零增长栈带来的收益:Go 中的栈分配如何节省 10% CPU
Jun 26, 2026 00:00 · 3433 words · 7 minute read
原文 Zero-Growth Stack, Real Gains: How Stack Allocation Can Save 10% CPU in Go
介绍
Uber 约有 65% 的服务运行在 Go 之上,消耗超过 200 万个 CPU 核心。以当前的规模来看,即使 1% 的效率提升,也能节省几百万美元的成本。本文将介绍:我们如何将某个服务的资源利用率提升约 10%,以及如何把这套方法应用到更多服务上。
Go runtime 采用了多种机制来降低内存资源占用;但在超大规模场景下,这类权衡有时会把成本转嫁到 CPU 上。一个典型机制就是栈内存扩容:goroutine 会从很小的初始栈开始,以支持远高于操作系统线程的并发度;一旦执行路径超出预分配空间,runtime 就会触发扩容。若这一过程频繁发生,就会浪费大量 CPU。因此,尽量避免反复扩栈,在启动时预分配更合适的栈大小,是很有必要的。
深入分析
Go 是 Uber 使用最广泛的编程语言。Go 拥有自己的 runtime,以 goroutine 替代传统线程,可以将其理解为一种更轻量的线程抽象。两者一个关键差异在于对栈空间的使用方式。
以 pthread_create 为例,一个操作系统线程默认使用 2MB 栈空间;如果 RLIMIT_STACK 被配置为 unlimited,则随架构而定:大多数架构为 2MB,POWER 和 Sparc-64 为 4MB。相比之下 Go 的 goroutine 默认初始栈只有 2KB。
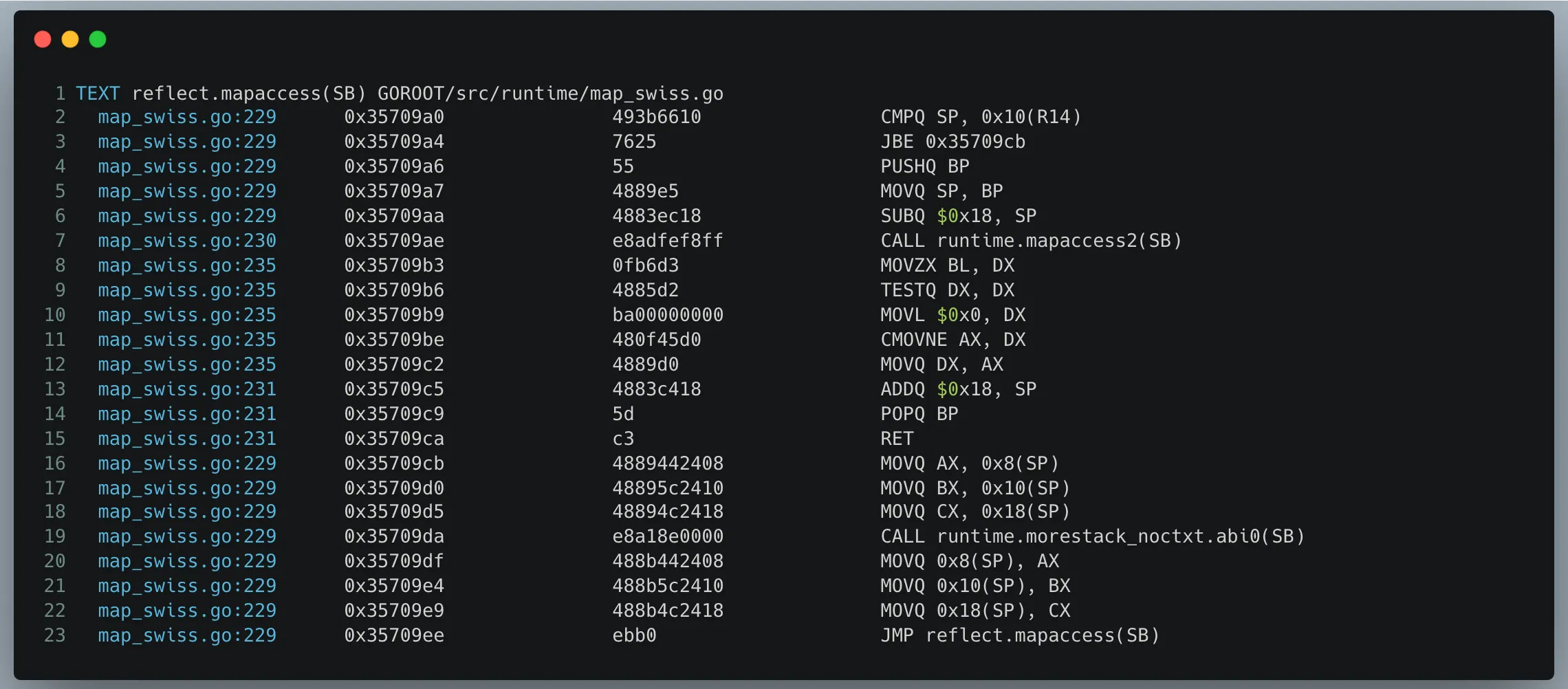
如果 2KB 不够用,Go 会在函数执行前插入一段专门的检查逻辑,用于判断当前调用是否可能导致栈溢出。一旦空间不足,runtime 就会分配一个两倍大小的新栈,并把旧栈内容拷贝过去。如图 1,第二行会比较当前栈指针;如果已经越过阈值,就会跳转调用 runtime.morestack,触发扩栈。
go1.19 引入了自适应栈特性,会持续追踪运行过程中的平均栈大小,并据此动态调整 goroutine 的起始栈大小。这一优化在一定程度上缓解了问题,因为 goroutine 不再总是从最小值起步;但对某些应用而言,扩栈本身依旧可能非常昂贵。
那么,我们还有哪些选择?
