr-xr-x. 1 root wheel 9067872 Aug 28 2019 nsqd
-rwxr-xr-x. 1 root wheel 8338528 Aug 28 2019 nsqlookupd
-rwxr-xr-x. 1 root wheel 5643456 Aug 28 2019 nsq_stat
-rwxr-xr-x. 1 root wheel 5904768 Aug 28 2019 nsq_tail
-rwxr-xr-x. 1 root wheel 6068512 Aug 28 2019 nsq_to_file
-rwxr-xr-x. 1 root wheel 6007232 Aug 28 2019 nsq_to_http
-rwxr-xr-x. 1 root wheel 5986752 Aug 28 2019 nsq_to_nsq
-rwxr-xr-x. 1 root wheel 5724448 Aug 28 2019 to_nsq
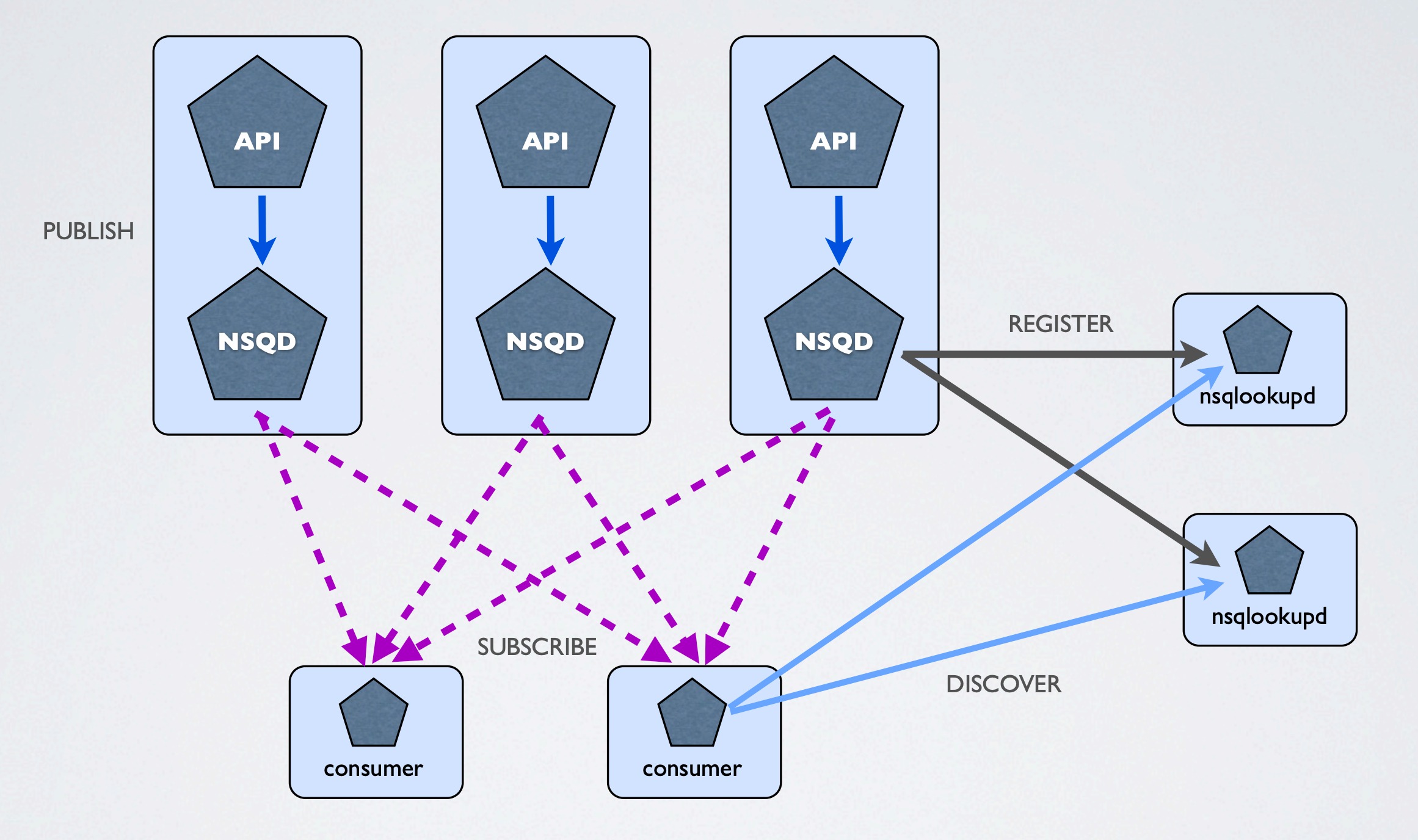
一个最简单的 nsq 环境由三部分组成:
- nsqlookupd 是管理拓扑信息的守护进程,客户端询问 nsqlookupd 来发现特定话题的 nsqd 生产者,nsqd 节点通过它广播话题和频道信息。
- nsqd 是接收、排队和将消息传达至客户端的守护进程,可以单独运行但是通常配合 nsqlookupd 形成集群。