方案一:goroutine 池化
Uber 内部其他团队过去已经使用过该方案。M3 团队通过维护 goroutine 池,向其发送 worker 降低 CPU 使用率。这个方案之所以对他们有效,是因为其 worker pool 的职责单一、边界清晰。
该方案的缺点在于:需要改动代码,这会略微增加复杂度、耗费时间,并且要求开发者对目标应用有充分认知。此外,channel 通信本身也有开销,而池子大小是静态的——高负载下,到底是阻塞还是丢弃?
方案二:定制 runtime
我们挖一下 Go 源码。平均起始栈大小的实现方式如图 2 所示。
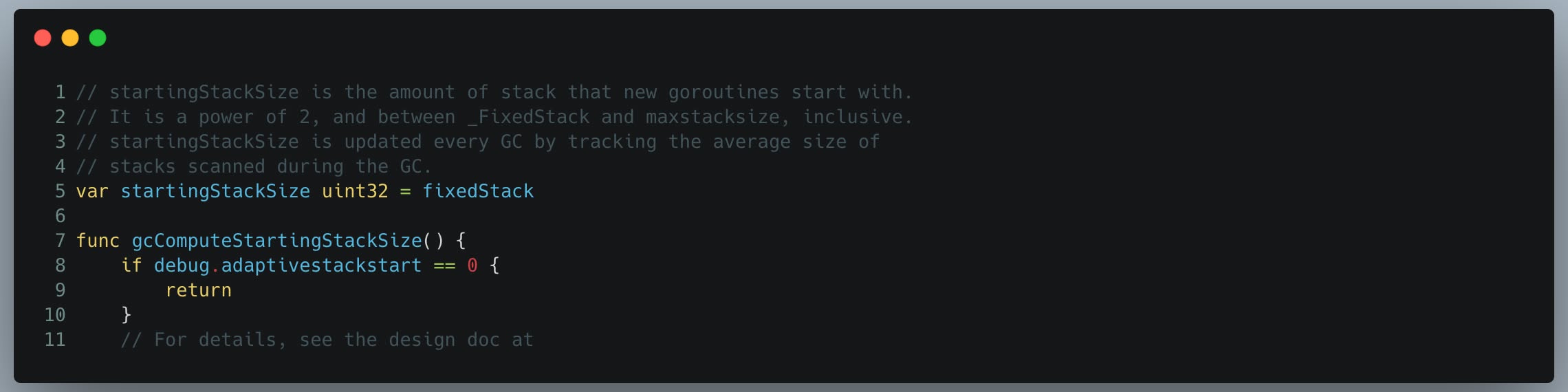
有个方法计算该值并存入 startingStackSize。此外,还可以通过 debug.adaptivestackstart 禁用该方法。
到这里,我们有两条路:要么为 runtime 增加公开方法,要么利用 private linking 暴露私有符号。在 Uber 的案例中,我们最终选择了 private linking,因为它对 runtime 的侵入最小。
首先,我们需要给 runtime 打补丁,使 debug 和 startingStackSize 这两个全局变量能够被 private linking。之所以必须这么做,是因为自 go1.23 起,linkname 要求明确的 contract,而这两处在官方源码中都没有声明对应的契约。
然后,我们在内部模块中创建公开方法用于修改这些变量。
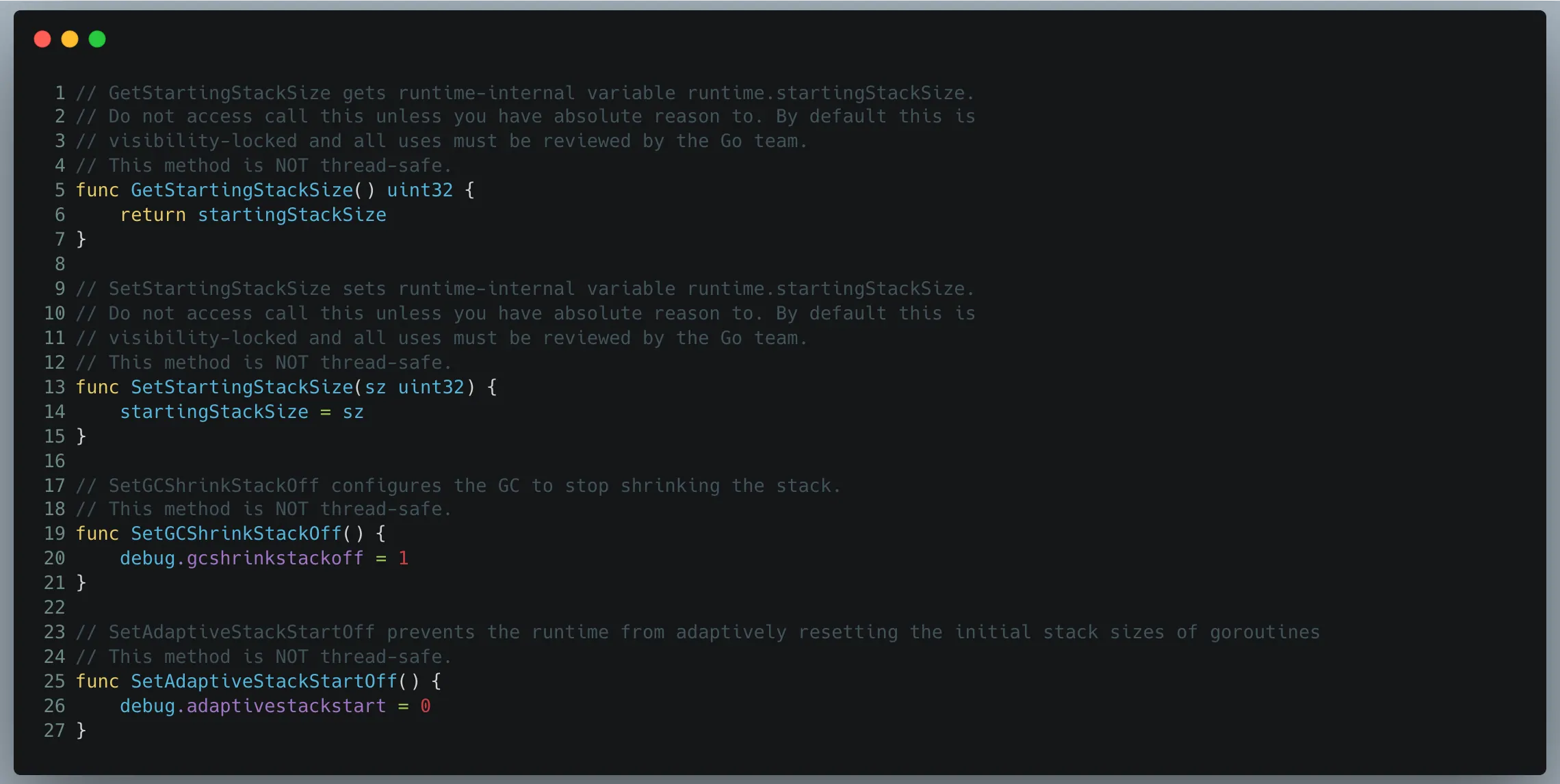
我们需要借助 debug 变量禁用自适应栈机制,避免 runtime 覆盖我们的修改。同时,我们也关闭了栈收缩,因为这一过程本身也会带来额外的 CPU 开销。
为了简化调优,我们决定采用静态值,将 runtime 影响降到最低。应用一启动就立刻修改 startingStackSize。再通过内部的可配置系统,按不同场景注入不同的栈大小,从而支持按 runtime_environment、zone、region 等维度进行测试。
这一方案的唯一缺点是 Go 社区未来可能改变平均栈大小的内部实现,届时我们的代码就会失效。为降低未来升级时的崩溃风险,我们使用了 build tag。当前版本的代码已经暴露了修改 runtime 的方法,但同时我们会为下一个 Go 版本创建了一个带空实现的样板文件;每次升级 Go 时,都需要重新检查私有结构,确认 debug 未被改动、startingStackSize 仍然存在。
生产实践
我们某个核心服务的 profile 显示,大约有 10% 的 CPU 消耗在栈扩容上。
栈内存占用很低,如图 5 所示。
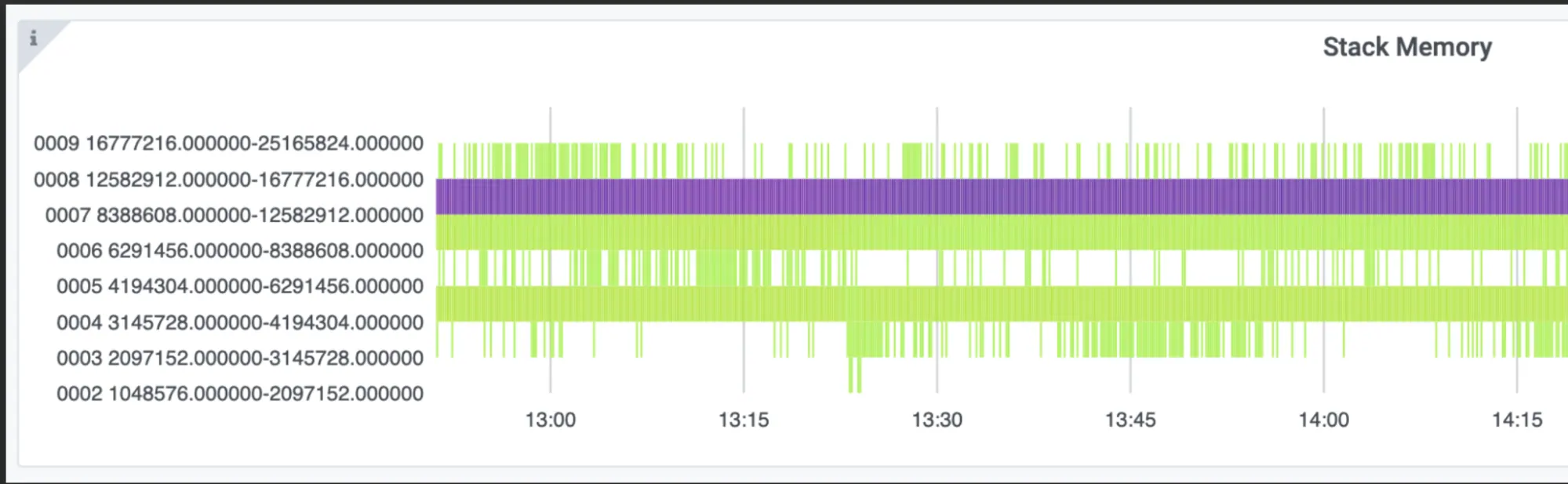
大多数实例都落在 12MB 到 16MB 的区间,而每个容器拥有 16GB 内存,也就是说它其实有充足的增长空间。