- nsqadmin 是 NSQ 的 Web UI,用于实时查看集群的汇总数据并执行管理任务。
-
运行 nsqlookupd:
$ nsqlookupd -
运行 nsqd
$ nsqd --lookupd-tcp-address=127.0.0.1:4160 -
运行 nsqadmin
$ nsqadmin --lookupd-http-address=127.0.0.1:4161
也可以使用 shell 脚本部署(systemd 托管)
$ sh -c "$(curl -fssL https://gist.githubusercontent.com/crazytaxii/8f6e9dadc9e12ad0b51b30a9c156863d/raw/382bd139c91ce3c0bd46ab10713a6c11322ad348/nsq-depoy.sh)"
$ ps -ef | grep nsq
root 9477 1 0 02:38 ? 00:00:00 /usr/local/bin/nsqlookupd -tcp-address=127.0.0.1:4160 -http-address=127.0.0.1:4161
root 9508 1 0 02:38 ? 00:00:00 /usr/local/bin/nsqd -http-address=127.0.0.1:4151 -tcp-address=127.0.0.1:4150 -lookupd-tcp-address=127.0.0.1:4160
root 9540 1 0 02:38 ? 00:00:00 /usr/local/bin/nsqadmin --lookupd-http-address=127.0.0.1:4161
$ ss -ltnp | grep nsq
LISTEN 0 128 127.0.0.1:4150 *:* users:(("nsqd",pid=9508,fd=5))
LISTEN 0 128 127.0.0.1:4151 *:* users:(("nsqd",pid=9508,fd=6))
LISTEN 0 128 127.0.0.1:4160 *:* users:(("nsqlookupd",pid=9477,fd=3))
LISTEN 0 128 127.0.0.1:4161 *:* users:(("nsqlookupd",pid=9477,fd=4))
LISTEN 0 128 [::]:4171 [::]:* users:(("nsqadmin",pid=9540,fd=3))
性能
NSQ 是以分布式架构来设计的,固然单点性能很重要但是不代表 NSQ 集群能发挥的的最终性能。
我们可以使用官方提供的 benchmark 脚本来简单测试,这里我使用的虚拟机实例规格为 2C2G。
bench.sh 脚本会拉起一个新的 nsqd 实例,确保虚拟机上没有其他 nsq 相关进程在运行:
$ git clone https://github.com/nsqio/nsq.git
$ cd nsq