我们知道能用内存来减少 CPU 使用率,于是我们研究了不同的方法来确定到底应该为每个 goroutine 预分配多大的栈。
方法一:纯手工调参
第一种方法是先把起始栈从 2KB 开始调到 4KB,部署上线,观察 profile;如果 copystack 仍然很高,就继续调到 8KB,如此反复。
显然,这种方法无法规模化应用到大量服务。更糟的是,如果某个服务的平均栈需求本来就显著高于 4KB,还会适得其反。
方法二:通过指标手工调参
第二种方法与第一种思路相同,但会在服务中补充监控埋点,持续上报当前平均起始栈大小,为调参提供参考。如果当前平均值已经达到 4KB,而 profile 里仍然能看到 copystack,那么我们就可以直接提高到 8KB,减少试错轮次。
这比完全盲调更好,但工作量依然很大,因为每次调整都要等待部署完成。
方法三:从运行时直接读取
先不说在运行时获取当前栈大小的具体细节(借助 cgo 或 private linking 即可实现),但这套方案实际上并不可行。原因在于它不仅会引入额外的性能开销,而且要求我们必须明确在哪个位置调用它是正确的(即必须搞清楚到底是哪一个方法触发了 copystack)。
方法四:基于 profiler 的自动分析
回到图 4,profiler 实际上已经提供了我们想要的信息。任何最终走到该 block 的栈轨迹(stack trace),正是我们要重点分析其大小的对象。关键问题在于:我们如何使这一过程自动化?如何在不引入额外的 runtime 插桩的前提下实现这一点?