$ ./bench.sh
# using --mem-queue-size=1000000 --data-path= --size=200 --batch-size=200
# compiling/running nsqd
# creating topic/channel
# compiling bench_reader/bench_writer
PUB: [bench_writer] 2020/11/05 04:17:22 duration: 10.005876188s - 68.598mb/s - 359648.664ops/s - 2.780us/op
SUB: [bench_reader] 2020/11/05 04:17:32 duration: 10.0499149s - 62.558mb/s - 327985.165ops/s - 3.049us/op
waiting for pprof...
./bench.sh: line 19: kill: (16602) - No such process
本地测试下来单生产者单消费者吞吐量达到 60mb/s,ops 超过30W。
测试脚本会从 nsqd 内置的 pprof 服务获取 CPU 分析数据,即当前路径下的 cpu.pprof 文件,我们利用 go tool pprof 命令就可以查看与分析 nsqd 对 CPU 的使用情况:
$ go tool pprof cpu.pprof
File: nsqd
Type: cpu
Time: Nov 5, 2020 at 4:17am (EST)
Duration: 30s, Total samples = 12.51s (41.70%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
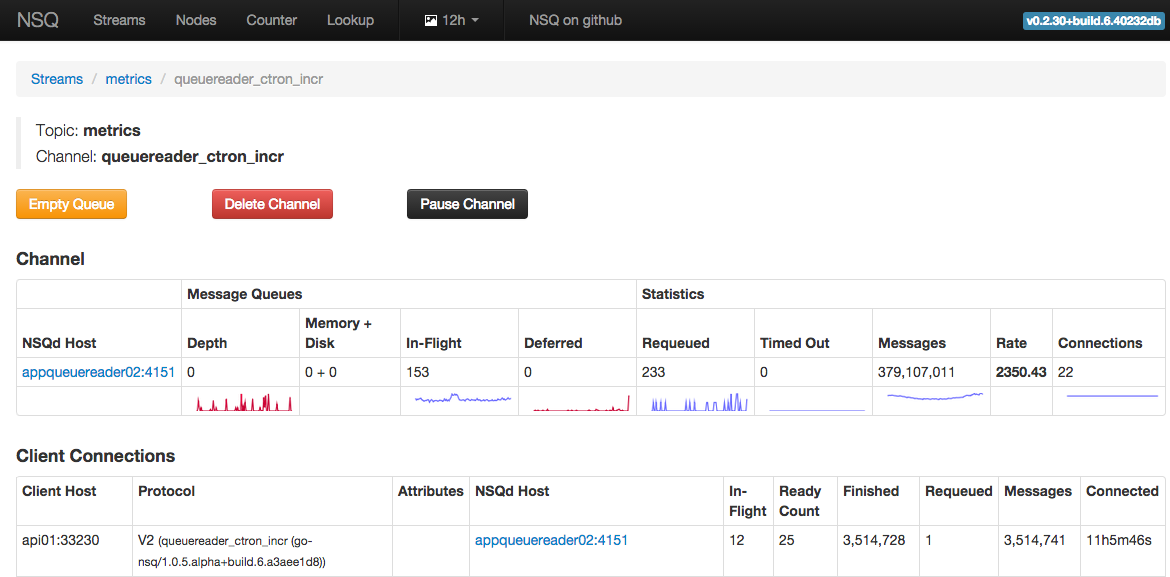
首先使用 topN 命令大概看一下最耗时间的操作:
(pprof) top10
Showing nodes accounting for 5550ms, 44.36% of 12510ms total
Dropped 174 nodes (cum <= 62.55ms)
Showing top 10 nodes out of 161
flat flat% sum% cum cum%
1260ms 10.07% 10.07% 3150ms 25.18% runtime.selectgo
1130ms 9.03% 19.10% 1170ms 9.35% syscall.Syscall
560ms 4.48% 23.58% 880ms 7.03% runtime.lock
530ms 4.24% 27.82% 530ms 4.24% runtime.unlock
430ms 3.44% 31.25% 440ms 3.52% time.now
420ms 3.36% 34.61% 420ms 3.36% runtime.procyield
410ms 3.28% 37.89% 1600ms 12.79% runtime.mallocgc
320ms 2.56% 40.45% 420ms 3.36% runtime.findObject
270ms 2.16% 42.61% 450ms 3.60% runtime.scanobject
220ms 1.76% 44.36% 220ms 1.76% runtime.nextFreeFast
select、系统调用和 GC 是消耗 CPU 时间的大头。
而分布式集群的基准测试可以使用官方提供的 bench/bench.py 脚本来完成,这里不多赘述。
为什么要使用队列?
因为所有东西都是不靠谱的!
传统的架构
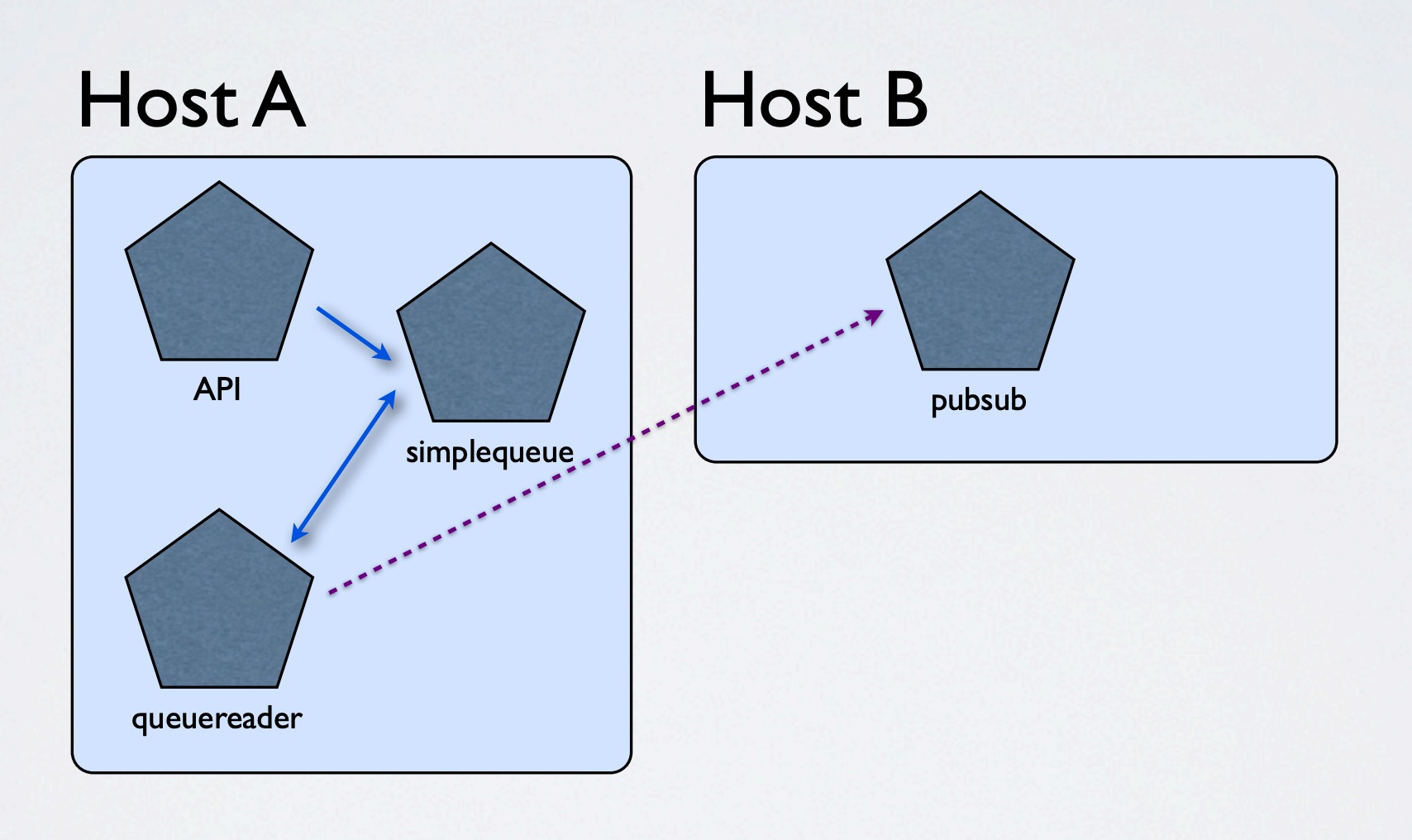
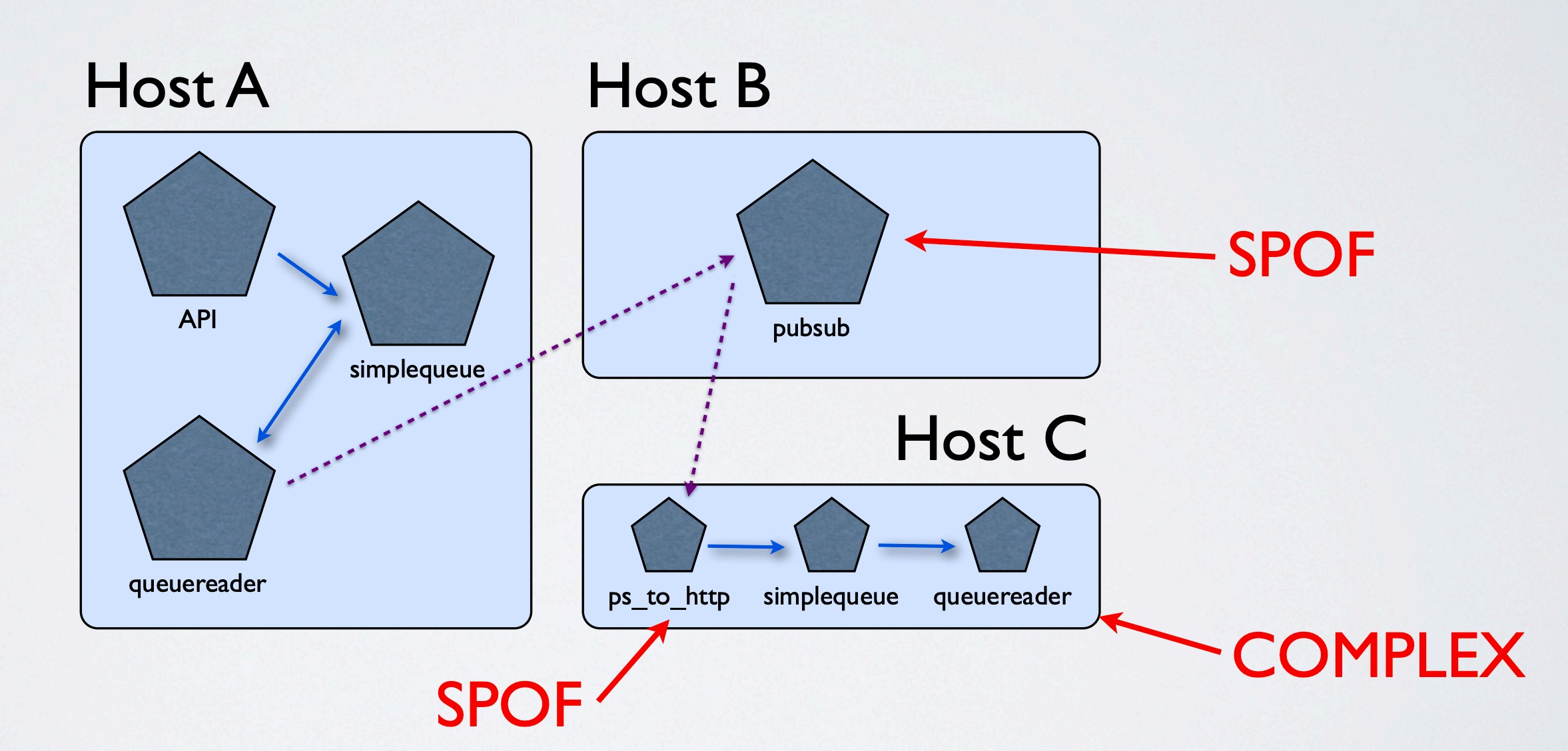
- 单点故障问题(重连、分布式、故障容忍等)
- 低效 - 多次复制数据流至多套系统
- 每条数据流都要重复复杂的服务配置
- 消费者写死队列地址
- 缺失内部性能计量
NSQ 设计理念
- 单个 nsqd 实例可以同时处理多条数据流,也叫做话题(topic)
- 一个话题有多个频道(channel)
- 消费者通过查询 nsqlookupd 来发现生产者
- 发布/订阅即创建话题和频道