图 6 展示了基于 profile 引导(profile-guided)的栈大小调优的整体工作流。
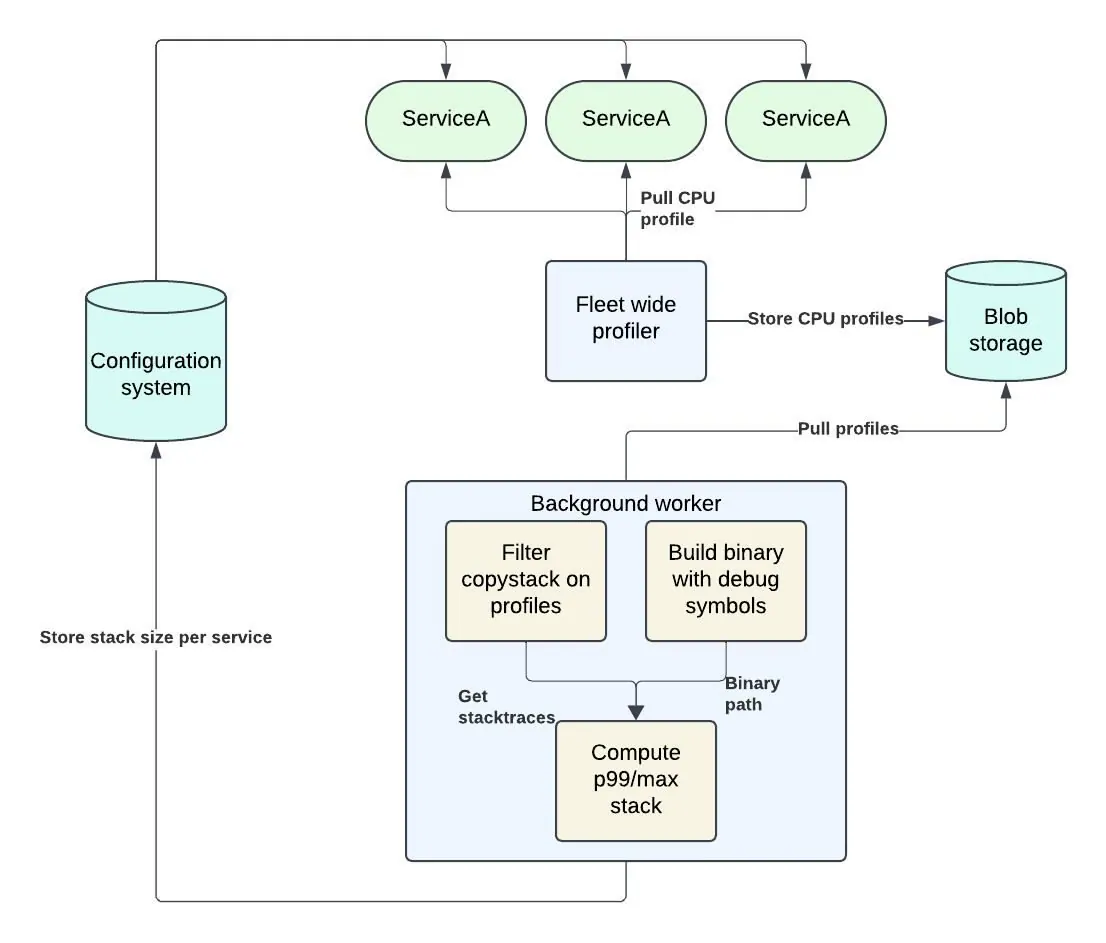
我们使用 pprof 库读取栈轨迹。拿到 profile 之后,我们首先过滤掉所有未进入 copystack 函数的栈轨迹。随后程序需要能够计算出特定函数到底消耗了多少栈空间。这有两种实现选项:
- go tool objdump
:实现简单,但速度慢且集成度低(需要额外调用子进程,并确保运行环境中存在 Go 二进制文件)。 - 创建自定义的汇编读取器(assembly reader):这更契合最终的生产级方案。我们利用一个反汇编二进制文件的库来实现。
首要前提在于:必须确保在构建 Go 程序时保留 debug symbols,并且可以在 Go 代码层面读取这些符号。