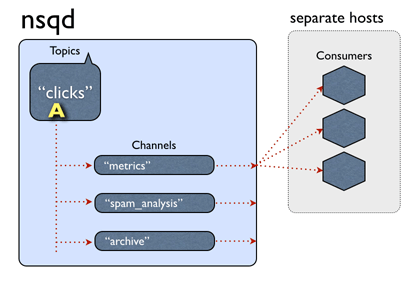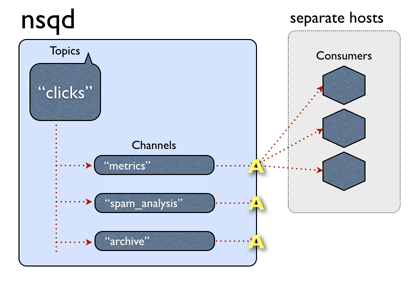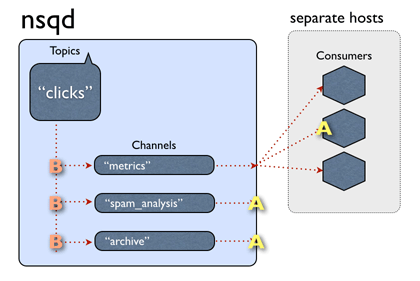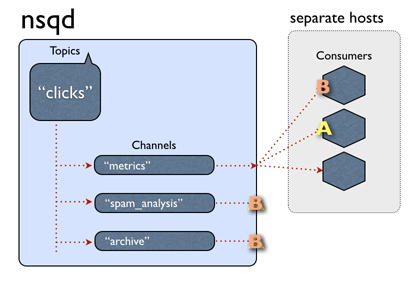
生产者与消费者无需提前知道对方:
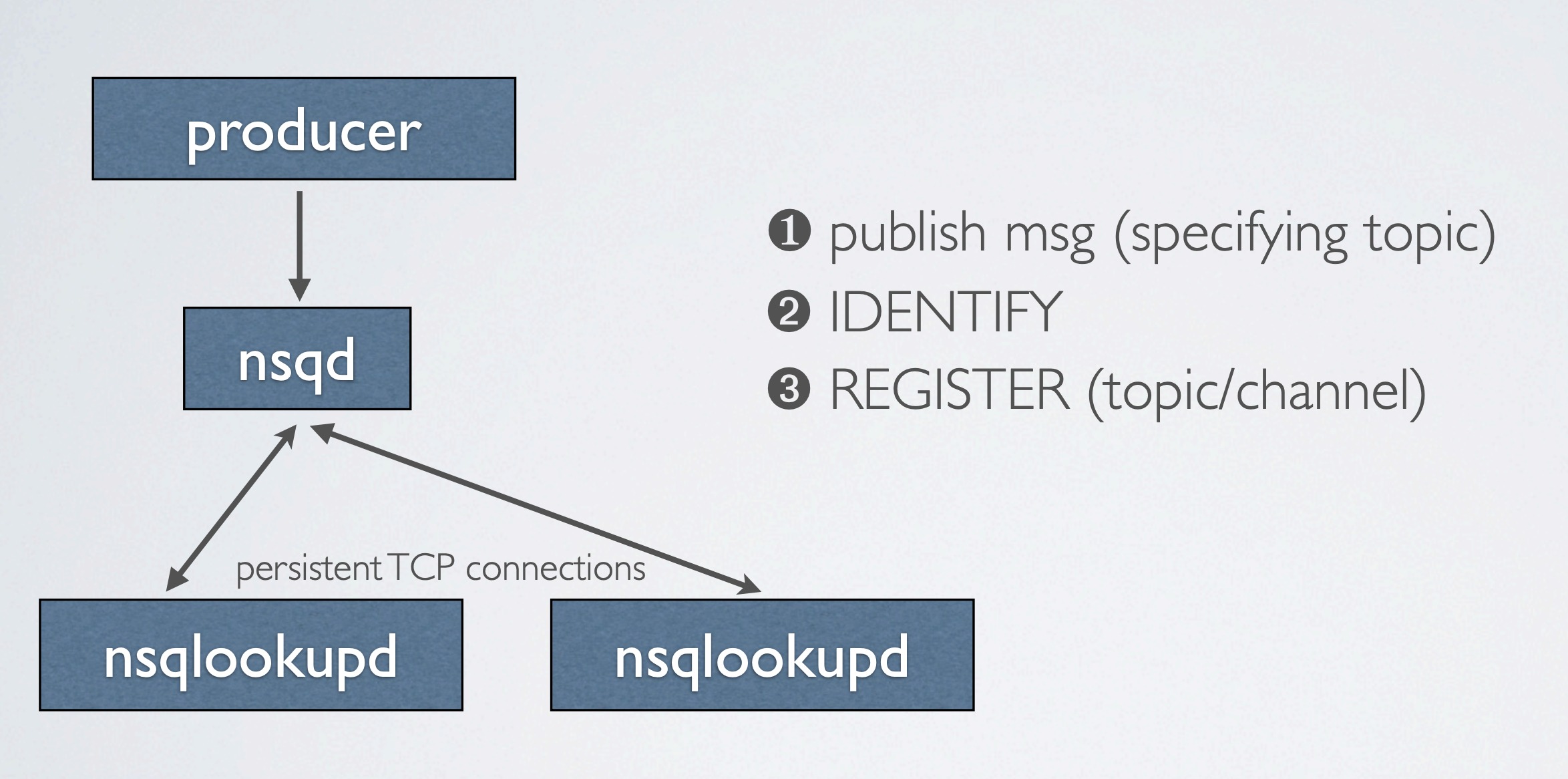
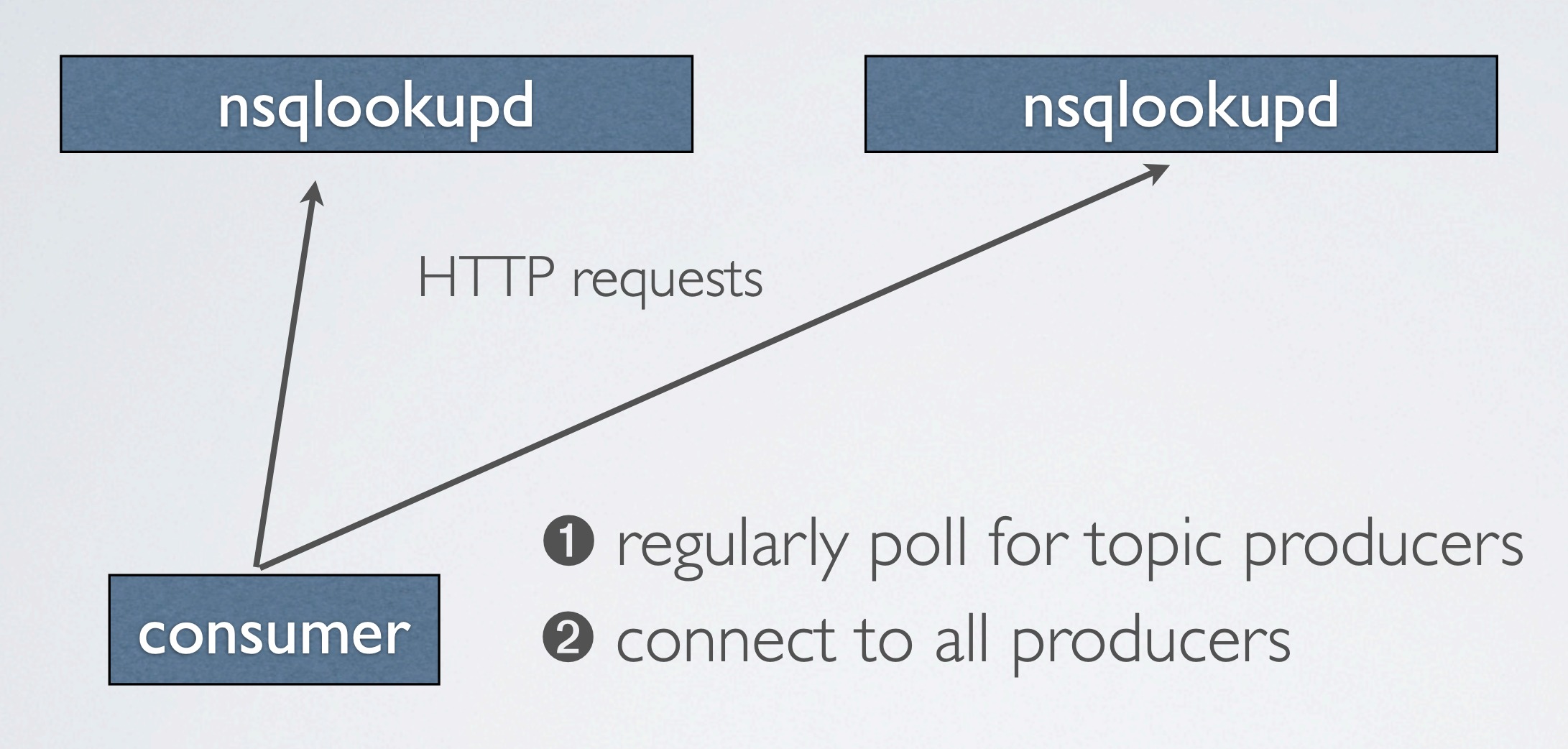
消除单点故障
- 分布式 & 去中心化
- 无中间人
- 消费者连接所有生产者
- 消息被推送至消费者
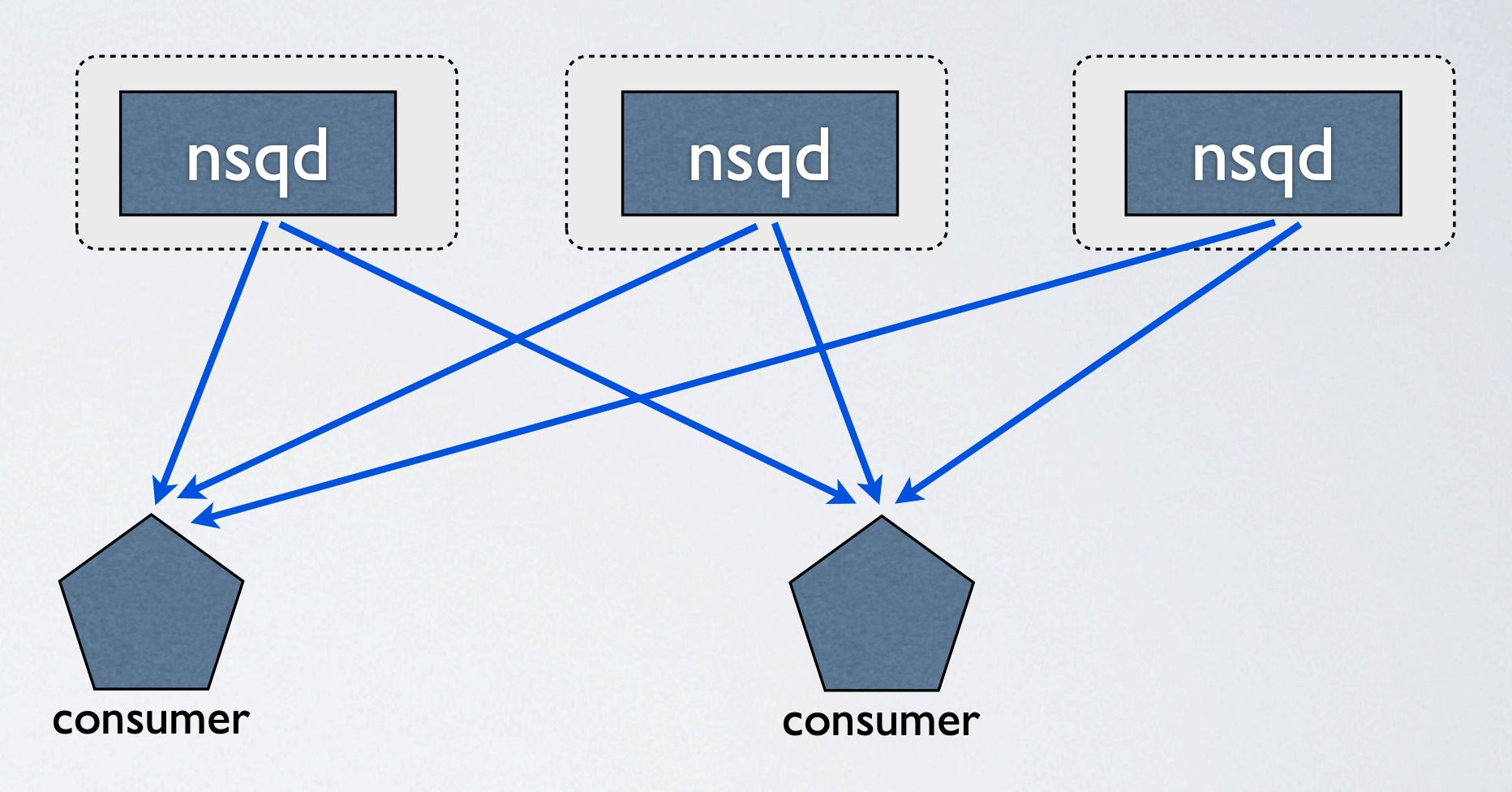
这种拓扑结构消除了单一的、聚合的投喂链。从技术上来讲,客户端连接到哪个 nsq 并不重要,只要有足够多的消费者,就能保证全都处理完。
消息传递保证
- 消息至少递交一次
- 由协议实现
- nsqd 发送消息并暂存
- 客户端回复 FIN(结束)或 REQ(重新入队)
- 如果客户端应答超时就自动重新入队
- 唯一会导致消息丢失的极端情况是 nsqd 进程退出,所有在内存中的消息都会丢失。
如果消息决不能丢,一种解决方案是在不同的主机上搭建冗余的 nsqd 对,同时接收相同的消息。
效率
NSQ 使用类 memcached 的命令协议。包括尝试次数、时间戳等元数据的所有消息数据都保存在核心中。客户端也简化了,不需要维护消息状态。
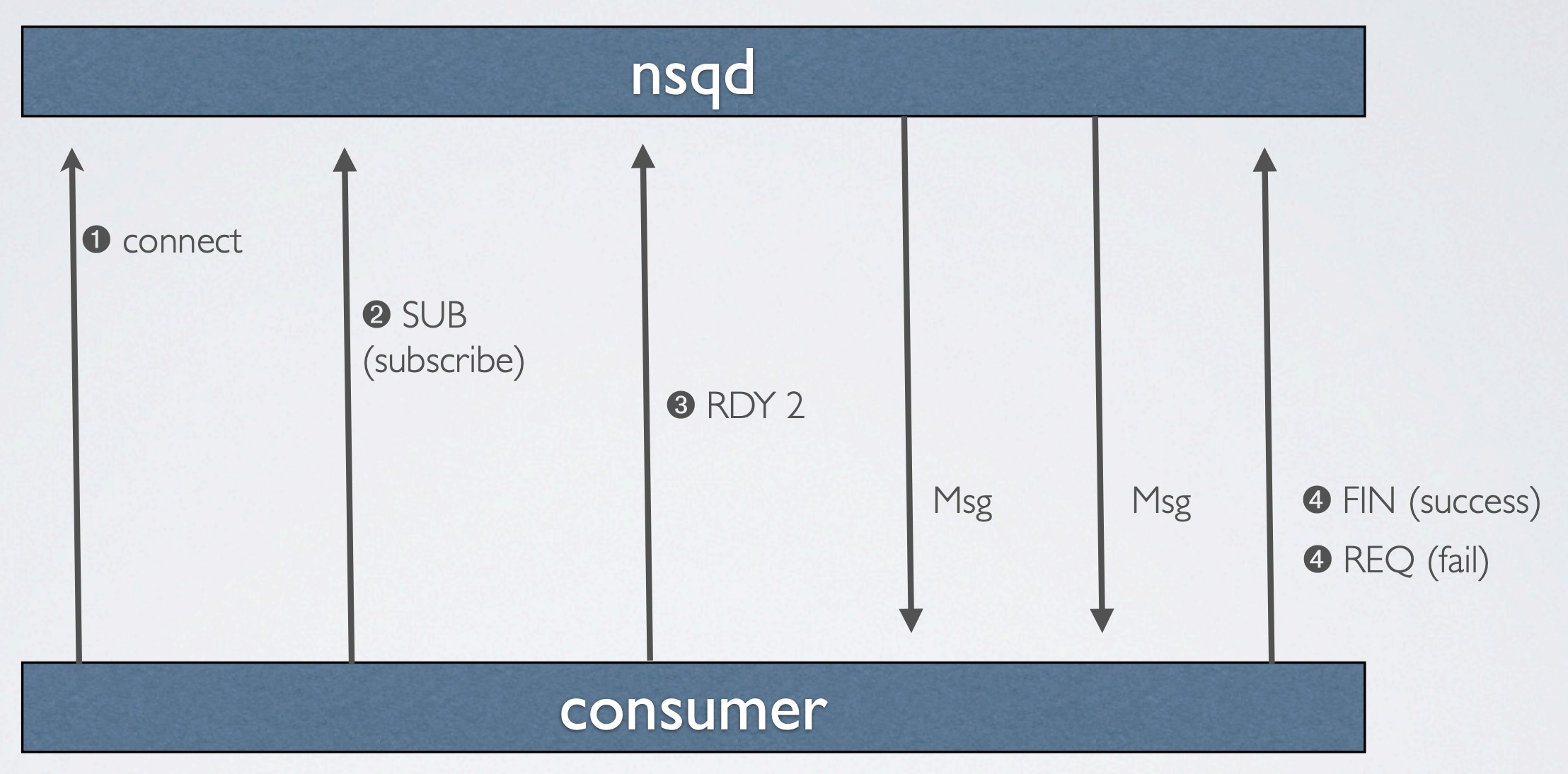