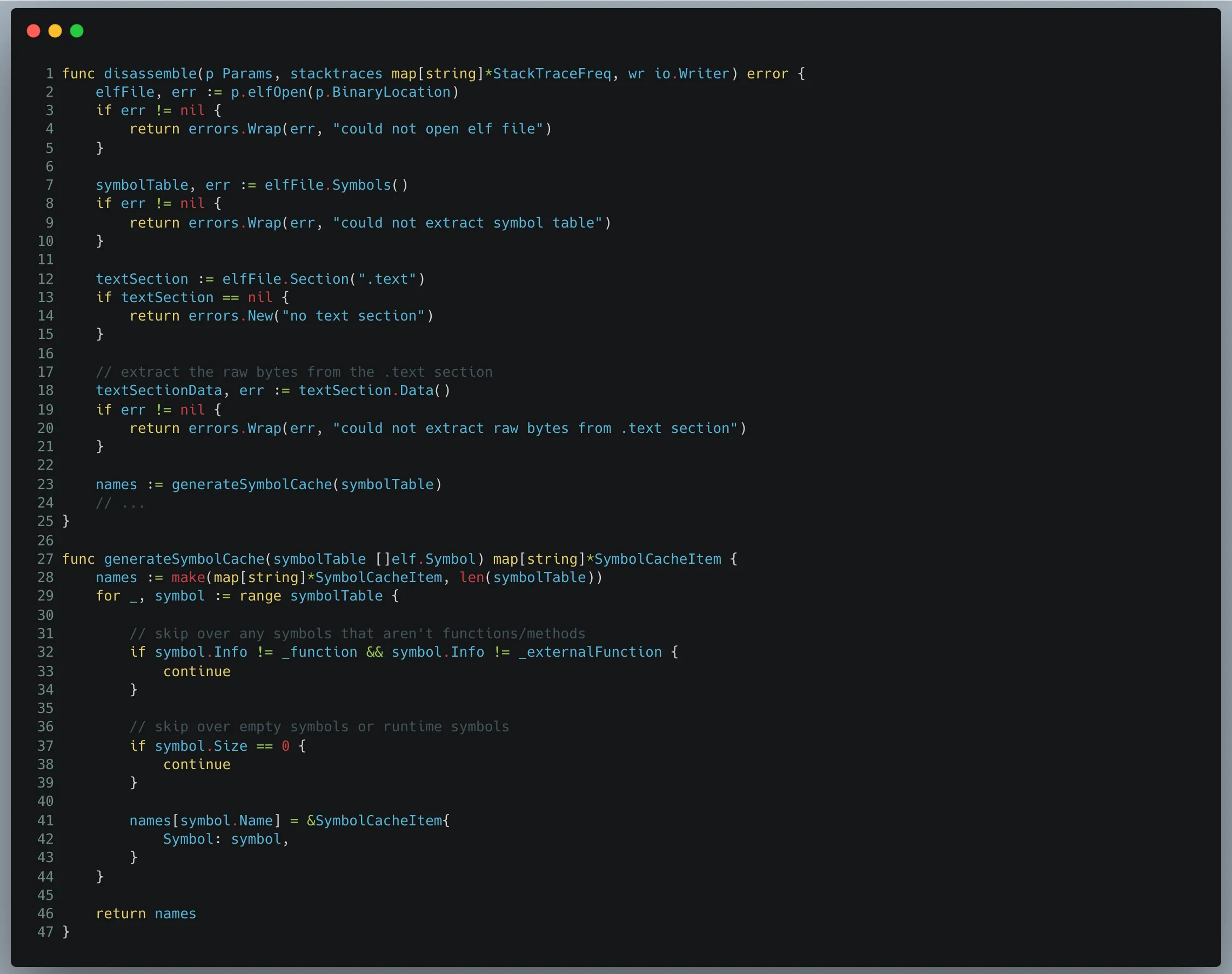
然后我们需要遍历刚才由 pprof 库计算出的栈轨迹图,逐个函数提取其栈空间使用量。
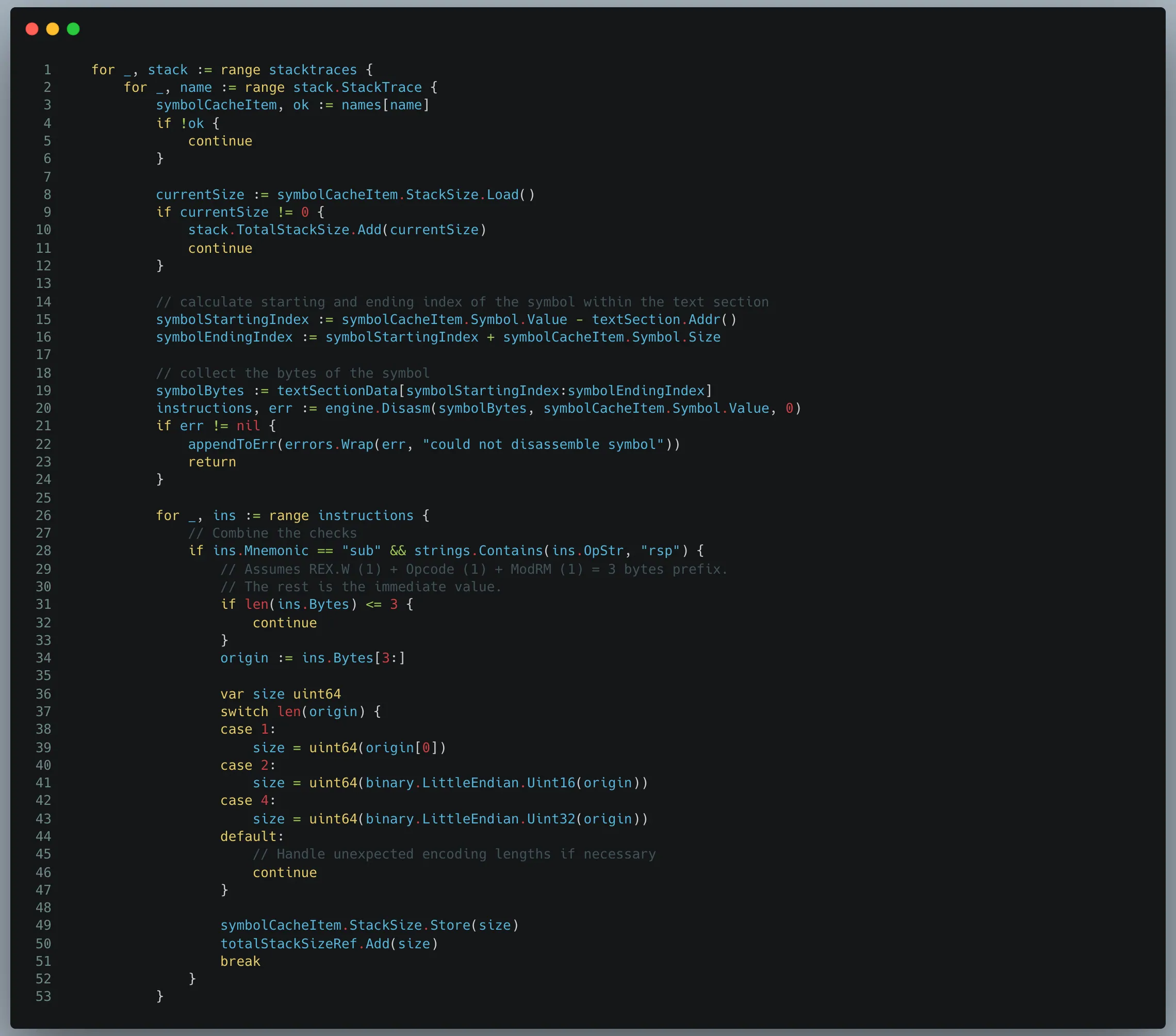
在图 9 展示的代码中,我们会遍历每个函数的对应汇编指令,在第一次遇到 sub 指令的地方,实际上也就是说明为该函数预留相关所需栈内存的指令位置。接下来,我们只需从该指令的剩余字节中提取进而获得具体的预留大小即可。

最终栈分析器会打印出所有的栈轨迹及其栈总使用量,并按使用量进行降序排列。当我们分析位于最顶部的最高栈开销轨迹时,发现大约消耗了 19KB,但由于设置栈大小时必须满足 2 的幂,因此最终正确的取值应当为 32KB。