有个非常关键的设计,向客户端推送数据而不是等待数据拉取,从而最大限度地提高性能和吞吐量。这个概念,称之为 RDY 状态,本质上是一种客户端流控。
当一个客户端连接到 nsqd 并订阅一个频道时,RDY 状态被置 0,代表没有消息将被发送到客户端。当客户端准备好接收消息时,发送一个命令将它的 RDY 状态更新至准备好处理的消息数,比如 100,那么 100 条消息将在它们可用时推送给客户端(每次递减该客户端在服务器端的 RDY 计数)
客户端的库被设计成当 RDY 状态达到 max-in-flight 设置项的 25% 左右时,发送命令更新 RDY 计数。
队列
- 话题(topic)和频道(channel)是独立的队列
- 当队列(内存)中的消息数量超过水位线将写盘,意外重启后部分消息会保留下来
- 优雅关闭(向 nsqd 进程发送 TERM 信号)则能够将当前状态保存下来
- 也就 10 行 Go 代码
for {
select {
case msg := <-c.memoryMsgChan:
err := writeMessageToBackend(&msgBuf, msg, c.backend)
if err != nil {
c.ctx.nsqd.logf(LOG_ERROR, "failed to write message to backend - %s", err)
}
default:
goto finish
}
}
NSQ 集群架构