此外,该分析器还能就每个特定函数提供很多有用的分析信息。例如,我们发现 go.uber.org/yarpc/internal/observability.(*Middleware).Call 高达 2.6KB 的栈内存消耗。鉴于这本身是一个 middleware,意味着每个请求都会调用它。因此我们对其进行优化以降低开销。这部分更改已同步至 GitHub,最终我们将其栈用量降低到了 600 字节。
生产效果
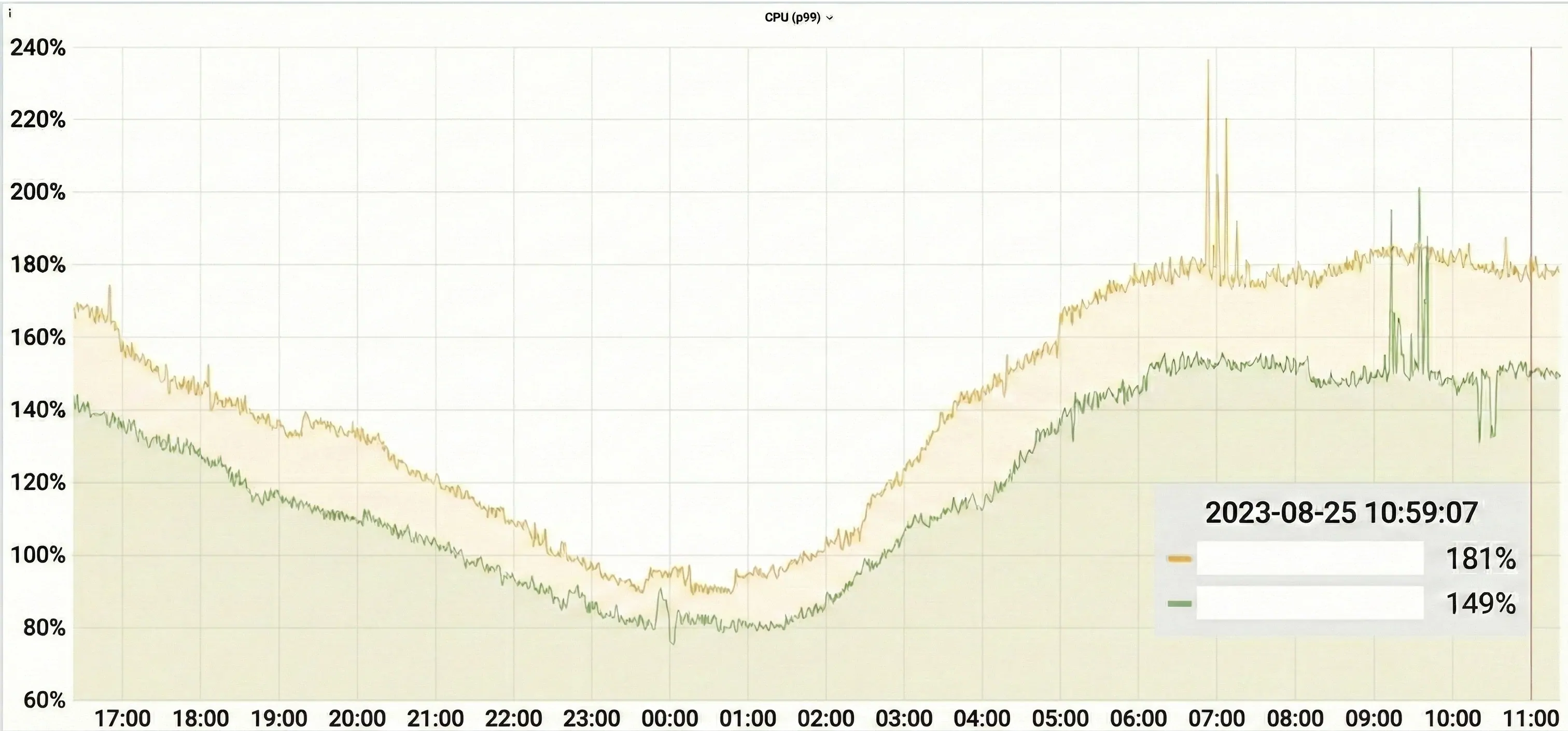
最初,这项开销对服务 CPU 的影响接近 10%。

在将起始栈大小从 2KB 提升至 32KB 并部署上线后,这部分 CPU 占用率降至了不到 1%。

大多数实例的栈内使用量在 50MB 左右,少数实例达到了 200MB。容器本身拥有 16GB 的内存,200MB 的额外开销占比还不到 2%。

这对 CPU 影响非常显著:\(1 - (150/180) \approx 16\%\)
下一步
我们计划继续将更多服务接入到这套方案中。由于识别正确的栈大小耗时较长,我们需要将这一流程自动化,以筛选出最佳候选服务。需要重点关注的信号包括:
- 栈扩容带来的高 CPU 消耗
- 栈内存使用量相对较低,或者有充足的内存空间支撑扩容所需
此外,我们还可以继续利用该分析器来优化自身消耗大量栈空间的热点函数(hot functions)。
总结
通常 Go 独特的栈扩容机制能够在低内存占用与 CPU 高性能之间取得理想的平衡。然而,在 Uber 这样的量级下,即便是 1% 的效率提升也意味着节约数百万美元,因此即使是经过高度优化的 runtime,依然能从专门的深度调优中获益。尽管我们当前的方案仍需要对 runtime 进行内部改动,但其带来的显著性能增益充分说明:在官方原生解决方案出台之前,这些工程投入是物超所值的。
相关 Issue: #77893